Знания — это результат обучения через неразрывное сочетание теории и практики. Это то, что осталось в нашем опыте от всех данных, которые превратились в то, что мы называем информацией. Этот процесс можно наблюдать на разных этапах нашей жизни, и он никогда не ограничивается академическим путешествием.

Я хочу показать, что машинное обучение — это не что иное, как человеческая логика, адаптированная для более сложных задач, которые, безусловно, требуют больше вычислительных возможностей.
Существует множество различных типов обучения и подходов к обучению. Чтобы учиться эффективно, важно адаптировать свои учебные привычки к вашим собственным потребностям и подходу, это часто означает выбор методов, которые работают для вас, и время от времени их оценка, чтобы определить, нужно ли вам попробовать что-то новое. — Университет Британской Колумбии —
Последняя цитата представляет собой процесс приобретения знаний о природе, который, как вы могли заметить, похож на методологию CRISP-DM, которую я подробно описал в предыдущей статье и которая очень важна. чтобы преуспеть в вашем проекте интеллектуального анализа данных.

___________________________________________________________________
— — — — —Что такое машинное обучение — — — — — — — —
Чтобы определить машинное обучение, это набор алгоритмов, которые включены во многие операции, такие как процесс интеллектуального анализа данных, и которые помогают вам преобразовать необработанные данные в знания, уровень что скрывается под очевидной информацией.
Эти алгоритмы помогают ответить на два основных вопроса:
- Как извлечь информацию, если я не знаю, чего ожидать? (Открытие) –› Обучение без присмотра
- Как я могу предсказать класс или ценность элемента/индивида, который у меня есть, на основе извлеченных данных? -› Контролируемое обучение
___________________________________________________________________
___________________________________________________________________
— — — — — Обучение без присмотра — — — — — —
Неконтролируемые алгоритмы помогают вам узнать что-то, используя информацию, которая не классифицирована и не помечена.
Основным алгоритмом, который используется для этой категории, является Кластеризация.
Кластер – это группа объектов, которые похожи на другие объекты в кластере и отличаются от точек данных в других кластерах.
Каковы некоторые варианты использования алгоритмов этого типа?
- В сфере розничной торговли кластеризация используется для поиска связей между клиентами на основе их демографических характеристик и использования этой информации для определения покупательских моделей различных групп клиентов. Кроме того, его можно использовать в системах рекомендаций, чтобы найти группу похожих товаров или похожих пользователей и использовать его для совместной фильтрации, чтобы рекомендовать покупателям такие вещи, как книги или фильмы.
- Банковское дело: аналитики находят группы обычных транзакций, чтобы выявить закономерности мошеннического использования кредитных карт. Кроме того, они используют кластеризацию для идентификации кластеров клиентов, например, для поиска лояльных клиентов, а не для оттока клиентов.
- В страховой отрасли: кластеризация используется для обнаружения мошенничества при анализе требований или для оценки страхового риска определенных клиентов на основе их сегментов.
- В печатных СМИ. Кластеризация используется для автоматической категоризации новостей на основе их содержания или для пометки новостей, а затем их группировки, чтобы рекомендовать читателям похожие новостные статьи.
- В медицине. Его можно использовать для характеристики поведения пациентов на основе их схожих характеристик, чтобы определить успешные медицинские методы лечения различных заболеваний.
- в биологии:кластеризация используется для группировки генов с похожими паттернами экспрессии или для кластеризации генетических маркеров для выявления семейных связей.
___________________________________________________________________
— — — — —Некоторые алгоритмы кластеризации — — — — — —
Существует множество алгоритмов кластеризации, и они, безусловно, служат как сходным, так и различным целям. Использование зависит главным образом от цели и объема данных, которые будут обрабатываться. Ниже приведены некоторые типы алгоритмов, связанных с этой операцией:
- Кластеризация на основе секционирования. Используется для наборов данных большого или среднего размера и относительно эффективна. Например: K-средние, K-медианные, нечеткие, c-средние
- Иерархическая кластеризация. Используется для небольших наборов данных и создает деревья кластеров. Например: агломеративный, разделительный
- Кластеризация на основе плотности. Используется для пространственных кластеров или когда в наборе данных есть шум и создаются кластеры произвольной формы. Например: DBSCAN
Для этой статьи я выбрал K-средние, иерархическую кластеризацию и DBSCAN.
___________________________________________________________________
— — — — — — — — — K-средние значения — — — — — — — — — —
В этом алгоритме мы устанавливаем K как количество искомых кластеров и используем расстояния между точками объекта.
- Внутрикластерные расстояния сведены к минимуму
- Межкластерные расстояния максимальны

Каковы его шаги:
1- Произвольная инициализация K центроидов
2- Мы рассчитываем расстояние каждой точки данных от точек центроидов
3- Назначить каждую точку ближайшему центроиду (используя метрику расстояния)
- Центроид выбирается случайным образом => ошибка: сумма квадратов расстояний между точками и центроидом
- Чтобы было меньше ошибок:
4- Назначить новые центроиды каждому кластеру (среднее значение для точек данных в каждом кластере).
5- Повторяйте до тех пор, пока изменений не будет.
Чтобы рассчитать точность, мы используем два подхода:
- Внешний подход: сравните кластеры с достоверными данными, если они доступны.
- Внутренний подход: усреднение расстояния между точками данных в кластере.
В чем проблема при выборе k ?
По сути, определение количества кластеров в наборе данных, или k, как в алгоритме k-средних, является частой проблемой при кластеризации данных. Правильный выбор k часто неоднозначен, потому что он очень зависит от формы и масштаба распределения точек в наборе данных. Существует несколько подходов к решению этой проблемы, но один из наиболее часто используемых методов заключается в выполнении кластеризации по различным значениям K и просмотре метрики точности для кластеризации. Этой метрикой может быть «среднее расстояние между точками данных и их центроидом кластера», которая показывает, насколько плотны наши кластеры или насколько мы минимизировали ошибку кластеризации. Затем, глядя на изменение этой метрики, мы можем найти наилучшее значение для k. Но проблема в том, что с увеличением количества кластеров расстояние от центроидов до точек данных всегда будет уменьшаться. Это означает, что увеличение K всегда будет уменьшать «ошибку». Итак, строится значение показателя в зависимости от К и определяется «точка локтя», куда резко смещается скорость убывания. Это правильный K для кластеризации. Этот метод называется методом «локтя».
___________________________________________________________________
— — Агломеративная иерархическая кластеризация (AHC) —
Алгоритмы иерархической кластеризации создают иерархию кластеров, в которой каждый узел представляет собой кластер, состоящий из кластеров его дочерних узлов.
Каковы его шаги?
1-Создайте n кластеров, по одному для каждой точки данных.
2-Вычисление матрицы близости
3- Повторите:
- объединить два ближайших кластера
- Обновить матрицу близости
4-Пока не останется только один кластер

Какие расстояния используются для выбора кластеров для их объединения?
- Кластеризация с одной связью (минимальное расстояние между кластерами)
- Кластеризация с полной связью (максимальное расстояние между кластерами)
- Средняя кластеризация связей (среднее расстояние между кластерами)
- Кластеризация центроидной связи (расстояние между центроидами кластеров)
Преимущества:
- Он создает дендрограмму, которая помогает лучше понять данные.
- Это легко реализовать
Недостатки:
- Как правило, он имеет длительное время работы
- Иногда бывает сложно определить количество кластеров по дендрограмме
___________________________________________________________________
— — — DBSCAN (кластеризация на основе плотности) — — — —
Почему мы его используем и в чем разница между K-Means и кластеризацией на основе плотности с точки зрения обнаружения аномалий:
Хотя алгоритмы на основе разбиения, такие как K-Means, могут быть просты для понимания и реализации на практике, алгоритм не имеет понятия о выбросах. То есть все точки относятся к кластеру, даже если они не принадлежат ни к одному. В области обнаружения аномалий это вызывает проблемы, поскольку аномальные точки будут отнесены к тому же кластеру, что и «нормальные» точки данных. Аномальные точки притягивают центроид скопления к себе, что затрудняет классификацию их как аномальных точек. Напротив, кластеризация на основе плотности находит области с высокой плотностью, которые отделены друг от друга областями с низкой плотностью. Плотность в данном контексте определяется как количество точек в пределах заданного радиуса. Специфическим и очень популярным типом кластеризации на основе плотности является DBSCAN. DBSCAN особенно эффективен для таких задач, как идентификация классов в пространственном контексте. Замечательным свойством алгоритма DBSCAN является то, что он может обнаружить любой кластер произвольной формы, не подвергаясь влиянию шума.
Используется для поиска произвольных кластеров (кластеров внутри кластеров).

Что это такое и как это работает?
DBSCAN расшифровывается как Пространственная кластеризация приложений на основе плотности с шумом. Этот метод является одним из наиболее распространенных алгоритмов кластеризации, который работает на основе плотности объекта.
DBSCAN работает по идее, что если конкретная точка принадлежит кластеру, она должна быть рядом с множеством других точек в этом кластере.
Он работает на основе 2 параметров:
- Радиус и минимальные точки. R определяет указанный радиус, который, если он включает в себя достаточное количество точек, называется «плотной областью».
- M определяет минимальное количество точек данных, которые мы хотим в окрестности, чтобы определить кластер.
Что такое ключевой момент? Точка данных является базовой точкой, если в R-окрестности точки есть не менее M точек. Например, поскольку в 2-сантиметровом соседе красной точки есть 6 точек, мы помечаем эту точку как основную точку.
Что такое пограничный пункт? Точка данных является точкой ГРАНИЦЫ, если:
а. Его окрестности содержат менее M точек данных
OR
б. Он достижим из некоторой центральной точки.
Что такое выброс? Выброс – это точка, которая: не является основной точкой, а также не находится достаточно близко, чтобы до нее можно было добраться из основной точки.
Последний шаг — соединить основные точки, которые являются соседями, и поместить их в один и тот же кластер. Итак, кластер формируется как минимум одна основная точка плюс все достижимые основные точки плюс все их границы. Он просто формирует все кластеры, а также находит выбросы.
___________________________________________________________________
___________________________________________________________________
— — — — — — Обучение под наблюдением — — — — — —
«Обучение с учителем — это когда у вас есть входные переменные (x) и выходная переменная (Y), и вы используете алгоритм для изучения функции отображения от входа к выходу.
Y = f(X)
Цель состоит в том, чтобы аппроксимировать функцию отображения настолько хорошо, чтобы, когда у вас есть новые входные данные (x), вы могли предсказать выходные переменные (Y) для этих данных.
Это называется обучением с учителем, потому что процесс обучения алгоритма на обучающем наборе данных можно рассматривать как учитель, контролирующий процесс обучения. Нам известны правильные ответы, алгоритм итеративно делает прогнозы на обучающих данных и корректируется учителем. Обучение прекращается, когда алгоритм достигает приемлемого уровня производительности». — Мастерство машинного обучения —
Существует два типа методов обучения без учителя:
- Регрессия
- Классификация
___________________________________________________________________
Регрессия
Используемый в основном для прогнозирования значения в будущем, регрессионный анализ представляет собой набор статистических процессов для оценки взаимосвязей между переменными. Он включает в себя множество методов моделирования и анализа нескольких переменных, когда основное внимание уделяется взаимосвязи между зависимой переменной Y и одной или несколькими независимыми переменными (или «предикторами») X. . В частности, регрессионный анализ помогает понять, как типичное значение зависимой переменной (или «критериальной переменной») изменяется, когда любая из независимых переменных изменяется, в то время как другие независимые переменные остаются фиксированными.
Существует два основных типа регрессии:
- Линейная регрессия
- Логистическая регрессия (рассматривается как алгоритм классификации)
Разница между обеими регрессиями заключается в том, что логистическая регрессия используется, когда зависимая переменная является бинарной по своей природе. Напротив, линейная регрессия используется, когда зависимая переменная непрерывна, а линия регрессии линейна.

___________________________________________________________________
Линейная регрессия
Метод линейной регрессии использует непрерывную зависимую переменную, а независимые переменные могут быть непрерывными или дискретными. Используя прямолинейную линейную регрессию наилучшего соответствия, устанавливает связь между зависимой переменной (Y) и одной или несколькими независимыми переменными (X). Другими словами, существует линейная зависимость между независимыми и зависимыми переменными.
Линия линейной регрессии имеет уравнение в форме Y = a + bX, где X — независимая переменная, а Y — зависимая переменная.
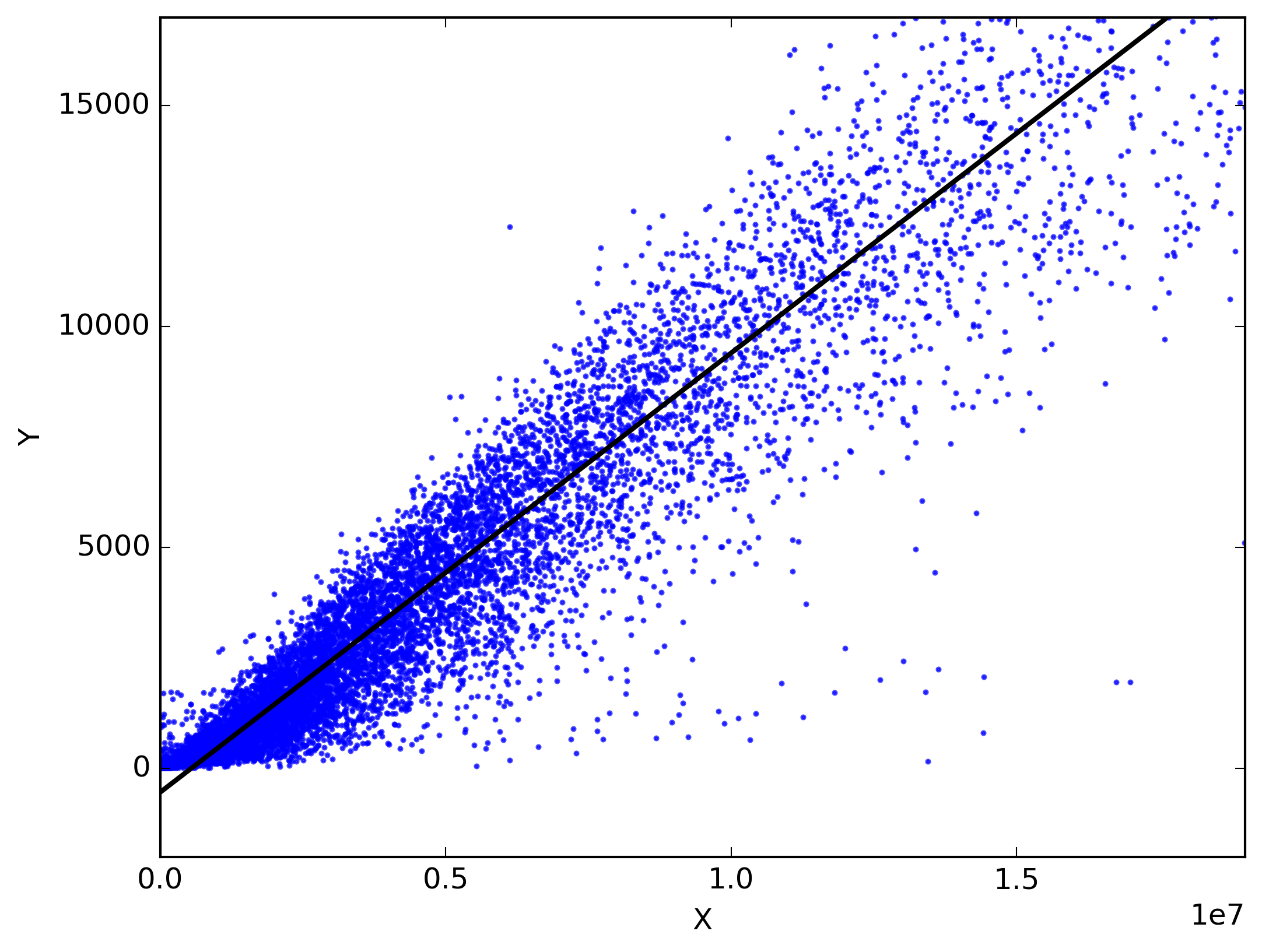
Существует два типа линейной регрессии:
- Простая линейная регрессия: одна независимая переменная и зависимая переменная
- Множественная линейная регрессия:много независимых переменных и зависимая переменная
Как мы можем оценить модель?
Существует 3 типа оценки/расчета точности модели:
- Обучение и тестирование на одном и том же наборе данных
- Поезд/тестовый сплит
- К перекрестная проверка
Метрики оценки:
- Средняя абсолютная ошибка (MAE)
- Среднеквадратическая ошибка (MSE)
- Среднеквадратическая ошибка (RMSE)
- Относительная абсолютная ошибка (RAE)
- Относительная квадратичная ошибка (RSE)
- R² = 1 — RSE: Чем выше R², тем лучше модель
Ошибка модели — это разница между точками данных и линией тренда, сгенерированной алгоритмом.
___________________________________________________________________
— — — — — — — —— Классификация — — — — — — — — —
Это контролируемый подход к обучению, целью которого является разделение неизвестных элементов на дискретный набор категорий или «классов».
Атрибут target – это категориальная переменная.
На основе набора данных мы выполняем моделирование, чтобы иметь «Классификатор», с помощью которого мы делаем прогноз, чтобы иметь прогнозируемые метки.
Для чего он используется?
- Определить, к какой категории относится клиент
- Определите, переключается ли клиент на другого поставщика/бренд
- Определить, реагирует ли клиент на конкретную рекламную кампанию
- Фильтрация электронной почты
- Распознавание речи
- Распознавание рукописного ввода
- Биометрическая идентификация
- Классификация документов
Какие алгоритмы используются для классификации?
- Деревья решений
- Наивный байесовский
- Линейный дискриминантный анализ
- K-ближайший сосед
- Логистическая регрессия
- Нейронные сети
- Методы опорных векторов (SVM)
___________________________________________________________________
— — — — — — — Логистическая регрессия — — — — — — — — —
Для чего он используется?
- Предсказать вероятность сердечного приступа у человека
- Прогнозирование летальности раненых
- Прогнозирование склонности клиента приобрести продукт или прекратить подписку
- Прогнозирование вероятности отказа данного процесса или продукта
- Прогнозирование вероятности дефолта домовладельца по ипотеке
___________________________________________________________________
— — — — —KNN ( k ближайших соседей) — — — — — — —
Алгоритм k-ближайших соседей — это алгоритм классификации, который берет набор помеченных точек и использует их, чтобы узнать, как помечать другие точки.
Этот алгоритм классифицирует дела на основе сходства с другими делами. В k-ближайших соседях точки данных, которые находятся рядом друг с другом, называются «соседями». K-ближайшие соседи основаны на этой парадигме: «Похожие случаи с одинаковыми метками класса находятся рядом друг с другом».
Таким образом, расстояние между двумя случаями является мерой их непохожести.
В задаче классификации алгоритм k ближайших соседей работает следующим образом:
1. Выберите значение для K.
2. Рассчитайте расстояние от нового наблюдения (удержание от каждого наблюдения в наборе данных). (например, расстояние Минковского)
3. Поиск K наблюдений в обучающих данных, которые «наиболее близки» к измерениям неизвестной точки данных.
4. предсказать ответ неизвестной точки данных, используя наиболее популярное значение ответа из K ближайших соседей.
- K находится после попытки оценить каждый раз число K. Мы выбираем K, который приводит нас к наилучшей точности.

___________________________________________________________________
— — — — — — —- ДЕРЕВО РЕШЕНИЙ — — — — — — — —
Алгоритм обучения дерева решений генерирует деревья решений на основе обучающих данных для решения задачи классификации и регрессии.

1- Выберите атрибут из набора данных
2- Рассчитать значимость атрибута (индекс Джини) при разделении данных
3- Разделить данные на основе значения лучшего атрибута
4- Перейти к шагу 1
Энтропия – это степень беспорядка информации или степень случайности данных. Энтропия в узле зависит от того, сколько случайных данных находится в этом узле, и рассчитывается для каждого узла. В деревьях решений мы ищем деревья с наименьшей энтропией в узлах.
прирост информации – это энтропия дерева до разделения минус взвешенная энтропия после разделения.
___________________________________________________________________
SVM
Машина опорных векторов (SVM) — это контролируемый алгоритм машинного обучения, который можно использовать как для задач классификации, так и для задач регрессии. Тем не менее, он в основном используется в задачах классификации. В этом алгоритме мы отображаем каждый элемент данных как точку в n-мерном пространстве (где n — количество имеющихся у вас объектов), при этом значение каждого объекта является значением конкретной координаты. Затем мы выполняем классификацию, находя гиперплоскость, которая очень хорошо различает два класса (посмотрите на снимок ниже).

Как это работает?
1. Сопоставление данных с многомерным пространством признаков
2. Поиск разделителя
- Это хорошо для многомерных наборов данных, но не для маленьких.
- Использование: распознавание изображений, присвоение текстовой категории, обнаружение спама, анализ тональности, классификация экспрессии генов, регрессия, обнаружение выбросов и кластеризация.