Взгляд на текстовые данные через призму нейронных сетей

Встраивание слов = ›Общий термин для моделей, которые научились сопоставлять набор слов или фраз в словаре с векторами числовых значений.
Нейронные сети предназначены для обучения на числовых данных.
Встраивание слов на самом деле предназначено для улучшения способности сетей учиться на текстовых данных. Представляя эти данные как векторы более низкой размерности. Эти векторы называются вложением.
Этот метод используется для уменьшения размерности текстовых данных, но эти модели также могут узнать некоторые интересные особенности слов в словаре.
Как это сделано!
Общий подход к работе со словами в ваших текстовых данных заключается в быстром кодировании текста. В вашем текстовом словаре будут десятки тысяч уникальных слов. Вычисления с такими горячими закодированными векторами для этих слов будут очень неэффективными, потому что большинство значений в вашем горячем векторе будет 0. Таким образом, вычисление матрицы, которое произойдет между одним горячим вектором и первым скрытым слоем, приведет к в выводе, который будет иметь в основном 0 значений
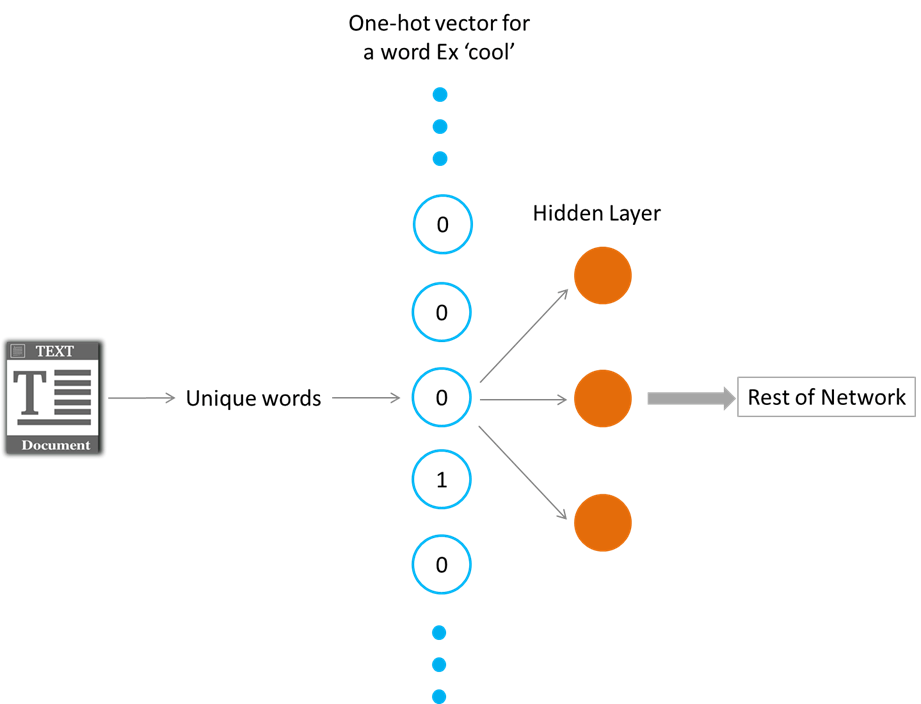
Мы используем встраивания для решения этой проблемы и значительного повышения эффективности нашей сети. Вложения похожи на полностью связанный слой. Мы будем называть этот слой слоем внедрения, а веса - весами внедрения.
Теперь вместо того, чтобы выполнять умножение матрицы между входами и скрытым слоем, мы напрямую получаем значения из встроенной матрицы весов. Мы можем это сделать, потому что умножение горячего вектора на матрицу весов возвращает строку матрицы, соответствующую индексу входной единицы «1».

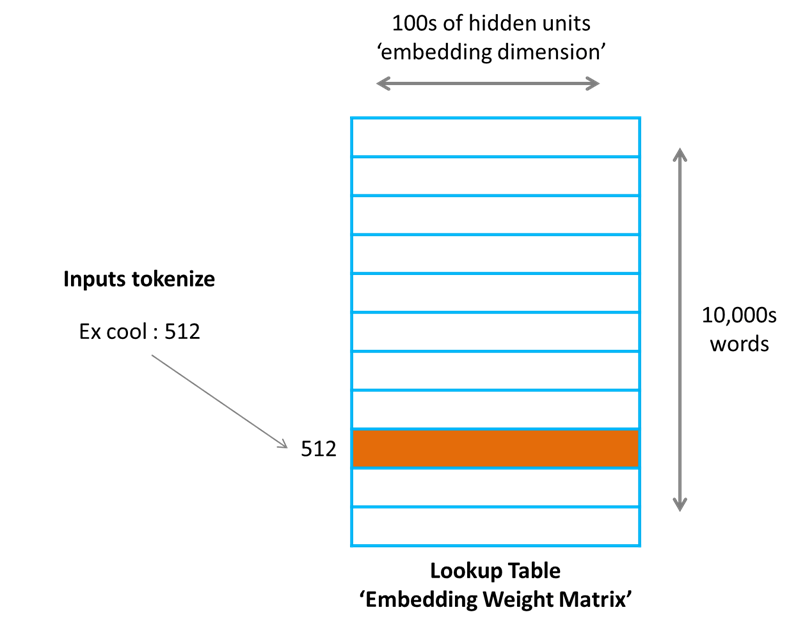
Итак, мы используем эту матрицу веса в качестве таблицы поиска. Мы кодируем слова как целые числа, например, «cool» кодируется как 512, «hot» кодируется как 764. Затем, чтобы получить выходное значение скрытого слоя для «cool», нам просто нужно найти 512-ю строку в матрице весов. Этот процесс называется Встроенный поиск. Количество измерений в выводе скрытого слоя - это размер встраивания.
Повторить :-
а) Встраиваемый слой - это просто скрытый слой
б) Таблица поиска - это просто матрица вложенных весов.
c) Поиск - это просто ярлык для умножения матриц
г) Таблица поиска обучается так же, как и любая матрица весов.
Популярные готовые модели встраивания слов, которые используются сегодня:
- Word2Vec (от Google)
- GloVe (от Стэнфорда)
- fastText (через Facebook)
Эта модель предоставляется Google и обучается на данных Google Новостей. Эта модель имеет 300 измерений и обучена на 3 миллионах слов из данных новостей Google.
Команда использовала скип-грамм и отрицательную выборку для построения этой модели. Он был выпущен в 2013 году.
Глобальные векторы для представления слов (GloVe) предоставлены Стэнфордом. Они предоставили различные модели от 25, 50, 100, 200 до 300 измерений на основе 2, 6, 42, 840 миллиардов токенов.
Команда использовала дословное совпадение, чтобы построить эту модель. Другими словами, если два слова встречаются много раз одновременно, это означает, что они имеют некоторое лингвистическое или семантическое сходство.
Эта модель разработана Facebook. Они предлагают 3 модели по 300 размеров каждая.
fastText может обеспечить хорошую производительность для представлений слов и классификаций предложений, поскольку они используют представления на уровне символов.
Каждое слово представлено в виде набора символов n-граммов в дополнение к самому слову. Например, для слова partial с n = 3 представление fastText для символа n-граммов будет <pa, art, rti, tia, ial, al>. < и> добавляются как граничные символы, чтобы отделить n-граммы от самого слова.
Спасибо за прочтение!
- Если вам понравилось, подписывайтесь на меня в среднем, чтобы узнать больше.
- Ваши аплодисменты - это огромное поощрение и мотивация писать больше и писать лучше.
- Заинтересованы в сотрудничестве? Давайте подключимся к Linkedin.
- Пожалуйста, не стесняйтесь писать свои мысли / предложения / отзывы.