
Привет. Надеюсь, у тебя все хорошо. В моем последнем посте мы настроили необходимую среду. Давайте начнем с сегодняшнего поста о персептроне.
Перцептрон - это фундаментальная единица нейронной сети. Это алгоритм контролируемого обучения (мы говорим, что правильно, а что неправильно) для двоичной классификации (ноль или единица).
Персептрон также является базовой математической моделью нейрона. Он пытается воспроизвести работу нейрона. Итак, чтобы реализовать перцептрон, давайте немного изучим нейрон.
Нейрон
Мы знаем, что нейроны - это основной строительный блок мозга (массивная и сложная нейронная сеть).
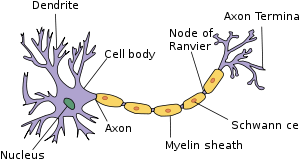
Итак, это был тот парень, о котором я говорил. Давайте посмотрим на функции этого парня на очень высоком уровне абстракции.
- Он принимает сигнал от других нейронов через дендриты.
- Он будет обрабатывать сигнал в ядре.
- Передает обработанную информацию другим ячейкам через Axon Termina.
Итак, давайте попробуем придумать модель, которая в некоторой степени воспроизводит активность нейрона.
Рождение перцептрона
Perceptron пытается выполнять вышеупомянутые действия. Попробуем смоделировать один.
Итак, что он должен делать?
- Это может занять \ (n \) количество входов.
- Выполняет некоторые вычисления на входе.
- Передает его через нелинейную функцию (очень важно).
- Производит единичный вывод.
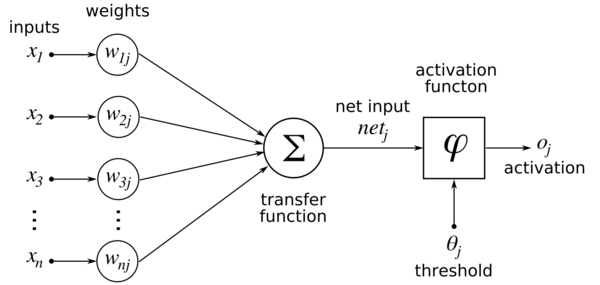
\ (x_i \) - это вход \ (i ^ {th} \). \ (W_i \) - значение веса, соответствующее входу \ (i ^ {th} \).
\ (\ sigma \) - функция активации.
Мы умножаем все \ (x_i \) на \ (W_i \) и суммируем их, чтобы получить один результат, который затем передается в функцию активации для получения результата. Это наша модель нейрона.
Почему активация?
Функции активации нелинейны, то есть их график не является прямой линией. Использование нелинейности помогает аппроксимировать любую функцию, если у нас есть достаточное количество единиц.
Давайте рассмотрим одну функцию активации, которая называется пошаговой функцией.
Ступенчатая функция
\ (S (x) = \ begin {case} 1, & \ text {if} x \ geq 0 \\ 0, & \ text {if} x \ lt 0
\ end {case} \)
Как мы увидим ниже. \ (x \) может принимать значения от \ ({- \ infty} \) до \ ({\ infty} \)
\ (S (x) \) может принимать значения от \ (0 \) до \ (1 \)

Здесь график не является прямой линией и ее наклон в разных точках разный.
Хватит теории, приступим к кодированию.
Мы смоделировали наш перцептрон, теперь давайте посмотрим, на что он способен.
Запустите свой блокнот jupyter с помощью этой команды
$ jupyter notebookСоздайте новую записную книжку с именем Exercise-2.
Импортируйте следующие модули
Давайте создадим перцептрон
Здесь мы моделируем персептрон, используя класс, и у него есть некоторые важные методы, которые используются для некоторой имитации действия реального нейрона. Полный код приведен ниже, чтобы вы могли попробовать, а также предоставляется разбивка компонентов.
Разберем код.
У нас есть внутреннее состояние W для нашего перцептрона, которое необходимо изучить. Размер состояния равен количеству входов плюс один. Это потому, что это дает нам способ интегрировать смещение внутри самой матрицы W, если мы можем дополнить вход одним. Это была бы простая реализация
$$ W * x + b $$
Итак, перцептрон был инициализирован. Теперь мы можем узнать больше о других методах перцептрона.
step_function
Это принимает единственный ввод и применяет step_function, который дает нам вывод в двоичном формате.
вперед
Он принимает массив входных данных, выполняет поэлементное умножение и суммирует его, чтобы получить один выходной (скалярный продукт). Затем он переходит в нелинейную активацию. Это даст результат либо 1, либо 0. Здесь принимаются решения о данных.
потеря
Эта функция действует как критик. У этого парня есть и прогнозируемая стоимость, и исходная этикетка. Он сравнивает их обоих и учит перцептрон правильному и неправильному.
back_propagate
Это принимает входные данные от функции потерь и регулирует веса \ (W \).
batch_train
Эта функция принимает входные данные, передает их в сеть и обучает перцептрон.
Аналогия
Рассмотрим передовую функцию как ученика, идущего в школу.
- Пусть \ (W \) представляет его действия в тесте.
- Итак, вперед - действие сдачи теста.
- Функция потерь подобна учителю, который исправляет свою работу и говорит ему, что не так, а что правильно.
- back_propagate - родители этого ученика. Они получают информацию от учителя и корректируют его действия, чтобы он мог получить больше оценок на следующем экзамене.
Теперь наш перцептрон готов. Давайте использовать это, чтобы приблизить функцию AND.
Здесь логический элемент И принимает два входа, а его скорость обучения составляет 0,5. Вы можете изменить и посмотреть скорость обучения и посмотреть, что произойдет. В последней строке печатается значение выхода логического элемента И, когда оба входа равны 1. Теперь попробуйте с разными входами.
У вас есть животрепещущий вопрос по этому поводу?
Потому что у меня возникли вопросы, когда я впервые услышал об этом.
Как мы узнаем, когда перцептрон готов?
Поскольку мы знаем все входные данные, которые когда-либо получит этот перцептрон, и, к счастью, он невелик, мы можем использовать все данные для обучения перцептрона. Итак, в этом случае, когда значение потерь становится равным нулю, мы знаем, что наш перцептрон готов к действию.

Мы знаем, что после 5-й эпохи персептрон увидел все возможные входные данные и правильно их классифицировал.
Какое число правильное для скорости обучения и эпох?
Ответ - мы не знаем. Они называются гиперпараметрами. Мы можем использовать метод проб и ошибок, чтобы найти правильные числа.
Мы знаем, что это работает, но как это работает?
Это проблема классификации, когда мы должны разделить данные на \ (0 \) или \ (1 \). Все входные данные дают либо \ (0 \), либо \ (1 \). Итак, перцептрон правильно их классифицировал. Он каким-то образом знает, что входы с двумя, один должен быть классифицирован как один, а все остальные должны быть равны нулю. Так откуда он это знает? Ответ на поставленный выше вопрос заключается в том, что он пытается создать границу между точками данных (линейно разделяемые). В этом случае он создает плоскость, которая разделяет входные точки, что дает ноль и единицу по отдельности.
Решение плоскости And Gate | поверхность от Thunderbo1t | plotly
Интерактивный график Thunderbo1t и данные «Решающая плоскость и ворота представляют собой поверхность. plot.ly »
Здесь три точки разделены плоскостью. Эти три точки лежат под плоскостью, а одна точка - над ней. Эта плоскость - плоскость принятия решений. Входы логического элемента И отображаются на X и Y на графике. Точки XY под плоскостью принадлежат к одному классу, а точки над плоскостью - к другому классу.
Хорошо. Откуда перцептрон знает план?
Персептрон начинает со случайной плоскости в трехмерном пространстве и перемещает ее так, чтобы можно было разделить входные данные в зависимости от их класса. Здесь на сцену выходят функция потерь и обратное распространение. Функция потерь оценивает текущую плоскость и находит, где она идет не так, и посредством обратного распространения обучает перцептрон.
Где код для графиков и 3D-графиков?
Это гит-репо. Попробуйте код на себе и повозитесь с ним. Воспользуйтесь этой ссылкой для просмотра выполненных выходов. Не стесняйтесь задавать свои вопросы в комментариях.
В моем следующем блоге…
- Загляните в нейронную сеть.
- Связь между перцептроном и нейронной сетью.
- Обучение однослойной сети персептронов.
- Оценка и тестирование.
Первоначально опубликовано на сайте thetechcache.science 10 февраля 2019 г.