Резюме на бумаге

Это краткое изложение статьи:
ENet: архитектура глубокой нейронной сети для семантической сегментации в реальном времени
от Адама Пашке
Документ : Https://arxiv.org/abs/1606.02147
Обзор
ENet (эффективная нейронная сеть) дает возможность выполнять семантическую сегментацию по пикселям в реальном времени. ENet работает до 18 раз быстрее, требует в 75 раз меньше FLOP, имеет в 79 раз меньше параметров и обеспечивает аналогичную или лучшую точность по сравнению с существующими моделями. Протестировано на наборах данных CamVid, CityScapes и SUN.

Методы

Выше представлена полная сетевая архитектура.
Он разделен на несколько этапов, которые выделены горизонтальными линиями в таблице и первой цифрой после имени каждого блока.
Выходные размеры указаны для разрешения входного изображения 512 * 512
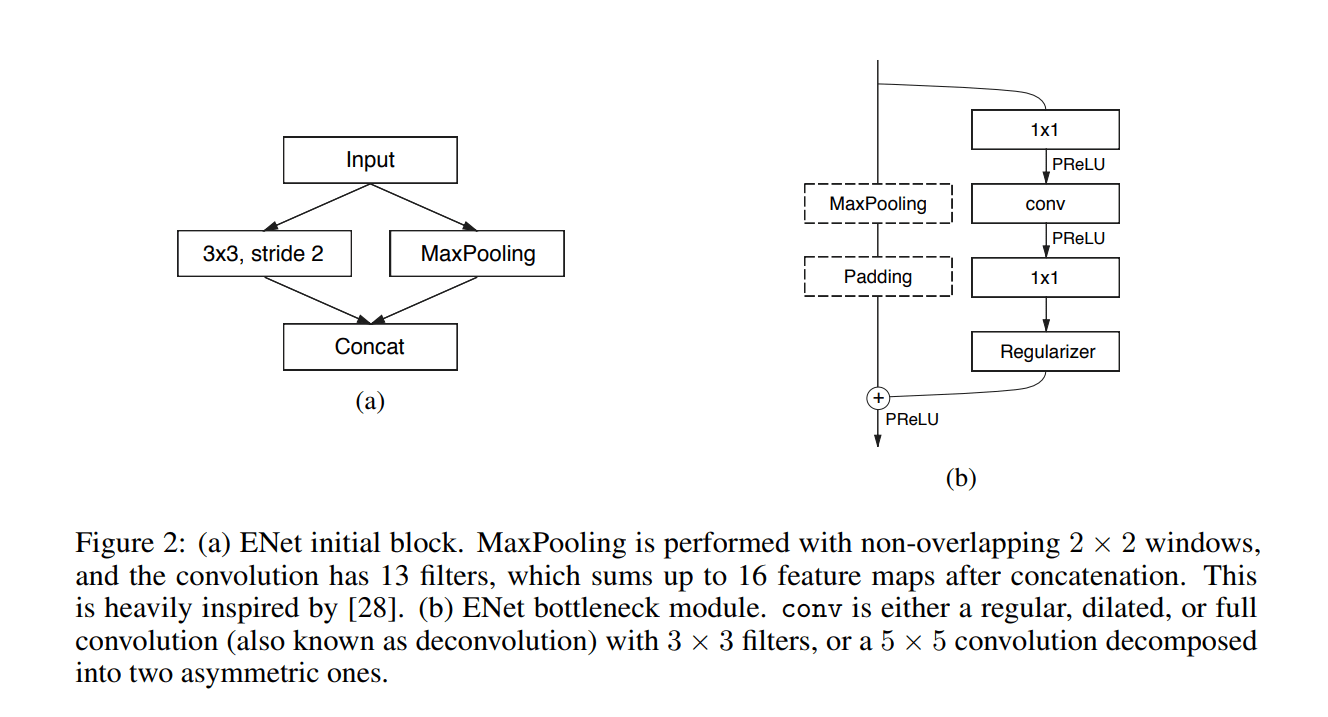
Визуальное представление:
- Начальный блок показан в (a)
-, а узкие блоки показаны в (b)
Каждый модуль узкого места состоит из:
- проекции 1x1, уменьшающей размерность
- основного сверточного слоя (conv) (либо - обычный, расширенный или full) (3x3)
- расширение 1x1
- и они помещают Batch Normalization и PReLU между всеми сверточными слоями.
Если узким местом является даунсэмплинг, к основной ветви добавляется максимальный уровень объединения. Кроме того, первая проекция 1x1 заменяется сверткой 2x2 с шагом = 2.
Они обнуляют активации, чтобы соответствовать количеству карт функций.
conv иногда является асимметричной сверткой, то есть последовательностью 5 * 1 и 1 * 5 сверток.
Для regularizer используется Spatial Dropout:
- с p = 0.01 перед узким местом2.0
- с p = 0.1 после
So,
- Этап 1, 2, 3 - кодировщик - состоит из 5 блоков узких мест (за исключением того, что на этапе 3 не выполняется субдискретизация).
- Этап 4, 5 - декодер. Этап 4 содержит 3 узких места, а этап 5 - 2 узких места.
- За ним следует
fullconv, который выводит окончательный результат с размером -C * 512 * 512, гдеC- количество фильтров.
Еще несколько фактов:
- Они не использовали условия смещения ни в одной из проекций.
- Между каждым сверточным слоем и активацией они использовали пакетную нормализацию.
- В декодере MaxPooling заменен на MaxUnpooling
- В декодере Padding заменяется на Spatial Convolution без смещения
- Индексы объединения не используются в модуле повышения дискретизации last (5.0) < br /> - Последний модуль сети представляет собой чистую полную свертку, которая сама по себе занимает значительную часть времени обработки декодера.
- Каждая боковая ветвь имеет пространственное исключение с p = 0.01 для этапа 1 и p = 0.1 для этапы после.
Полученные результаты
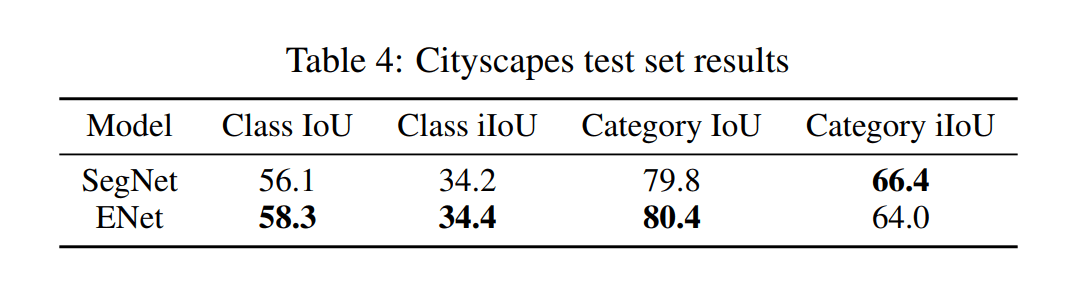
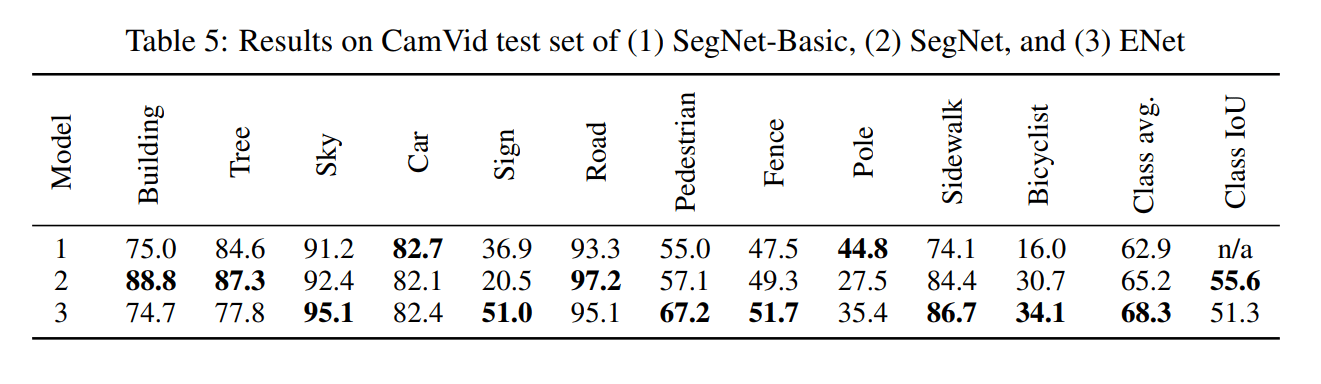
Проведено сравнение производительности ENet на
- CamVid (дорожные сцены)
- CityScapes (дорожные сцены)
- SUN RGB -D (внутренние сцены)
с использованием SegNet [2] в качестве основы, поскольку это одна из самых быстрых моделей сегментации. Использовал библиотеку Torch7 с использованием backend cuDNN.
Скорость вывода записывается с использованием графического процессора NVIDIA Titan X, а также встроенного системного модуля NVIDIA TX1. Достигнуто более 10 кадров в секунду при размере входного изображения 640x360.


Контрольные точки
Подержанный Адам. ENet очень быстро сошлась, и для каждого набора данных обучение длилось всего 3–6 часов с использованием 4 графических процессоров Titan X.
Выполнялось в два этапа:
- Сначала они обучили кодировщик категоризировать субдискретизированные области входного изображения.
- А затем добавили декодер и обучили сеть выполнять повышающую дискретизацию и попиксельную классификацию.
Скорость обучения - 5e-4
Снижение веса L2 на 2e-4
Размер партии 10
Схема взвешивания специального класса, определяемая как
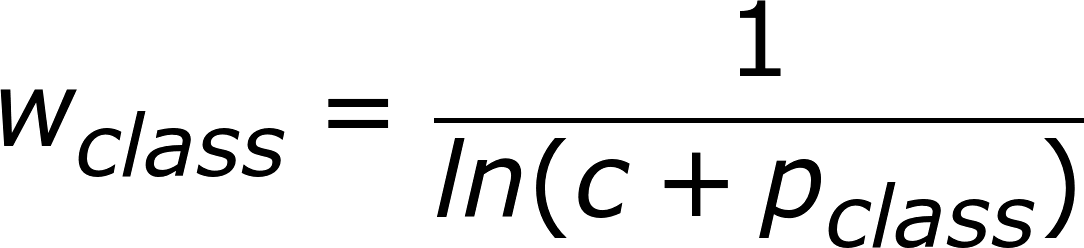
где c = 1.02
А веса классов ограничены интервалом [1, 50]

использованная литература
- А. Пашке, А. Чауразия, С. Ким, Э. Кулурчелло. Enet: глубокая нейронная сетевая архитектура для семантической сегментации в реальном времени. Препринт arXiv arXiv: 1606.02147, 2016.
- В. Бадринараянан, А. Кендалл и Р. Чиполла, «Segnet: архитектура глубокого сверточного кодера-декодера для сегментации изображения», препринт arXiv arXiv: 1511.00561, 2015.
Я также недавно воспроизвел статью, которую можно найти здесь: https://github.com/iArunava/ENet-Real-Time-Semantic-Segmentation
Спасибо за прочтение! Прочтите газету!
Буду обновлять, если найду другие интересные идеи!