
Распределитель Slab - это основной модуль кэш-системы, который в значительной степени определяет, насколько эффективно может использоваться узкое место - память. Остальные 3 части, а именно алгоритм LRU истечения срока входа; и модель, управляемая событиями, основанная на libevent; и постоянная жесткость в отношении распределения данных построены вокруг этого.
Плита I
Плита II
Плита III
LRU I
LRU II (эта статья)
LRU III
Событийный я
Чаще всего алгоритм LRU сочетается с хэш-картой и называется кешем LRU.
В LRU-кэше хэш-карта обеспечивает быстрый доступ к кешированным объектам; а LRU предотвращает бесконечное увеличение кеша, отмечая просроченные или так называемые наименее недавно использованные объекты. На этот раз мы исследуем реализацию хеш-карты в memcached.
Обзор (учебник перекрывается, пропускать)
Хеш-карта - это, по сути, массив фиксированного размера, который индексирует значения с целыми числами, хешированными из ключа s. В хэш-карте запись массива называется корзиной. Если хеш-значение превышает количество сегментов (т. Е. Размер массива), оно переключается с помощью ‘mod’ (%). Коллизия возникает, когда более двух ключей приводят к одному и тому же хэш-значению или к разным хеш-значениям переходят в того же ведра, то на коллизии формируется связанный список *.
Столкновение снижает скорость поиска для последовательного доступа к связанному списку, поэтому необходимо увеличить номер сегмента и повторно хешировать записи с новым номером сегмента, прежде чем производительность станет слишком низкой. Об этом процессе пойдет речь скоро.
Инициализация модуля
Первым подходящим методом является
hash_init
который просто определяет тип хеш-алгоритма.
int hash_init(enum hashfunc_type type) {
switch(type) {
case JENKINS_HASH:
hash = jenkins_hash;
settings.hash_algorithm = "jenkins";
break;
case MURMUR3_HASH:
hash = MurmurHash3_x86_32;
settings.hash_algorithm = "murmur3";
break;
default:
return -1;
}
return 0;
}
Этот метод вызывается отсюда как один из шагов инициализации перед тем, как логика перейдет в основной цикл обработки событий.
Параметр hash_type устанавливается в MURMUR3_HASH указанным аргументом командной строки modern.
Второй способ
assoc_init
выделяет массив фиксированного размера, упомянутый в начале.
void assoc_init(const int hashtable_init) {
if (hashtable_init) {
hashpower = hashtable_init;
}
primary_hashtable = calloc(hashsize(hashpower), sizeof(void *));
if (! primary_hashtable) {
fprintf(stderr, "Failed to init hashtable.\n");
exit(EXIT_FAILURE);
}
...// scr: stat
}
Этот метод вызывается в том же месте, что и hash_init, как часть процесса начальной загрузки системы.
… assoc_init(settings.hashpower_init); …
Фактический начальный размер определяется параметром hashpower в командной строке.
...
case HASHPOWER_INIT:
if (subopts_value == NULL) {
fprintf(stderr, "Missing numeric argument for hashpower\n");
return 1;
}
settings.hashpower_init = atoi(subopts_value);
if (settings.hashpower_init < 12) {
fprintf(stderr, "Initial hashtable multiplier of %d is too low\n",
settings.hashpower_init);
return 1;
} else if (settings.hashpower_init > 64) {
fprintf(stderr, "Initial hashtable multiplier of %d is too high\n"
"Choose a value based on \"STAT hash_power_level\" from a running instance\n",
settings.hashpower_init);
return 1;
}
break;
...
Как было сказано ранее, массив можно заменить новым выделенным массивом большего размера, если производительность упадет из-за чрезмерного коллизии. Далее мы обсудим процесс
Масштабирование и миграция входа
В memcached порог равен 1,5, что означает, что если номер элемента превышает 1,5 * номер сегмента, начинается упомянутый процесс расширения.
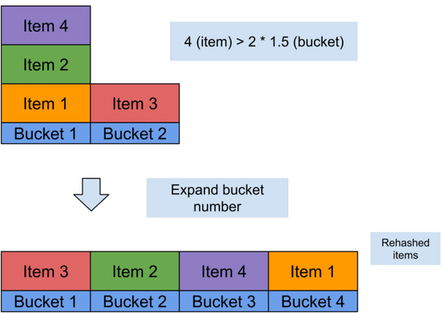
...
if (! expanding && hash_items > (hashsize(hashpower) * 3) / 2) {
assoc_start_expand();
}
...
assoc_start_expand просто устанавливает флаг (т.е. do_run_maintenance_thread) и отправляет сигнал для пробуждения потока обслуживания, который выполняет фактическую работу.
static void assoc_start_expand(void) {
if (started_expanding)
return;
started_expanding = true;
pthread_cond_signal(&maintenance_cond);
}
Основной цикл потока обслуживания
static void *assoc_maintenance_thread(void *arg) {
mutex_lock(&maintenance_lock);
while (do_run_maintenance_thread/* scr: the flag*/) {
int ii = 0;
/* There is only one expansion thread, so no need to global lock. */
for (ii = 0; ii < hash_bulk_move && expanding; ++ii) { // 2)
item *it, *next;
int bucket;
void *item_lock = NULL;
/* bucket = hv & hashmask(hashpower) =>the bucket of hash table
* is the lowest N bits of the hv, and the bucket of item_locks is
* also the lowest M bits of hv, and N is greater than M.
* So we can process expanding with only one item_lock. cool! */
if ((item_lock = item_trylock(expand_bucket))) { // scr: 3)
for (it = old_hashtable[expand_bucket]; NULL != it; it = next) {
next = it->h_next; // scr: ------------------------> 4)
bucket = hash(ITEM_key(it), it->nkey) & hashmask(hashpower);
it->h_next = primary_hashtable[bucket];
primary_hashtable[bucket] = it;
}
old_hashtable[expand_bucket] = NULL; // scr: --------------> 4.1)
expand_bucket++; // scr: ------------------------------------> 5)
if (expand_bucket == hashsize(hashpower - 1)) { // 6)
expanding = false;
free(old_hashtable);
... // scr: -------------------------------------------> stat & log
}
} else {
usleep(10*1000); // scr: --------------------------> 3.1)
}
if (item_lock) { // scr: ----------------------------------> 3.2)
item_trylock_unlock(item_lock);
item_lock = NULL;
}
}
if (!expanding) {
/* We are done expanding.. just wait for next invocation */
started_expanding = false;
pthread_cond_wait(&maintenance_cond, &maintenance_lock); // scr: --------------------------------------------------------> 0)
/* assoc_expand() swaps out the hash table entirely, so we need
* all threads to not hold any references related to the hash
* table while this happens.
* This is instead of a more complex, possibly slower algorithm to
* allow dynamic hash table expansion without causing significant
* wait times.
*/
pause_threads(PAUSE_ALL_THREADS);
assoc_expand(); // scr: -------------------------------> 1)
pause_threads(RESUME_ALL_THREADS);
}
}
return NULL;
}
{% endcodeblock %}
0) Здесь поток ожидает выхода из спящего режима и начинает работать и засыпает, когда нечего делать.
1) assoc_expand выделяет ресурс для новой хэш-карты, которая предназначена для замены старой, инициализированной отсюда.
/* grows the hashtable to the next power of 2. */
static void assoc_expand(void) {
old_hashtable = primary_hashtable;
primary_hashtable = calloc(hashsize(hashpower + 1), sizeof(void *));
if (primary_hashtable) {
... // scr: log
hashpower++;
expanding = true;
expand_bucket = 0;
... // scr: stat
} else {
primary_hashtable = old_hashtable;
/* Bad news, but we can keep running. */
}
}
2) Перенести только определенное количество элементов за один пакет. hash_bulk_move позволяет избежать слишком долгого зависания потока при вызове stop_assoc_maintenance_thread. В отличие от обсуждаемого assoc_start_expand, stop_assoc_maintenance_thread сбрасывает флаг do_run_maintenance_thread и отправляет сигнал для пробуждения потока для выхода.
void stop_assoc_maintenance_thread() {
mutex_lock(&maintenance_lock);
do_run_maintenance_thread = 0;
pthread_cond_signal(&maintenance_cond);
mutex_unlock(&maintenance_lock);
/* Wait for the maintenance thread to stop */
pthread_join(maintenance_tid, NULL);
}
3) («Блокировка элемента» фактически работает для всего сегмента, поэтому я назову его вместо этого блокировкой сегмента). Используйте низкий приоритет item_trylock (i.e., pthread_mutex_trylock) для доступа к замок ведра; 3.1) спать на 10 секунд, когда элемент недоступен; и 3.2) снимите блокировку с помощью item_trylock_unlock после завершения миграции (этого сегмента).
void *item_trylock(uint32_t hv) {
pthread_mutex_t *lock = &item_locks[hv & hashmask(item_lock_hashpower)];
if (pthread_mutex_trylock(lock) == 0) {
return lock;
}
return NULL;
}
4) Перехешируйте все элементы в корзине и перенесите их в новую хэш-карту.
5) Перейдите к следующему сегменту.
6) Достигнут последний сегмент - ›перейти к 0)
Начало обслуживания потока
int start_assoc_maintenance_thread() {
int ret;
char *env = getenv("MEMCACHED_HASH_BULK_MOVE");
if (env != NULL) {
hash_bulk_move = atoi(env);
if (hash_bulk_move == 0) {
hash_bulk_move = DEFAULT_HASH_BULK_MOVE;
}
}
pthread_mutex_init(&maintenance_lock, NULL);
if ((ret = pthread_create(&maintenance_tid, NULL,
assoc_maintenance_thread, NULL)) != 0) {
fprintf(stderr, "Can't create thread: %s\n", strerror(ret));
return -1;
}
return 0;
}
Подобно методам инициализации, он вызывается при загрузке системы.
Остановка резьбы для обслуживания
Этот метод вызывается в процессе завершения работы системы, поэтому по логике он противоположен start_assoc_maintenance_thread. Тем не менее, действия этого метода противоположны механизму assoc_start_expand.
void stop_assoc_maintenance_thread() {
mutex_lock(&maintenance_lock);
do_run_maintenance_thread = 0;
pthread_cond_signal(&maintenance_cond);
mutex_unlock(&maintenance_lock);
/* Wait for the maintenance thread to stop */
pthread_join(maintenance_tid, NULL);
}
Как было сказано ранее, обсуждаемый здесь процесс расширения и миграции влияет на логику всех операций, связанных с хэш-картой. В следующем разделе мы рассмотрим эти операции.
CRUD
Н.б., assoc_delete обсуждалось в предыдущем посте; а в системе "ключ-значение" update и insert по существу одинаковы, поэтому в этом разделе будут обсуждаться операции C (создать) и R (только чтение).
assoc_insert
int assoc_insert(item *it, const uint32_t hv) {
unsigned int oldbucket;
if (expanding &&
(oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
{
it->h_next = old_hashtable[oldbucket]; // scr: -------> 1)
old_hashtable[oldbucket] = it;
} else {
it->h_next = primary_hashtable[hv & hashmask(hashpower)]; // scr: --------------------------------------------------------------> 2)
primary_hashtable[hv & hashmask(hashpower)] = it;
}
pthread_mutex_lock(&hash_items_counter_lock);
hash_items++; // scr: --------------------------------------> 3)
if (! expanding && hash_items > (hashsize(hashpower) * 3) / 2) {
assoc_start_expand();
}
pthread_mutex_unlock(&hash_items_counter_lock);
return 1;
}
1) Если происходит процесс расширения и связанный сегмент хеш-ключ не был перенесен, вставьте элемент в old_hashtable. Обратите внимание, что здесь мы используем старый номер сегмента (т.е. hashmask(hashpower - 1))) для вычисления хеш-индекса.
2) В противном случае вставьте элемент в primary_hashtable напрямую.
3) Увеличьте глобальную переменную hash_items (количество элементов). Если после добавления элемента оно превышает пороговое значение, начните процесс развертывания и миграции. Обратите внимание, что это также преамбула предыдущего раздела.
assoc_find
item *assoc_find(const char *key, const size_t nkey, const uint32_t hv) {
item *it;
unsigned int oldbucket;
if (expanding &&
(oldbucket = (hv & hashmask(hashpower - 1))) >= expand_bucket)
{
it = old_hashtable[oldbucket]; // scr: ---------------> 1)
} else {
it = primary_hashtable[hv & hashmask(hashpower)]; // 2)
}
item *ret = NULL;
int depth = 0;
while (it) { // scr: -------------------------------------> 3)
if ((nkey == it->nkey) && (memcmp(key, ITEM_key(it), nkey) == 0)) {
ret = it;
break;
}
it = it->h_next;
++depth;
}
MEMCACHED_ASSOC_FIND(key, nkey, depth);
return ret;
}
1) Как и в случае с assoc_insert, этот шаг определяет местонахождение сегмента из old_hashtable, когда ключ еще не был перехэширован.
2) В противном случае используйте primary_hashtable напрямую.
3) Просмотрите связанный список и сравните ключ (вместо хеш-индекса) напрямую, чтобы найти элемент в случае столкновения.
Стоит отметить, что assoc_find очень похож на _hashitem_before, который обсуждался в предыдущем посте. Разница в том, что _hashitem_before возвращает адрес следующего члена элемента перед найденным (pos = &(*pos)->h_next;), что требуется при удалении записей из односвязного списка; в то время как этот метод возвращает непосредственно найденный элемент (ret = it;).
Изначально опубликовано на holmeshe.me.