Интерпретируемость моделей глубоких нейронных сетей (DNN) всегда была ограничивающим фактором для случаев использования, требующих объяснения функций, задействованных в моделировании, и это имеет место во многих отраслях, таких как финансовые услуги. Финансовые учреждения, в силу регулирования или по собственному выбору, предпочитают структурные модели, которые легко интерпретируются людьми, поэтому модели глубокого обучения в этих отраслях медленно внедряются. Примером критического варианта использования могут быть модели риска, где обычно банки предпочитают классические статистические методы, такие как обобщенные линейные модели, байесовские модели и традиционные модели машинного обучения, такие как древовидные модели, которые легко объяснимы и интерпретируются с точки зрения человеческой интуиции.
Интерпретируемость с самого начала была важной областью исследований, поскольку модели глубокого обучения могут достигать высокой точности, но за счет высокой абстракции (т.е. точность против проблемы интерпретируемости). Это важно также из-за доверия, поскольку модель, которой не доверяют, - это модель, которая не будет использоваться (т.е. попробуйте продать высшему руководству модель черного ящика).
Чтобы понять эту проблему, просто представьте себе простую DNN, состоящую из множества уровней, которая пытается предсказать цену товара, используя множество переменных функций, и спросите себя:
- что означает вес каждого соединения с точки зрения интерпретации результата?
- Какой набор весов играет наиболее важную роль в окончательном прогнозе?
- Говорит ли мне знание величины весов что-нибудь о важности входных переменных?
Во-первых, веса в нейронной сети являются мерой того, насколько сильна каждая связь между каждым нейроном. Итак, глядя на первый плотный слой в вашей DNN, вы можете определить, насколько сильны связи между нейронами первого слоя и входами. Во-вторых, после первого слоя вы теряете связь один-ко-многим, и это превращается в чудовищный беспорядок, запутанный многие-ко-многим. Это означает, что нейрон в одном слое может быть связан с каким-то другим удаленным нейроном (т.е. нейроны испытывают эффекты нелокальности из-за обратного распространения). Наконец, весы точно рассказывают историю о вводе, но информация, которую они имеют, сжимается в нейронах после применения функций активации (т.е. нелинейности), что очень затрудняет декодирование. Неудивительно, что модели глубокого обучения называют черными ящиками.
Методы объяснения нейронных сетей обычно относятся к двум широким категориям (1) методы значимости и (2) атрибуция признаков (FA).
Методы заметности хороши для визуализации того, что происходит внутри сети, и ответов на такие вопросы, как (1) какие веса активируются при определенных входных данных? или (2) какие области изображения обнаруживаются конкретным сверточным слоем? . В нашем случае это не то, что нам нужно, поскольку на самом деле это ничего не говорит нам о том, какая функция «лучше всего» для описания наших окончательных прогнозов.
Методы FA - это тип методов, которые пытаются подогнать структурные модели к подмножеству данных таким образом, чтобы выяснить объясняющую силу каждой переменной в выходной переменной. С. Лундберг, С. Ли, показали в статье NIPS 2017 (см. Статью), что все модели, такие как LIME, DeepLIFT и Layer-Wise Relevance Propagation, являются частью более широкого семейства методов. именованные методы атрибуции аддитивных признаков (AFA) со следующим определением:
Методы атрибуции аддитивных признаков имеют модель объяснения, которая является линейной функцией двоичных переменных:

где z ’- подмножество {0,1} ^ M, где M - количество упрощенных функций, а Phi_i - веса (т. е. вклады или эффекты).
LIME, DeepLIFT и Layer-Wise Relevance Propagation - все попытки минимизировать целевую функцию для аппроксимации g (z ’). Таким образом, все они являются частью семейства методов AFA.
В той же статье авторы предложили метод оценки вкладов (Phi_i) этой линейной модели, основанный на теории игр, названный ценностями Шепли. Зачем вводить теорию игр в эту картину?
Существует раздел теории игр, изучающий совместные игры, цель которых - предсказать наиболее справедливое распределение богатства (т. Е. Выплат) между всеми игроками, которые работают вместе для достижения общего результата. Это именно то, что предлагают авторы: Использовать значения Шепли в качестве меры вклада переменных характеристик в прогнозирование выходных данных модели.
Авторы показали, что значения Шепли являются оптимальным решением для определенного типа совместных игр, частью которых также являются методы AFA (см. Статью). Наконец, они предложили значения SHAP (Shapley Additive Explanation) в качестве единой меры важности функции и некоторые методы их эффективного создания, такие как:
- SHAP ядра (линейные значения LIME + Shapley)
- Deep SHAP (значения DeepLift + Shapley)
- SHAP дерева (объяснение дерева + значения Shapley)
В этой статье я покажу вам, как использовать DeepSHAP применительно к нейронным сетям, но перед тем, как мы начнем, вам нужно будет установить следующую библиотеку Python:
- shap: https://github.com/slundberg/shap (›pip install shap)
- морской
- панды
- keras + tensorflow
- Требуется блокнот Jupyter (поскольку shap использует некоторые полезные графики javascript)
Пример DeepSHAP:
Мы собираемся использовать набор данных алмазов, который поставляется с seaborn. Это проблема регрессии, для которой мы пытаемся оценить цену бриллианта с учетом показателей качества бриллианта.
Наши данные выглядят так


Давайте получим переменные цели и функции и закодируем категориальные переменные:
Это дает нам сопоставления для дальнейшего использования

А теперь займемся обучением и тестовой установкой:
Теперь давайте настроим модель нейронной сети, используя простую полностью подключенную сеть с прямой связью (с ранней остановкой).

В моей установке есть графический процессор NVDIA P4000, поэтому он работает довольно быстро, если у вас нет графического процессора, просто увеличьте размер пакета в зависимости от ограничений памяти. Итак, через 15 сек получаем:
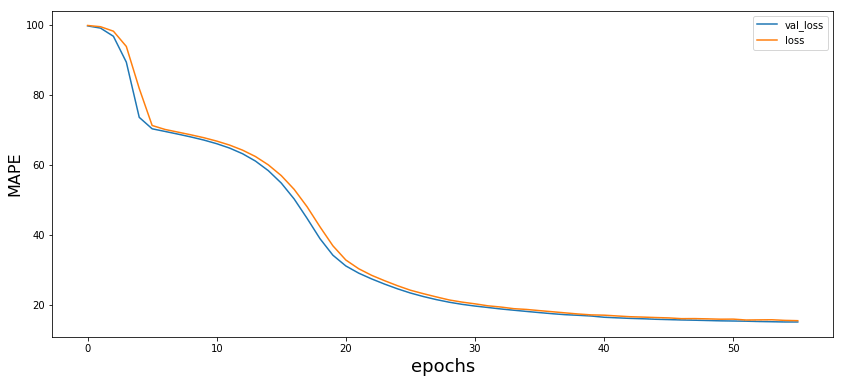
Теперь DeepSHAP:
Использовать DeepSHAP довольно просто благодаря библиотеке python shap. Просто настройте его следующим образом:
Метод shap_values (X) выполняет подгонку алгоритма SHAP на основе DeepLIFT с использованием выборки shapley. Чем больше данных вы выберете, тем больше времени это займет, так что будьте осторожны.
Теперь давайте посмотрим на некоторые индивидуальные атрибуты, полученные с помощью модели:

Чтобы понять эти графики силы, вам нужно вернуться к статье автора:
… Значения SHAP (аддитивное объяснение Шапли) приписывают каждой характеристике изменение в ожидаемом прогнозе модели при согласовании с этой функцией. Они объясняют, как получить из базового значения E [f (z)], которое можно было бы спрогнозировать, если бы мы не знали каких-либо характеристик для текущего вывода f (x). На этой диаграмме показан единичный заказ. Однако, когда модель является нелинейной или входные функции не являются независимыми, порядок, в котором функции добавляются к ожидаемому, имеет значение, и значения SHAP возникают в результате усреднения значений φi по всем возможным порядкам.
Обратите внимание, что есть это базовое значение, которое является ожидаемым значением (например, E [f (z)]), вычисленным DeepSHAP, которое является просто значением, которое было бы предсказано, если бы вы не знаю никаких особенностей. Также имеется это выходное значение (т. Е. Сумма всех вкладов функций и базовое значение), которое равно предсказанию фактической модели. Значения SHAP, таким образом, просто говорят вам, какой вклад добавляет каждая функция, чтобы перейти от базового значения к выходному значению .
Для рисунка 1 это можно понять следующим образом:
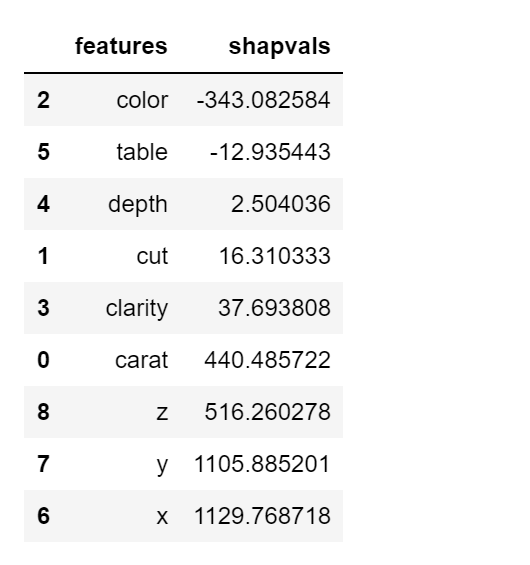
Это все вклады отдельных функций, которые необходимо получить от базового значения к выходному значению из записи (то есть отдельного элемента в наборе данных), отображаемого в виде графика силы на рисунке 1. Вы можете видеть, что есть положительные и отрицательные вклады разной величины. . В этом случае x, y, z, карат, четкость, огранка и глубина - все они способствуют увеличению значение от базового значения до значения, предсказанного выходными данными модели, тогда как цвет и таблица способствуют уменьшению величины от базового значения до предсказанного. Также обратите внимание, что единица значений SHAP совпадает с фактическим целевым значением (ценой).
Вот как вы получите выходное значение:
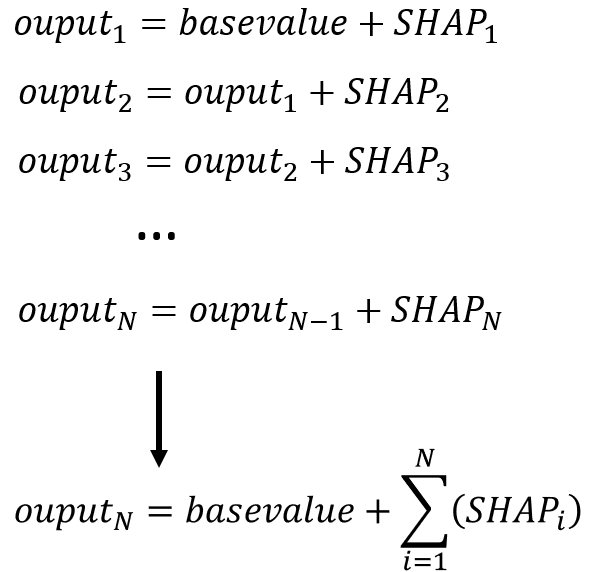
Попробуйте добавить их, и вы увидите, что выходное значение равно фактическому прогнозируемому значению модели. Это очень мощный и проницательный метод интерпретации, который поможет вам понять вклад в единицах целевых переменных.
Теперь, если вы хотите увидеть общий вклад каждой переменной функции, вы просто выполните:
Построение средних значений вкладов дает вам рисунок 3, на котором показан средний вклад каждой характеристической переменной в общий средний выходной сигнал модели.

Дополнительный бонус: LIME и Submodular Pick (SP) -LIME
На всякий случай попробуем более старый, но тоже интересный подход.
LIME - это алгоритм, представленный в статье Марко Тулио Рибейро и др. Почему я должен вам доверять?: Объяснение прогнозов любого классификатора. в 2016 году.
LIME - это умный алгоритм, который обеспечивает интерпретируемость любого классификатора или регрессора черного ящика путем выполнения локальной аппроксимации индивидуального прогноза с использованием интерпретируемой модели (т.е. в данном бумажном случае это линейная модель и т. д.) . То есть он отвечает на вопрос : достаточно ли я доверяю индивидуальному прогнозу, чтобы предпринять действия на его основе? Итак, это хороший алгоритм для проверки или отладки индивидуальных прогнозов.
SP-LIME - это алгоритм, который пытается ответить на вопрос Доверяю ли я модели? Он делает это, формулируя проблему как проблему подмодульной оптимизации. То есть он выбирает серию экземпляров модели и соответствующие им прогнозы таким образом, чтобы они представляли производительность всей модели. Эти выборы выполняются таким образом, что входные функции, которые объясняют больше различных случаев, имеют более высокий балл важности.
Результат от LIME:

Мы можем видеть, что характеристики x, y, z, карат, чистота, огранка и глубина вносят положительный вклад в модель LIME, хотя и не в том же порядке, что и SHAP (но они почти очень похожи). Кроме того, таблица характеристик и цвет имеют отрицательный вклад в модель LIME, подтверждая также результаты значений SHAP.
Результат от SP-LIME:
Чтобы рассчитать общий вклад, мы должны использовать SP-LIME. Это немного утомительнее, так как нам нужно вычислить матрицу объяснения и получить среднее значение для каждой функции вручную. Я использую sample_size, равный 20, и количество экспериментов, равное 5, так как алгоритм оптимизации SP требует больших затрат в оперативной памяти.

Общая атрибуция SP-LIME немного (хотя на самом деле не так уж и сильно) отстает от SHAP, но имейте в виду, что я не оптимизировал параметры для SP-LIME. Скорее всего, это будет в соответствии с SHAP, если я использую больший размер выборки и увеличу количество экспериментов, проводимых алгоритмом SP, как и должно, поскольку LIME, как было продемонстрировано, является алгоритмом типа AFA и является приближением к значениям Шепли.
Заключение:
Я надеюсь, что вы узнали что-то новое, и призываю вас попробовать это в своих наборах данных с помощью различных методов (например, DNN, CNN, catboost и т. Д.). Он также работает для классификации и различных типов данных, таких как данные изображения и текстовые данные. Если возникнут какие-либо вопросы, дайте мне знать на eduardo.denadai [@] gmail.com