Реализация двух методов обработки изображений менее чем в 120 строк кода с использованием Python и OpenCL

Помимо очевидного варианта использования графического процессора (GPU), а именно рендеринга 3D-объектов, также можно выполнять вычисления общего назначения с использованием таких фреймворков, как OpenCL или CUDA. Один из известных вариантов использования - майнинг биткойнов. Мы рассмотрим другой интересный вариант использования: обработка изображений. Обсудив основы программирования на GPU, мы реализуем расширение и размытие менее чем в 120 строк кода с использованием Python и OpenCL.
Почему обработка изображений хорошо подходит для графических процессоров?
Первая причина
Многие операции обработки изображения повторяются от пикселя к пикселю в изображении, выполняют некоторые вычисления с использованием текущего значения пикселя и, наконец, записывают каждое вычисленное значение в выходное изображение. На рис. 1 в качестве примера показана операция инвертирования значений серого. Мы инвертируем оттенки серого каждого пикселя индивидуально. Очевидно, это можно сделать одновременно (параллельно) для каждого пикселя, поскольку выходные значения не зависят друг от друга.

Вторая причина
При обработке изображений нам нужен быстрый доступ к значениям пикселей. Графические процессоры предназначены для графических целей, и одно из них - текстурирование, поэтому оборудование для доступа и управления пикселями хорошо оптимизировано. На рис. 2 показано, для чего обычно используется текстурирование в 3D-программах.

Расширение и эрозия
Давайте кратко рассмотрим применяемые нами методы обработки изображений. Обе операции относятся к классу морфологических операций. Маска (часто называемая элементом структурирования) смещается по входному изображению пиксель за пикселем. Для каждого местоположения максимальное (для расширения) или минимальное (для эрозии) значение пикселя под маской записывается в выходное изображение. На рис. 3 показано, как вычисляется расширение.

Чтобы получить представление об обеих операциях, взгляните на рис. 4. Далее, на рис. 5 показано изображение в оттенках серого и его размытая версия.

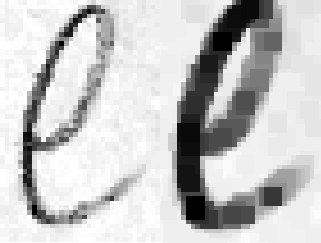
Использование параллелизма графических процессоров
Как вы видели, при применении дилатации или эрозии маска смещается по изображению. В каждом месте применяется одна и та же основная операция (выбор набора пикселей по маске, максимальное или минимальное значение вывода в пикселях). Кроме того, выходные пиксели не зависят друг от друга.
Это предлагает реализовать базовую операцию как функцию на входном изображении с дополнительным аргументом для местоположения. Затем мы вызываем функцию для всех возможных местоположений (x между 0 и шириной-1, y между 0 и высотой-1) одновременно (параллельно), чтобы получить выходное изображение.
Давайте сначала выполним реализацию псевдокода: либо мы вызываем synchronous_work (image), либо перебираем все (x, y) местоположения, применяя одну и ту же операцию на каждом шаге итерации. Или мы вызываем parallel_work (image, x, y) с его дополнительными аргументами местоположения для всех местоположений параллельно (например, путем запуска потока для каждого экземпляра). На рис. 6 показано, как значения выходных пикселей вычисляются параллельно.
Синхронная реализация:
synchronous_work(image):
for all (x, y) locations in image:
1. select pixels from 3×3 neighborhood of (x, y)
2. take maximum (or minimum)
3. write this value to output image at (x, y)
in main: run one instance of synchronous_work(image)
Параллельная реализация:
parallel_work(image, x, y): 1. select pixels from 3×3 neighborhood of (x, y) 2. take maximum (or minimum) 3. write this value to output image at (x, y) in main: run one instance of parallel_work(image, x, y) for each (x, y) location in the image at the same time

Реализация OpenCL
Давайте перенесем наш псевдокод так, чтобы он работал на реальном графическом процессоре: мы будем использовать платформу Open Computing Language (OpenCL). На рис. 7 показано, что делает наша реализация: сначала мы копируем наше входное изображение в графический процессор, компилируем ядро (программу графического процессора), выполняем его для всех местоположений пикселей параллельно и, наконец, копируем полученное изображение обратно из графического процессора.
Нам нужно реализовать одну программу для хоста и одну для устройства:
- ЦП («хост»): программа Python, которая устанавливает OpenCL, передает данные между ЦП и ГП, заботится об обработке файлов и т. Д.
- GPU («устройство»): ядро OpenCL, которое выполняет фактическую обработку изображений с использованием языка C-подобного.

Начиная
- OpenCL установлен и работает
- pyopencl установлен и работает
- Клонировать репозиторий с GitHub
Программа ЦП (хост)
Большие части кода ЦП или хоста можно рассматривать как шаблонный код. Настройка основных структур данных OpenCL в большинстве случаев выполняется одинаково. Кроме того, подготовка входных и выходных данных следует определенному шаблону, то же самое относится к компиляции, выполнению и передаче данных программы GPU. Вы должны иметь возможность реализовать другие алгоритмы, такие как обнаружение границ или регулировка яркости, используя предоставленный код, не затрагивая программу ЦП. Давайте быстро пройдемся по основным этапам. Цифры в скобках соответствуют номерам в коде для облегчения навигации.
(1) Сначала необходимо выполнить инициализацию OpenCL:
- Выберите платформу: платформа соответствует установленному драйверу, например AMD
- Выберите устройство с графическим процессором из выбранной платформы: у вас может быть установлено несколько графических процессоров. Мы просто берем первую запись в списке графических процессоров
- Создайте объект cl.Context: этот объект связывает воедино всю необходимую информацию (выбранное устройство, данные и т. Д.) Для запуска программы GPU.
- Создайте объект очереди команд типа cl.CommandQueue: этот объект представляет собой очередь FIFO, которая позволяет нам выдавать команды для отправки / получения данных в / из графического процессора, а также позволяет нам выполнять программы на графическом процессоре
(2) Подготовьте данные:
- Прочитать изображение из файла в numpy image
- Выделите выходное numpy изображение того же размера, что и заполнитель. Позже мы заполним его результатом работы графического процессора.
- Создайте буферы типа cl.Image, которые содержат данные изображения для OpenCL.
(3) Подготовьте программу на графическом процессоре (на рис. 8 показана иерархия объектов, представляющая программу на графическом процессоре):
- Считать исходный код программы GPU из файла и создать из него объект cl.Program
- Скомпилируйте программу с помощью метода cl.Program.build
- Создайте объект ядра типа cl.Kernel, который представляет точку входа нашей программы GPU.
- Задайте аргументы функции ядра: это связь между данными в нашей программе CPU и данными, доступными в программе GPU. Мы передаем буферы входного и выходного изображения, а также целое число, указывающее, хотим ли мы применить растяжение (= 0) или эрозию (= 1). Мы используем метод cl.Kernel.set_arg и указываем как индекс аргумента ядра (например, 0 соответствует первому аргументу в списке аргументов нашей функции ядра), так и данные процессора.

(4) Выполните программу графического процессора и передайте данные:
- Выполните команду для копирования входного изображения во входной буфер, используя cl.enqueue_copy
- Выполнение программы графического процессора (ядра): мы реализовали морфологическую операцию на уровне пикселей, поэтому мы будем выполнять экземпляр нашего ядра для каждого местоположения (x, y). Эта комбинация данных и ядра называется рабочим элементом. Количество элементов, необходимых для обработки всего изображения, равно ширине * высоте. Мы передаем и ядро, и размер изображения функции cl.enqueue_nd_range_kernel для выполнения рабочих элементов.
- Когда программа GPU завершает свою работу, мы копируем данные обратно из выходного буфера в выходное изображение с помощью cl.enqueue_copy (и ждем, пока эта операция не завершится, чтобы вернуть заполненное выходное изображение в вызывающую функцию Python)
Подводя итог: мы настраиваем OpenCL, подготавливаем буферы входного и выходного изображения, копируем входное изображение в графический процессор, параллельно применяем программу графического процессора к каждому местоположению изображения и, наконец, считываем результат обратно в программу центрального процессора.
Программа GPU (ядро, работающее на устройстве)
Программы OpenCL GPU написаны на языке, аналогичном C. Точка входа называется функцией ядра, в нашем случае это функция morphOpKernel (…). Его аргументы соответствуют аргументам, которые мы задаем в программе ЦП. В ядре необходимо получить доступ к идентификаторам рабочих элементов. Вы помните: рабочий элемент - это комбинация кода (ядра) и данных (в нашем случае расположение изображения). При вызове cl.enqueue_nd_range_kernel в программе ЦП мы указали, что нам нужен один рабочий элемент для каждого местоположения (x, y) в изображении. Мы получаем доступ к идентификаторам рабочих элементов с помощью функции get_global_id. Поскольку у нас есть два измерения (потому что изображение имеет два измерения), мы получаем идентификаторы для обоих измерений. Первый идентификатор соответствует x, второй - y. Теперь, когда мы знаем расположение пикселя, мы можем прочитать значения пикселей в окрестности 3 × 3, вычислить выходное значение и, наконец, записать его в то же место в выходном изображении.
(1) Ядро:
- Точка входа при выполнении программы GPU (также могут быть подфункции, вызываемые ядром)
- Мы передаем ядру входное изображение только для чтения и выходное изображение только для записи. Кроме того, мы передаем целое число, которое сообщает нам, нужно ли нам применять растяжение (= 0) или эрозию (= 1).
(2) Глобальные идентификаторы идентифицируют рабочий элемент и в нашем случае соответствуют координатам x и y.
(3) Структурирующий элемент (маска) реализуется двумя вложенными циклами, которые представляют собой квадратную окрестность 3 × 3 вокруг центрального пикселя.
(4a) Доступ к пиксельным данным осуществляется с помощью функции read_imagef, которая возвращает вектор из 4 чисел с плавающей запятой. Для изображений со значением серого нам нужен только первый компонент, который мы можем проиндексировать с помощью s0. Это значение с плавающей запятой между 0 и 1, представляющее значение серого пикселя. Мы передаем в эту функцию изображение, расположение пикселя и семплер. Сэмплер позволяет делать такие вещи, как интерполяция между пикселями, но в нашем случае сэмплер не делает ничего, кроме возврата значения пикселя в заданном месте.
(4b) Пробоотборник определяется комбинацией опций. В нашем случае мы хотим, чтобы сэмплер использовал ненормализованные координаты (переход от 0 к ширине-1 вместо перехода от 0 к 1). Кроме того, мы отключаем интерполяцию между пикселями (поскольку мы не делаем выборку между местоположениями пикселей), а также определяем, что происходит, когда мы получаем доступ к местоположениям за пределами изображения.
(5) В зависимости от операции мы ищем наибольшее / наименьшее значение пикселя в окрестности 3 × 3.
(6) Запишите результат в выходное изображение. Опять же, мы указываем изображение и местоположение. Нам нужно передать вектор из 4 чисел с плавающей запятой, но нам нужно заполнить только первую запись, потому что наше изображение имеет серые значения.
Попробуй это
Выполните python main.py, который применяет обе операции к входному изображению, показанному на рис. 9. После выполнения в каталоге появляются два файла: dilate.png и erode.png, представляющие результаты расширения и эрозия.

Что происходит за кулисами?
Мы создаем рабочий элемент для каждого пикселя, как показано на рис. 10. Графический процессор запускает какой-то аппаратный поток для каждого рабочего элемента, который будет обрабатываться параллельно. Конечно, количество одновременно активных потоков ограничено оборудованием. Интересной особенностью является то, что эти потоки не являются полностью независимыми: существуют группы потоков, выполняемых в режиме блокировки и применяющих одну и ту же операцию к разным экземплярам данных (SIMD). Следовательно, ветвление в ядре (if-else, switch-case, while, for) может замедлить выполнение: графический процессор должен обрабатывать обе ветви для всех потоков, выполняемых в шаге блокировки, даже если расходится только один поток.

На графических процессорах существуют разные типы параллелизма (например, использование векторных типов, разделение данных и применение операции к каждому элементу данных параллельно,…). Мы использовали только один из этих типов, разделив данные на уровне пикселей и вычислив выходные данные для каждого местоположения пикселя отдельно.
Если вы внимательно посмотрите на программу графического процессора, вы можете заметить, что переменные имеют разные адресные пространства: входное и выходное изображение глобально видны для всех рабочих элементов, в то время как переменные, используемые в качестве блокнота внутри функции, видны только для работы. -item экземпляр. Эти адресные пространства соответствуют базовому оборудованию. Приведу пример: изображения обрабатываются текстурными блоками и их семплерами. Эти блоки также используются для текстурирования 3D-объектов в играх и подобных приложениях.
дальнейшее чтение
Если вы хотите глубже понять программирование на GPU и OpenCL, прочтите хорошую книгу по этой теме. Существует множество вариантов использования, которые можно эффективно вычислить на графическом процессоре, не только такие известные, как обработка изображений и добыча биткойнов.
Я рекомендую книгу [1], чтобы вы начали работать с OpenCL. Книга начинается с простых программ, таких как умножение 4D матрицы на вектор, и заканчивается сложными темами, такими как БПФ или битонная сортировка.
Кроме того, книгу [2] тоже стоит прочитать, но она уже предполагает некоторый опыт работы с OpenCL.
В зависимости от вашего графического процессора вы можете найти информацию о его реализации OpenCL, чтобы лучше понять, как OpenCL транслируется на оборудование, например см. [3] для AMD.
Khronos предоставляет спецификацию [4] и очень полезную справочную карту API [5].
[1] Скарпино - OpenCL в действии
[2] Гастер и др. - Гетерогенные вычисления с OpenCL
[3] AMD Accelerated Parallel Processing - Руководство по программированию OpenCL
[4] Khronos - Спецификация OpenCL
[5] Khronos - Справочная карта OpenCL API