
В Dia мы с нуля создали многие собственные инструменты для внутренних операций, такие как системы управления запасами и хранилищами на Rails, Postgres и AWS.
В нашей системе управления запасами мы управляем тысячами продуктов и стилей. Мы также отслеживаем каждый предмет из нескольких миллионов предметов одежды, которые были введены в нашу систему инвентаризации.
Особенность: Массовая загрузка через CSV
Нам было поручено создать функцию, позволяющую нашей команде по мерчандайзингу массово загружать новые товары, приобретенные у различных поставщиков, через файл CSV.
До появления этой функции нашей команде товаров приходилось вручную добавлять новые стили в нашу систему один за другим.
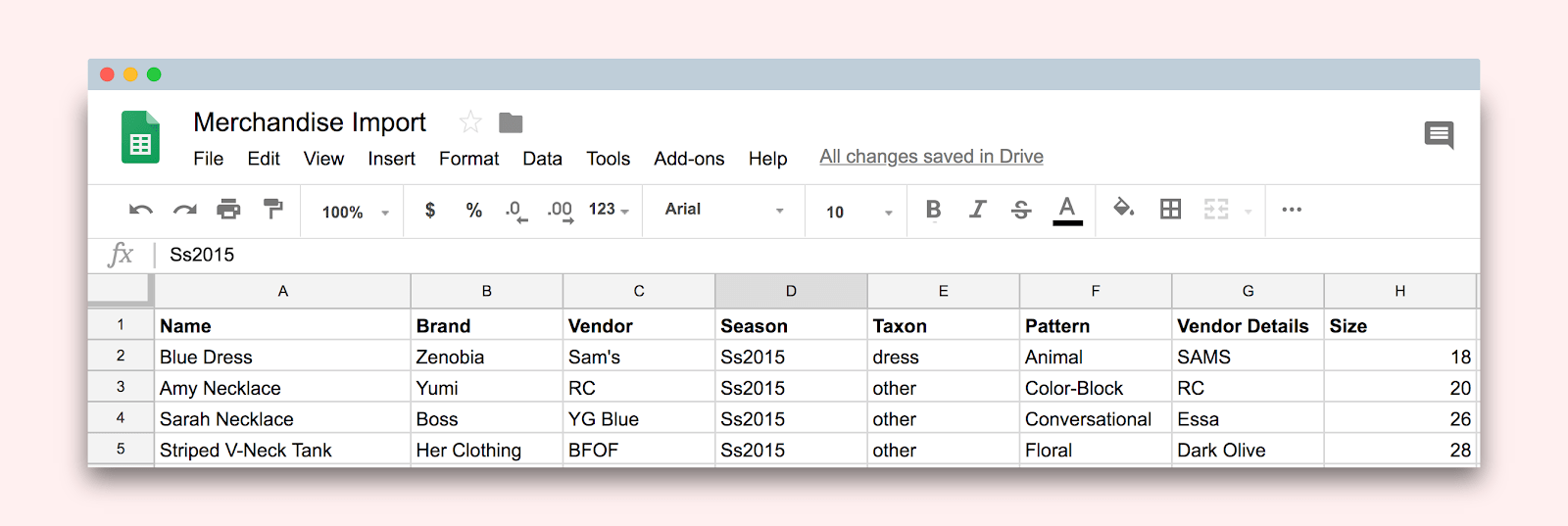
Сложность и связь со связями
У наших стилей есть много требуемых свойств, включая цвет, размер, узор, марку и т. Д.
Наличие этой логики, встроенной в CSV, создает много места для ошибок при импорте, потому что многие свойства наших стилей - это не просто строковые столбцы в нашей базе данных - они часто представляют собой ассоциации, представленные внешним ключом.
Например, на изображении выше данные в столбце шаблона представлены именем. Когда мы загружаем CSV, мы должны запросить нашу таблицу шаблонов независимо, чтобы убедиться, что шаблон с таким именем существует.
Есть много сценариев, когда что-то может пойти не так при импорте CSV. Мы хотели, чтобы модульные тесты были надежными, но при этом оставались гибкими и поддерживаемыми.
Сказать "нет светильникам"
Традиционный способ тестирования файлов CSV в рельсах - это приспособления. Приспособления - это способ организации данных, которые вы хотите проверить, - они также сохраняются в виде отдельного файла в вашем репозитории.
Мы быстро обнаружили, что приспособления недостаточно гибкие, потому что:
- Нам понадобятся десятки файлов фикстур для обработки множества различных случаев.
- Может быть сложно поддерживать фикстуры. Если мы добавим дополнительный столбец или изменим значение столбца со строки на целое число, нам придется обновить все файлы фикстур.
- Может быть сложно разобраться с вашими тестовыми случаями, поскольку данные хранятся в другом файле.
Более гибкое решение
Мы придумали решение для создания файлов CSV на лету и определения наших тестовых данных в нашем файле спецификации.
На высоком уровне мы:
- Определите строки и столбцы потенциального сценария CSV.
- Запишите эти данные в настоящий CSV-файл.
- Запустите этот CSV через наш класс импорта CSV.
- Проверьте результаты с помощью RSpec.
- Удалите файл.
Это позволяет нам запускать сотни различных сценариев CSV за один раз.
Нарушение кода
Определение столбцов и строк с помощью RSpec:
Это дает большую гибкость. Например, мы можем захотеть изменить только одну вещь в row2 в другом сценарии. Для этого мы можем добавить еще один let вызов внутри нового контекста:
Создание CSV:
С нашими определенными строками мы создаем CSV-файл внутри файловой системы.
Мы сохраняем его в каталоге /tmp под test.csv.
Фактическое тестирование CSV:
Это реальный класс, который мы тестируем, и все, что нам нужно сделать, это передать путь к файлу, поскольку мы всегда сохраняем наш файл там прямо перед запуском этого кода.
Удаление файла:
После каждого теста мы удаляем файл на всякий случай.
Проверка результатов
Имея этот код, мы написали реальные тесты бизнес-логики.
Для нас это означало тестирование на уровне базы данных, чтобы убедиться, что записи создаются / обновляются должным образом. А для отрицательных сценариев мы проверили, что правильные ошибки проверки фиксируются и представляются пользователю.
Ограничения нашего подхода
У большинства технических решений часто есть недостатки.
Это решение было побочным продуктом одной загрузки CSV, попытки сделать слишком много вещей. Когда у вас так много разных сценариев ввода данных, код может стать запутанным, что приведет к ошибкам, поскольку большая часть бизнес-логики инкапсулирована в одном классе Ruby.
По этой причине мы работаем с нашей командой разработчиков, чтобы разбить загрузку на несколько более мелких, более конкретных загрузок, чтобы мы могли разделить часть логики процессора CSV на более обслуживаемые фрагменты.
По мере того, как функция становится более сложной, важно учитывать это разделение задач.