
Код этого эксперимента доступен в моем репозитории на github здесь https://github.com/akanimax/MSG-GAN.
Контрольные точки обученных моделей доступны по адресу https://drive.google.com/drive/folders/119n0CoMDGq2K1dnnGpOA3gOf4RwFAGFs
Мотивация
Отрывок из статьи Progressive Growing of GANs:
Когда мы измеряем расстояние между обучающим распределением и сгенерированным распределением, градиенты могут указывать на более или менее случайные направления, если распределения не имеют существенного перекрытия, т.е. их слишком легко отличить друг от друга.
Создание изображений с высоким разрешением затруднено, потому что более высокое разрешение позволяет легче отличить сгенерированные изображения от обучающих изображений, что резко усугубляет проблему градиента.
Это подчеркивает проблему, связанную с созданием изображений с высоким разрешением с использованием GAN. В документе предлагается решение этой проблемы путем введения послойного обучения GAN. Послойное обучение смягчает проблему градиента, делая градиенты с более высоким разрешением значимыми, сначала приближая распределения с более низким разрешением к реальным распределениям.
Я, с другой стороны, понял, что может быть другое решение этой проблемы, помимо предложенного послойного обучения. Мое предлагаемое решение таково: «Градиенты дискриминатора должны достигать всех различных масштабов (разрешений) в генераторе». В следующем разделе я объясню, как этого добиться.
MSG-GAN
Вместо того, чтобы постепенно наращивать GAN, мы одновременно загружаем в GAN все различные масштабы сгенерированных сэмплов и исходных сэмплов. Это приводит к подключению промежуточных уровней Генератора к промежуточным уровням Дискриминатора, что напоминает архитектуру, подобную «U-Net».

Как показано на приведенной выше диаграмме, я понижаю дискретизацию исходных изображений до соответствующих разрешений, чтобы объединить их с активациями нормальных сверточных слоев. Поскольку есть соединения непосредственно от слоев генератора к дискриминатору, градиенты текут на все слои одновременно. Вначале, как и ожидалось, градиенты нижних слоев более ощутимы, чем более высокие, и в конечном итоге они делают градиенты более высоких слоев более подходящими для соответствия требуемому распределению.

На рисунке выше показано, как значимые градиенты проникают в генератор снизу вверх. Первоначально значимы только градиенты с более низким разрешением и, таким образом, начинают генерировать хорошие изображения с этими разрешениями, но в конечном итоге все шкалы синхронизируются и начинают создавать изображения. Это приводит к более стабильной тренировке для более высокого разрешения.
Селеба Эксперимент
Я провел эксперимент по обучению предлагаемой сети на Celeba Dataset. На видео выше показан интервал времени, который я приобрел во время тренировки. Как и ожидалось, сгенерированные изображения в различных масштабах Генератора фактически синхронизированы и представляют собой субдискретизированные версии сгенерированного изображения с самым высоким разрешением.
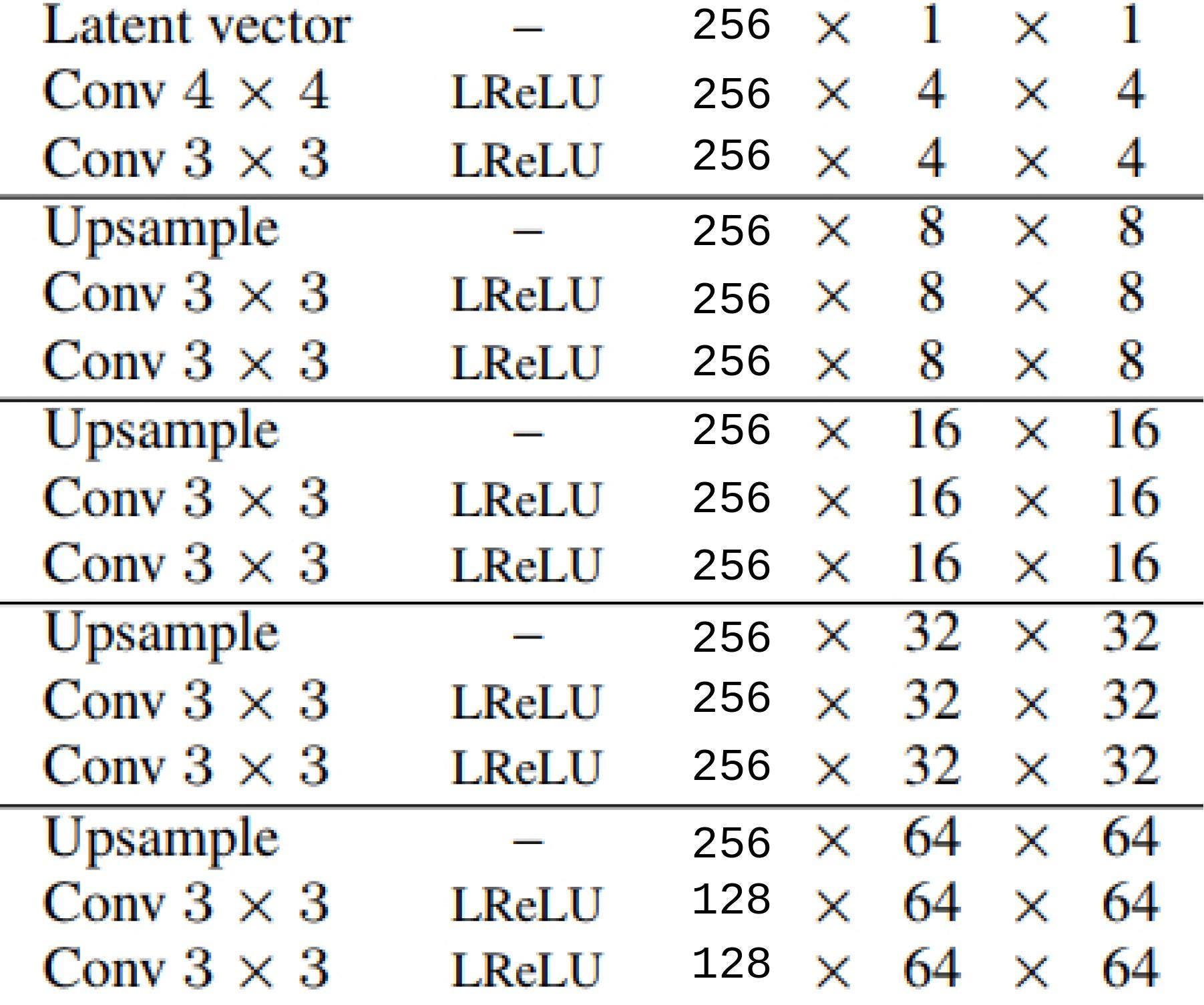
Вы можете найти более подробную информацию об архитектуре на диаграмме выше. Я использовал релятивистскую версию Hinge-GAN Loss для обучения сети. На следующей диаграмме показан график потерь генератора и дискриминатора, записанных во время обучения.

Вначале есть некоторые отклонения от нормы, но позже тренировка прошла гладко.
Мне удалось сгенерировать изображения с разрешением 64 x 64 на моем графическом процессоре с относительно небольшой сетью, но я определенно хотел бы увидеть, каковы результаты для более высоких разрешений. Вы определенно можете попробовать это на своем графическом процессоре и открыть PR со своими результатами. Просто увеличьте глубину в коде с 5 (соответствует 64 x 64) до 9 (для 1024 x 1024) и latent_size от 256 до 512 для соответствия архитектуре ProGAN.
Еще одна деталь, которую я хотел бы здесь упомянуть, заключается в том, что в своей архитектуре я не использую какие-либо методы обеспечения стабильности, предложенные в статье ProGAN, а именно: «Pixel-norm» , «уравненная скорость обучения» и «экспоненциальный скользящий средний вес для генератора». Я использовал только слой MinibatchStd из статьи ProGAN и применил спектральную нормализацию ко всем сверточным весам в сети.
Последние мысли
Я считаю, что этот подход с использованием многомасштабных градиентов от дискриминатора можно использовать для создания изображений с более высоким разрешением, поскольку обучение всех масштабов синхронизировано, и обучение показывает черты, которые очень похожи на ProGAN.
Я буду работать над использованием уровня полного внимания из моего предыдущего блога FAGAN (который является вариантом SAGAN) в этой архитектуре для дальнейшего улучшения. Пожалуйста, дайте мне знать, что вы думаете об этой технике.
Не стесняйтесь оставлять отзывы / улучшения / предложения. Мы приветствуем вклад в код / технику.
Спасибо за чтение!