Этот пост изначально был размещен на ishankhare.com
Как работают хэш-карты?
Хорошо, давайте начнем с хэш-карт?
Хэш-карты или хэш-таблицы известны под разными именами на разных языках.
- В Python есть dict / словари
- Руби называет это Hash.
- В Java есть хэш-карта
- В C ++ есть unordered_map
- Даже в Javascript есть карты, именно так в основном объекты реализуются в javascript. (просто посмотрите JSON)
То, что в последнем пункте говорится об использовании хэш-карт для реализации объектов в Javascript, также верно в случае Python, Ruby и некоторых других.
Итак, hashmaps / dicts / hashtables, как бы вы их ни называли, в основном представляют собой структуры данных для хранения значений ключа. Вы передаете значение, идентифицированное ключом, и можете вернуть то же значение с помощью этого ключа - просто вот так.
Итак, давайте попробуем разобраться, как это выглядит в коде.
Это дает нам список основных операций над dict:
- вставлять
- Обновить
- Удалить
То же самое можно показать с помощью Javascript:
Хватит примеров, давайте посмотрим, как эти вещи работают изнутри.
Итак, мы будем реализовывать простую хеш-таблицу в Голанге. Если вы не слышали и не писали код на Go и скептически относитесь к пониманию следующего кода - не беспокойтесь, синтаксис Go очень похож на C и Javascript. И если вы умеете кодировать (на каком-либо языке), у вас все в порядке!
Строительные блоки
Это изображение, взятое из Википедии, показывает базовую структуру нашей хеш-таблицы. Это поможет нам лучше понять и разобраться в проблеме:

Подводя итог, мы имеем:
- хеш-функция
- линейный массив, которому хэш-функция сопоставляет
- и фактические узлы данных, которые содержат наши пары "ключ-значение"
Массив
Итак, начнем с нашего линейного массива. Итак, нам в основном нужен статически распределенный массив некоторого размера n. Это будет массив, содержащий указатель на наши фактические пары ключ-значение. Вот как будет выглядеть наш базовый массив:
Давайте запрограммируем это на Go. Чтобы иметь базовый массив внутри нашего типа данных hashmap. Достичь этого будет довольно легко.
Приведенный выше код поясняется ниже:
- Мы объявляем текущий файл основным пакетом с помощью package main.
- Мы импортируем пакет под названием «fmt», позже мы будем использовать его для вывода данных на терминал.
- Мы объявляем константу переменной
MAP_SIZEсо значением50. Это будет размер нашего линейного массива.
Для простоты мы предполагаем, что у нас есть просто массив фиксированного размера, который мы используем для реализации нашей хэш-карты, и мы не принимаем во внимание изменение размера. Фактические реализации действительно учитывают тезисы, которые будут рассмотрены в следующем сообщении в блоге. Более подробная информация находится здесь.
4. Затем мы создаем функцию NewDict, которая создает для нас этот массив и возвращает ему указатель.
На этом наша базовая структура самого массива завершена. Но перед нами стоит следующий вызов. То есть, как представить пары ключ-значение, которые содержат наши фактические данные, и связать их с нашим массивом.
Создание узлов и связывание с массивом
В представленном выше коде есть одна проблема - мы создали массив указателя на целые значения. Обычно Data []*int на строке8. Это неправильно, потому что на самом деле нам нужно не указывать на целые числа, а на некоторый объект, содержащий наши пары "ключ-значение". Мы еще не знаем, что это за объект, но мы знаем, что для него нужны как минимум два поля - ключ и значение. Итак, давайте продолжим и создадим эту новую структуру объекта в нашем коде.
Добавляем следующие строки:
type Node struct {
key string
value string
next *Node
}
Мы создаем структуру для хранения наших пар "ключ-значение" и указателя на тип узла. Этот указатель нам понадобится позже, чтобы иметь дело с конфликтами хешей. Подробнее об этом позже, а пока просто оставьте его там.
Теперь, поскольку мы хотим, чтобы каждый индекс нашего массива указывал на этот узел тип, мы должны изменить тип нашего массива данных.
type HashMap struct {
Data []*Node
}
В конце этих изменений наш код должен выглядеть следующим образом:
package main
import "fmt"
const MAP_SIZE = 50
type Node struct {
key string
value string
next *Node
}
type HashMap struct {
Data []*Node
}
func NewDict() *HashMap {
return &HashMap{ Data: make([]*Node, MAP_SIZE) }
// we initialize our array with make(), see
// https://golang.org/pkg/builtin/#make
}
func main() {
a := NewDict()
fmt.Println("%q", a)
}
Если вы запустите эту программу прямо сейчас, вы должны увидеть что-то вроде этого:
&{[<nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil> <nil>]}
У нас есть объект хэш-карты, состоящий из массива из 50 указателей, каждый из которых указывает на <nil>, что эквивалентно следующему:
NULLin C.nullна Java.Noneна Python.undefinedв Javascript.
Это как и ожидалось, мы не вставили никакого значения в хеш-таблицу, поэтому все указатели указывают на null / nil. Затем нам нужно подумать о вставке объектов в нашу хэш-карту.
Прежде чем мы сможем достичь этого, нам нужно найти способ преобразовать наши ключи в соответствующие индексы в массиве.
Типичная реализация хэш-карт полагается на хорошую хеш-функцию. Задача хеш-функции - преобразовать переданное ей значение (в нашем текущем случае - строку) и вернуть целочисленное значение, представляющее индекс в массиве. И это целочисленное значение должно каждый раз быть одинаковым.
Это означает, что если hash("hello") дает мне 966170508347869221, то каждый раз, когда я передаю "hello", я должен получать то же самое 966170508347869221 в качестве возвращаемого значения.
Вы можете проверить вышесказанное в интерпретаторе Python. Python имеет встроенную функцию
hash, которая возвращает хеш-значение.
Но у нас не может быть индекса 966170508347869221 в нашем массиве. В настоящее время доступны только 1-49 индексы. Значит, нужно как-то довести его до этого диапазона.
Modulo спешит на помощь
Самым простым решением этой проблемы является использование оператора по модулю (%). Этот оператор дает нам остаток от выполненного деления. То есть, если 966170508347869221/50 = 19323410166957384 + 21
тогда 966170508347869221% 50 = 21. Остаток.
Но с этим у нас есть другая проблема: будут ключи, которые будут сопоставлены с одним и тем же индексом, следовательно, мы получим коллизии.
С этого момента у нас есть 3 проблемы, которые нужно решить:
- Как вы реализуете хеш-функцию.
- Сделайте так, чтобы значение хеш-функции попало в диапазон нашего массива.
- Как управлять хеш-коллизиями.
Начнем сначала с функции генерации хешей.
Выбор алгоритма хеширования
В Википедии есть список множества hash_functions. На что вы можете сослаться здесь https://en.wikipedia.org/wiki/Hash_function#List_of_hash_functions
Для нашей цели мы будем использовать хеш-функцию Дженкинса. Это хеш-функция, которая производит 32-битные хэши. В статье в википедии также есть реализация алгоритма на C. Мы просто переведем это на наш код go.
func hash(key string) (hash uint32) {
hash = 0
for _, ch := range key {
hash += uint32(ch)
hash += hash << 10
hash ^= hash >> 6
}
hash += hash << 3
hash ^= hash >> 11
hash += hash << 15
return
}
Вышеупомянутая функция использует именованный возврат - см. Https://golang.org/doc/effective_go.html# named-results
Теперь наш код должен выглядеть так:
Сопоставление хэша с нашим массивом
Теперь, когда мы нашли способ преобразовать наши ключи в хеш-значение, теперь нам нужно убедиться, что это значение попадает в наш массив. Для этого мы реализуем функцию getIndex:
func getIndex(key string) (index int) {
return int(hash(key)) % MAP_SIZE
}
Таким образом, мы позаботились о двух из трех формулировок проблемы. Третья проблема - управление коллизиями будет решено на более позднем этапе. Сначала нам нужно сосредоточиться на вставке пар ключ-значение в наш массив. Напишем для этого функцию.
Вставка
Следующая функция использует приемник, который является мощной функцией го.
func (h *HashMap) Insert(key string, value string) {
index := getIndex(key)
if h.Data[index] == nil {
// index is empty, go ahead and insert
h.Data[index] = &Node{key: key, value: value}
} else {
// there is a collision, get into linked-list mode
starting_node := h.Data[index]
for ; starting_node.next != nil; starting_node = starting_node.next {
if starting_node.key == key {
// the key exists, its a modifying operation
starting_node.value = value
return
}
}
starting_node.next = &Node{key: key, value: value}
}
}
Код в основном говорит сам за себя, но мы все равно кратко его рассмотрим.
Сначала мы вызываем getIndex с key, который, в свою очередь, вызывает функцию hash внутренне. Это дает нам index в нашем массиве, где мы можем хранить эту пару "ключ-значение".
Затем мы проверяем, пуст ли индекс, если да, то мы просто сохраняем туда пару K-V. Это выглядело бы примерно так:
+----+
1 | |
+----+
2 | |
+----+ +------------------+
3 | * |---->| Key: Value |
+----+ | Next: nil |
4 | | +------------------+
+----+
5 | |
+----+ +------------------+
6 | * |---->| Key: Value |
+----+ | Next: nil |
7 | | +------------------+
+----+
8 | |
+----+
9 | |
+----+
10| |
+----+Вышеуказанное обозначает if часть нашего кода - когда нет коллизий. Другая часть нашего кода обрабатывает столкновение.
Есть несколько различных способов обработки коллизий в хэш-картах:
- Отдельная цепочка со связанными списками
- Открытая адресация
- Двойное хеширование
Текущий код в блоке else обрабатывает конфликты с помощью метода Раздельное объединение в цепочку со связанными списками.
Метод связанного списка приведет к структуре данных, очень похожей на следующее изображение:
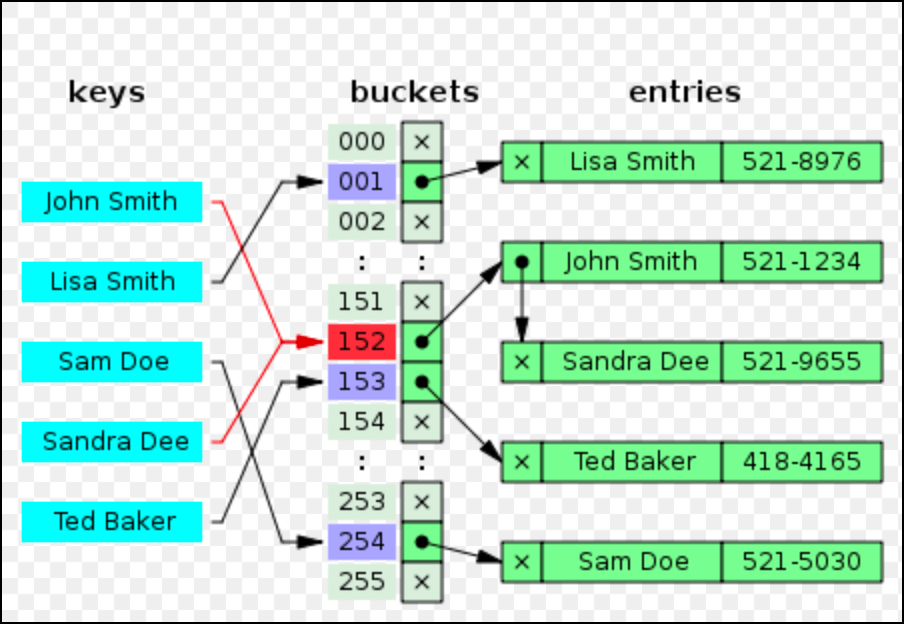
Два ключа, сопоставленные с одним и тем же индексом - следовательно, приводящие к конфликту, показаны красным.
Далее мы поговорим о получении значения из нашей хеш-таблицы.
Принести
Следующая основная операция с хэш-картами, которую мы собираемся рассмотреть, - это Fetch. Выборка довольно проста и идентична вставке - мы передаем наш key в качестве входных данных в хэш-функцию и получаем хеш-значение, которое затем сопоставляется с нашим массивом с помощью функции getIndex.
Тогда мы можем получить 3 возможных результата:
- Мы проверяем, совпадает ли
keyв этом индексе с искомым - если да, то у нас есть совпадение. - Если ключ не совпадает, мы проверяем, является ли его следующее значение не
nil- в основном проверяем наличие коллизий и находим этот элемент в отдельном связанном списке - Если оба вышеуказанных условия не работают, мы соглашаемся, что запрошенный ключ не существует в нашей хэш-таблице.
Код, реализующий приведенное выше объяснение, показан ниже:
func (h *HashMap) Get(key string) (string, bool) {
index := getIndex(key)
if h.Data[index] != nil {
// key is on this index, but might be somewhere in linked list
starting_node := h.Data[index]
for ; ; starting_node = starting_node.next {
if starting_node.key == key {
// key matched
return starting_node.value, true
}
if starting_node.next == nil {
break
}
}
}
// key does not exists
return "", false
}
В приведенном выше коде используется функция golang множественные возвращаемые значения.
После этого мы напишем основную функцию и протестируем реализованные нами операции.
func main() {
a := NewDict()
a.Insert("name", "ishan")
a.Insert("gender", "male")
a.Insert("city", "mumbai")
a.Insert("lastname", "khare")
if value, ok := a.Get("name"); ok {
fmt.Println(value);
} else {
fmt.Println("Value did not match!")
}
fmt.Println(a)
}
Также давайте добавим удобную функцию, которая позволяет нам распечатать нашу хэш-карту в желаемом формате.
func (h *HashMap) String() string {
var output bytes.Buffer
fmt.Fprintln(&output, "{")
for _, n := range h.Data {
if n != nil {
fmt.Fprintf(&output, "\t%s: %s\n", n.key, n.value)
for node := n.next; node != nil; node = node.next {
fmt.Fprintf(&output, "\t%s: %s\n", node.key, node.value)
}
}
}
fmt.Fprintln(&output, "}")
return output.String()
}
Это отменяет вывод на печать по умолчанию для нашего определенного типа HashMap.
Вышеупомянутый метод - это просто удобный метод, используемый для печати всей хэш-карты в красивом формате. Это никоим образом не требуется для правильного функционирования структуры данных
Подводя итог, вот наш последний код:
package main
import (
"fmt"
"bytes"
)
const MAP_SIZE = 10
type Node struct {
key string
value string
next *Node
}
type HashMap struct {
Data []*Node
}
func NewDict() *HashMap {
return &HashMap{ Data: make([]*Node, MAP_SIZE) }
}
func (n *Node) String() string {
return fmt.Sprintf("<Key: %s, Value: %s>\n", n.key, n.value)
}
func (h *HashMap) String() string {
var output bytes.Buffer
fmt.Fprintln(&output, "{")
for _, n := range h.Data {
if n != nil {
fmt.Fprintf(&output, "\t%s: %s\n", n.key, n.value)
for node := n.next; node != nil; node = node.next {
fmt.Fprintf(&output, "\t%s: %s\n", node.key, node.value)
}
}
}
fmt.Fprintln(&output, "}")
return output.String()
}
func (h *HashMap) Insert(key string, value string) {
index := getIndex(key)
if h.Data[index] == nil {
// index is empty, go ahead and insert
h.Data[index] = &Node{key: key, value: value}
} else {
// there is a collision, get into linked-list mode
starting_node := h.Data[index]
for ; starting_node.next != nil; starting_node = starting_node.next {
if starting_node.key == key {
// the key exists, its a modifying operation
starting_node.value = value
return
}
}
starting_node.next = &Node{key: key, value: value}
}
}
func (h *HashMap) Get(key string) (string, bool) {
index := getIndex(key)
if h.Data[index] != nil {
// key is on this index, but might be somewhere in linked list
starting_node := h.Data[index]
for ; ; starting_node = starting_node.next {
if starting_node.key == key {
// key matched
return starting_node.value, true
}
if starting_node.next == nil {
break
}
}
}
// key does not exists
return "", false
}
func hash(key string) (hash uint8) {
// a jenkins one-at-a-time-hash
// refer https://en.wikipedia.org/wiki/Jenkins_hash_function
hash = 0
for _, ch := range key {
hash += uint8(ch)
hash += hash << 10
hash ^= hash >> 6
}
hash += hash << 3
hash ^= hash >> 11
hash += hash << 15
return
}
func getIndex(key string) (index int) {
return int(hash(key)) % MAP_SIZE
}
func main() {
a := NewDict()
a.Insert("name", "ishan")
a.Insert("gender", "male")
a.Insert("city", "mumbai")
a.Insert("lastname", "khare")
if value, ok := a.Get("name"); ok {
fmt.Println(value);
} else {
fmt.Println("Value did not match!")
}
fmt.Println(a)
}
Бег
Выполнив приведенный выше код, мы получим следующий результат:
ishan
{
city: mumbai
name: ishan
lastname: khare
gender: male
}- Первая строка - это значение нашего ключа
name. - Вывод со второй строки и далее - это в основном наша специально закодированная функция pretty-print, которая выводит всю нашу хэш-карту.
Если вы хотите запустить / поэкспериментировать с этим кодом, пожалуйста, поделитесь следующим ответом.
Https://repl.it/@ishankhare07/hashmaps
Сообщение размещено на ishankhare.com