Метод определения статистической взаимосвязи между двумя или более переменными, при котором изменение зависимой переменной связано с изменением одной или нескольких независимых переменных и зависит от него.
Регрессия — это, по сути, алгоритм непрерывного обучения с учителем, который является одним из популярных алгоритмов.
Непрерывные и дискретные данные:
Дискретные данные являются описательными (например, «быстро» или «медленно»), тогда как непрерывные — это числовые значения, вычисляемые на основе их связи с независимой переменной.
Пример линейной регрессии:
Возьмем следующий пример
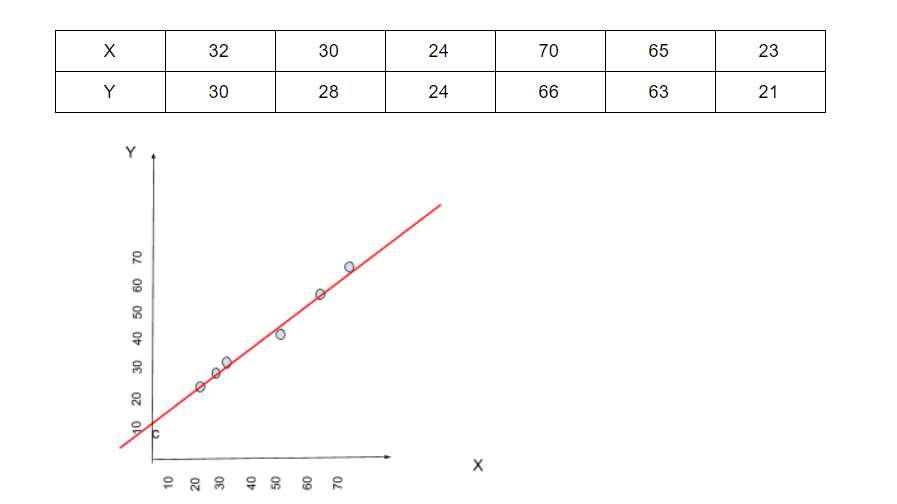
Предположим, что значение Y зависит от X . Приведенный выше график примерно построен для приведенных выше данных.
Здесь красная линия, которая примерно касается всех точек, называется линией регрессии, и вы можете ясно видеть, что линия пересекается в точке «с» на оси Y (пересечение по оси Y).
И если «m» - это наклон линии, то уравнение линии задается следующим образом:
Y= mX+c
На основе этой формулы вы можете предсказать значение Y от X
И это основная идея использования регрессии в ML.
Из приведенного выше графика, поскольку связь между независимыми переменными (X) и зависимой переменной (Y) является линейной, регрессия известна как линейная регрессия.
Данные для обучения:
Мы применяем регрессию к нашим данным и определяем наклон и точку пересечения, и, используя линейную формулу, мы решаем Y для любого заданного X, или мы можем сказать, что наша машина предсказывает Y для любого заданного X.
Ошибки:
Ошибка относится к расстоянию между любой точкой и линией регрессии. Линии регрессии рисуются так, чтобы они проходили от среднего значения
I.e y’ = mx’ + c y’= 𝛴y / n
x’= 𝛴x/ n
n- количество наборов данных
Из-за этого несколько точек в данных в реальном времени могут не точно совпадать с линией, и эти различия являются ошибками.

Среднеквадратическая ошибка:
Это говорит вам, насколько близка ваша линия регрессии к набору точек, удаленных от линии. Он берет расстояние от точек до линии регрессии и возводит их в квадрат. Это расстояние является ошибкой. Возведение в квадрат выполняется для удаления всех отрицательных знаков, если таковые имеются. Это называется MSE, так как вы находите среднее значение набора ошибок.
Этапы расчета MSE:
- Найдите линию регрессии
- Подставьте свои значения X, а затем найдите новые предсказанные значения Y.
- Найдите разницу между прогнозируемым значением и фактическим значением.
- квадрат их
- Сложите все ошибки и найдите среднее значение.
MSE используется для поиска линии наилучшего соответствия. Чем меньше значение, тем лучше результат.
Уравнение:
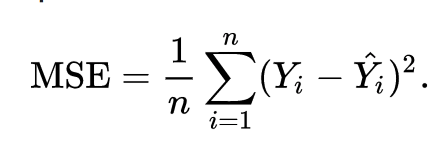
Ошибка R-квадрата:
R-квадрат — это статистическая мера того, насколько данные близки к подобранной линии регрессии. Он также известен как коэффициент детерминации или коэффициент множественной детерминации для множественной регрессии.
Определение R-квадрата довольно простое. Это процент изменения переменной отклика, который объясняется линейной моделью. Или:
R-квадрат = объясненная вариация / общая вариация
R-квадрат всегда находится в диапазоне от 0 до 100%:
- 0% указывает на то, что модель не объясняет никакой изменчивости данных отклика вокруг своего среднего значения.
- 100% указывает, что модель объясняет всю изменчивость данных отклика вокруг своего среднего значения.
Уравнение гипотезы:
hθ(x)=θ0+θ1x
Функция стоимости:
Функция стоимости — это то, что вы хотите минимизировать. Например, ваша функция стоимости может быть суммой квадратов ошибок в вашем тренировочном наборе.
Градиентный спуск:
Этометод нахождения минимума функции нескольких переменных. Таким образом, вы можете использовать градиентный спуск, чтобы минимизировать функцию стоимости. Если ваша стоимость является функцией N переменных, то градиент — это вектор длины N, который определяет конкретное направление, в котором стоимость увеличивается очень быстро.
Чтобы получить отличное объяснение градиентного спуска, посетите первую неделю этого курса Эндрю Н.Г. на Coursera. Советую пройти этот курс :)
https://www.coursera.org/learn/machine-learning

редактировать: rasbt.github.io
Изображение выше является очень четким объяснением градиентного спуска.
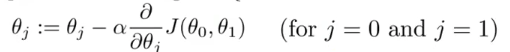
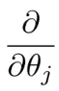
является частной производной функции стоимости, которую нам нужно вычислить.
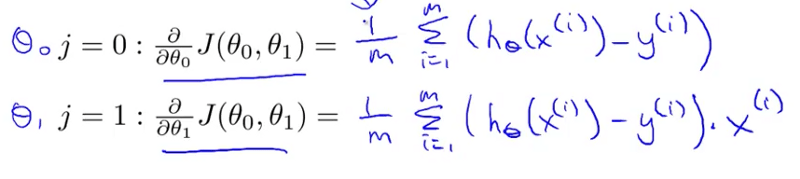
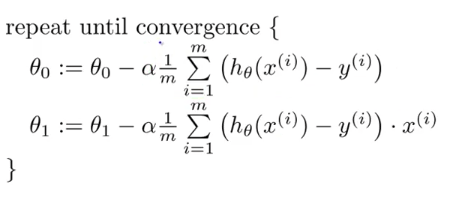
Кредиты: курс Эндрю Н.Г. по машинному обучению на Coursera.
Логистическая регрессия:
В статистике логистическая модель (или модель входа) — это статистическая модель, которая обычно применяется к бинарной зависимой переменной. В регрессионном анализе логистическая регрессия или логическая регрессия оценивает параметры логистической модели. Говоря более формально, логистическая модель — это модель, в которой логарифмические шансы вероятности события представляют собой линейную комбинацию независимых переменных или переменных-предикторов. Два возможных значения зависимой переменной часто обозначаются как «0» и «1», которые представляют такие результаты, как «сдал/не сдал», «победа/поражение», «жив/мертв» или «здоров/больной».
Он использует сигмовидную функцию логистической функции для прогнозирования результата.
Классификация с помощью логистической регрессии:
Это довольно простой и очень полезный алгоритм бинарной классификации (классификация «да/нет», «быстро/медленно», «живой/мертвый» и т. д.). Его также можно использовать для обработки нескольких классов. Такая классификация называется классификацией «один против всех». Один против всех — это, по сути, набор бинарных классификаторов, в которых находится вероятность. Наконец, в качестве окончательного результата выбирается вариант с наибольшей вероятностью.
Сигмовидная функция:
y(z)=11+e-z
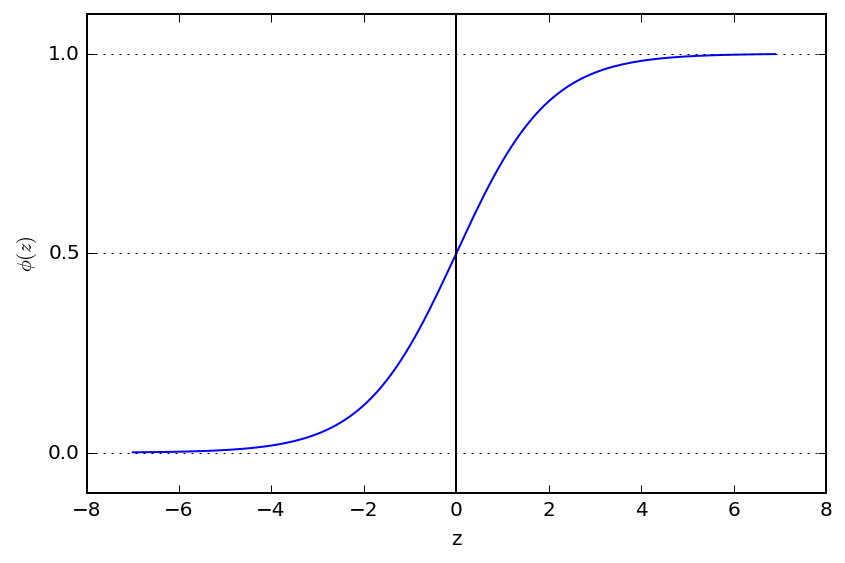
- Если значение y(0)=0,5
- Если y(z)›=0,5, то z ›=0
- Если y(z)‹0,5, то z‹0
- Следовательно, 0,5 — это пороговое значение для бинарной классификации.
- Если y(z)› = 0,5, ответ равен 1 (положительный случай). В противном случае, если y(z)‹0,5, ответ равен 0 (отрицательный случай).
Граница принятия решения:
Он действует как разделение между двумя классами. Линия, определяемая разделением двух областей y(z)=0 и y(z)=1, есть не что иное, как граница решения. Если переменные признаков xi нелинейны, то граница решения также может быть нелинейной.

На приведенном выше рисунке красная линия выступает в качестве границы решения между двумя классами, то есть синими кружками и зелеными треугольниками.
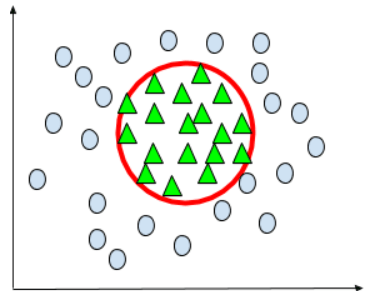
Приведенный выше график представляет собой круговую границу решения, которая разделяет зеленые треугольники и синие кружки.
Классификация "Один против всех":
Мы видели случаи с 2 классами выше.
Теперь рассмотрим случай с 3 классами.

Если мы попробуем класс 1 против всех, мы получим бинарную классификацию, подобную приведенной ниже:

Если мы попробуем класс 2 против всех, мы получим бинарную классификацию, подобную приведенной ниже:
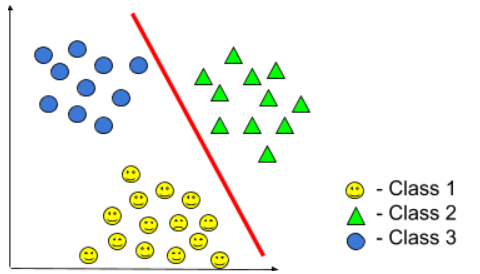
Если мы попробуем класс 3 против всех, мы получим бинарную классификацию, подобную приведенной ниже:
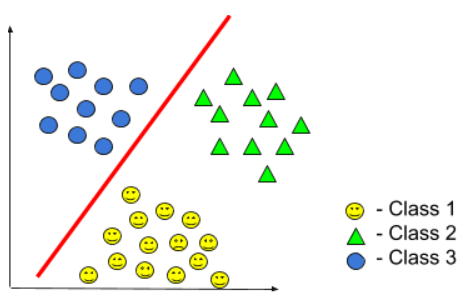
Таким образом, мы находим значение гипотезы во всех трех случаях и выбираем среди них наибольшее значение. Это окончательный ответ, который нам нужен. Поскольку есть 3 класса, это проблема 3 бинарной классификации.
То же самое можно распространить на N случаев. Это будет проблема N бинарной классификации
Другая регрессия:
Линейная и логистическая регрессия являются жесткими и плохо работают, когда набор данных имеет большое количество выбросов, и нам может потребоваться предварительная обработка данных, такая как выбор признаков или PCA, и доступны многие другие типы регрессии, такие как регрессия Лассо, эластичная сеть и т. д.
— Написано Самьюктхой Прабху и Адитьей Шеной.