Подробный учебник по масштабированию PostgreSQL с помощью потоковой репликации (с измерениями производительности)

Примечание: TimescaleDB нанимает! C Разработчики, инженеры-исследователи, специалисты по маркетингу, продажам, евангелизации и другие.
Сегодня PostgreSQL, самая быстрорастущая СУБД 2017 года, популярна как никогда. Тем не менее, разработчики часто по-прежнему предпочитают PostgreSQL нереляционную (или NoSQL) систему, как правило, по одной причине: масштабируемость.
Вот как обычно происходит мыслительный процесс: PostgreSQL - это реляционная база данных; реляционные базы данных сложно масштабировать; нереляционные базы данных легче масштабируются; давайте использовать нереляционную базу данных.
Эти нереляционные системы баз данных могут обеспечивать масштабирование, но также сопряжены со значительными затратами: низкая надежность, низкая производительность запросов (например, отсутствие вторичных индексов), плохое удобство использования (например, пользовательские языки запросов), проблемы с количеством элементов, небольшие экосистемы совместимых инструментов и т. Д.
Ясно, что масштабирование PostgreSQL дает много преимуществ. И как бы ни был популярен PostgreSQL, большинство разработчиков по-прежнему недооценивают его масштабируемость.
Масштабируемость. Это слово постоянно встречается при оценке базы данных, но часто имеет непоследовательные значения. Итак, прежде чем мы продолжим, давайте распакуем его.
Что касается масштабируемости, мы обнаружили, что разработчики обычно ищут комбинацию следующих трех требований:
- Более высокая производительность пластин
- Более высокая производительность чтения
- Высокая доступность (технически не связана с масштабом, но все же часто упоминается как причина)
PostgreSQL уже изначально поддерживает два из этих требований, более высокую производительность чтения и высокую доступность, благодаря функции, называемой потоковая репликация. Поэтому, если пиковая нагрузка вашей рабочей нагрузки составляет менее 50000 вставок в секунду (например, в системе с 8 ядрами и 32 ГБ памяти), у вас не должно возникнуть проблем с масштабированием с PostgreSQL с использованием потоковой репликации.
В этом посте мы обсудим, как масштабировать пропускную способность чтения и обеспечивать высокую доступность в PostgreSQL с помощью потоковой репликации. Затем мы углубимся в несколько поддерживаемых режимов репликации. В заключение приведем некоторые показатели производительности, измеряющие влияние каждого из режимов репликации на производительность вставки и чтения.
В рамках нашего анализа мы включаем числа в TimescaleDB, разработанную нами базу данных временных рядов с открытым исходным кодом, которая как расширение PostgreSQL поддерживает потоковую репликацию из коробки. Важной частью нашего дизайна является обеспечение того, чтобы TimescaleDB имел профиль производительности, аналогичный обычному PostgreSQL для основных функций, таких как репликация, поэтому мы провели дополнительные тесты, чтобы убедиться, что наш дизайн удовлетворяет этому требованию.
(TimescaleDB - это база данных временных рядов с открытым исходным кодом, которая масштабирует любую базу данных PostgreSQL для данных временных рядов. Ее можно установить на существующий экземпляр PostgreSQL или полностью с нуля. Дополнительная информация здесь.)
Примечание. В этом посте основное внимание будет уделено метрикам и концепциям высокого уровня. Практическое руководство по настройке потоковой репликации см. В нашем Руководстве по репликации.
Как работает потоковая репликация PostgreSQL
На высоком уровне потоковая репликация PostgreSQL работает путем потоковой передачи записей об изменениях базы данных с первичного сервера на одну или несколько реплик, которые затем могут использоваться как узлы только для чтения (для масштабирования запросов) или как отработки отказа (для HA).

Потоковая репликация PostgreSQL использует Журнал предварительной записи (WAL). Репликация работает путем непрерывной доставки сегментов WAL от основного к любым подключенным репликам. Затем каждая реплика применяет изменения WAL и делает их доступными для запросов.
Что такое WAL?
Прежде чем мы зайдем слишком далеко в репликацию, давайте сначала разберемся, что такое WAL и почему он у нас есть.
Журнал упреждающей записи - это серия инструкций, предназначенных только для добавления, которые фиксируют каждое атомарное изменение базы данных (то есть каждую транзакцию). Использование WAL - распространенный подход в системах баз данных для обеспечения атомарности и надежности. В частности, очень важна долговечность: это представление о том, что, когда база данных фиксирует транзакцию, полученные данные могут быть запрошены будущими транзакциями, даже в случае сбоя сервера. Здесь на помощь приходит WAL.
Когда мы запускаем запрос, который изменяет данные (или вносит изменения в схему), PostgreSQL сначала записывает это изменение данных в память, чтобы быстро записать изменение. Доступ к памяти очень быстрый, но она также нестабильна, что означает, что в случае сбоя сервера наши последние изменения данных исчезнут после перезапуска сервера. Поэтому нам также нужно в конечном итоге записать изменения в постоянное хранилище. По этой причине существуют периодические моменты времени (называемые «контрольными точками»), когда PostgreSQL записывает любые измененные (или «грязные») страницы памяти на диск.
Однако, прежде чем PostgreSQL выполнит запись в основные файлы данных на диске, он сначала добавляет записи в WAL (также хранящийся на диске). Зачем использовать отдельную структуру и не записывать непосредственно в основные файлы данных? Ответ заключается в разнице в скорости последовательной записи по сравнению с произвольной. Записи в основной каталог данных могут быть распределены по нескольким файлам и индексам, что приводит к частому перемещению диска. С другой стороны, запись в WAL осуществляется последовательно, что всегда быстрее (особенно на вращающихся дисках, но даже на SSD).
Затем транзакция может выбрать возврат фиксации после записи в WAL, , но перед записью в основные файлы данных. Теперь, если сервер выходит из строя, при перезапуске он может воспроизвести все изменения в WAL с момента последней контрольной точки.
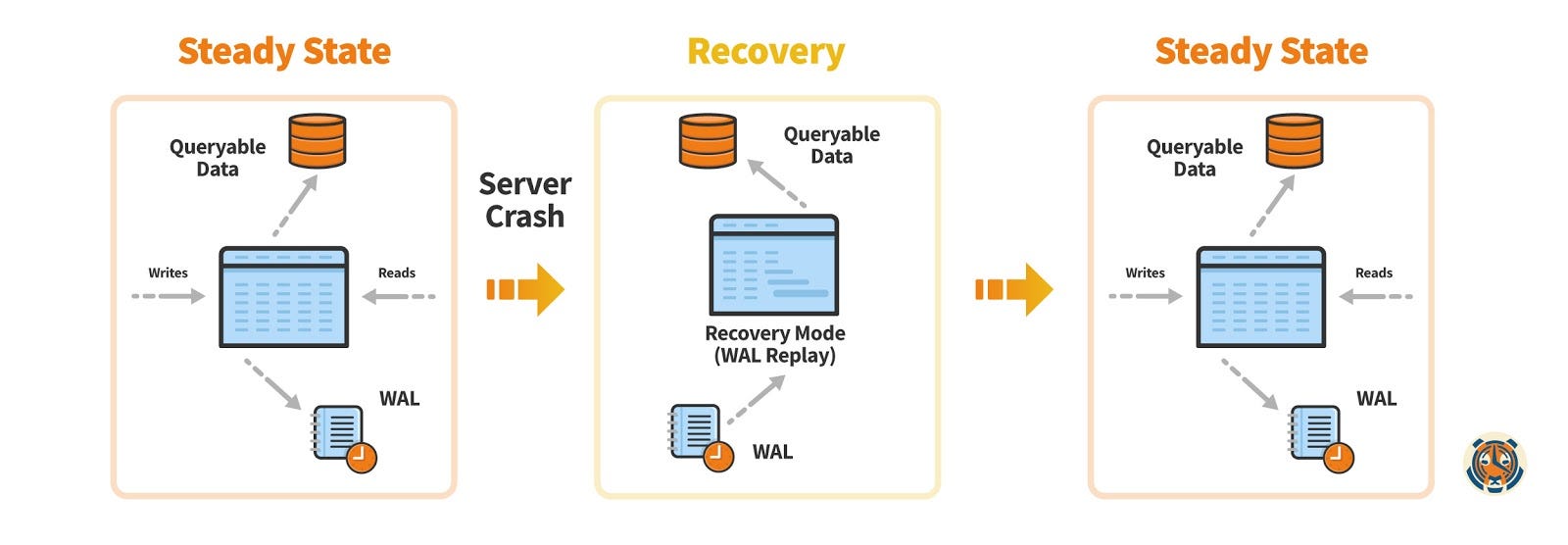
Другими словами, WAL - это каноническая запись всех изменений базы данных, так что мы можем воспроизвести изменения , которые были в памяти, но еще не были записаны в основной каталог данных в случае сервера. крушение.
WAL и репликация
WAL помогает, если сервер выходит из строя, а затем перезагружается (например, из-за ошибки нехватки памяти или отключения электроэнергии). Но у него есть одно вопиющее ограничение: он не может помочь, если диск поврежден, или страдает другая распространенная неисправимая проблема, или если его топают и бьют бейсбольной битой:

Все наши данные были на этом сервере и больше не вернутся. Так что нам также нужно что-то, чтобы быть устойчивыми к неисправимым сбоям. Вот тут и пригодится репликация.
Здесь PostgreSQL (на самом деле, обычно недооцененное сообщество разработчиков ядра PostgreSQL) использует умный подход. Вместо того, чтобы строить отдельную инфраструктуру для поддержки репликации, PostgreSQL просто использует тот же WAL. Он отправляет WAL на другие серверы; другие серверы воспроизводят WAL, как если бы они восстанавливались при перезапуске сервера; и вуаля!, теперь у нас есть полная копия базы данных на другом сервере.

На изображении выше основной сервер в режиме чтения / записи обрабатывает все изменения операций с данными (вставки, обновления, удаления), изменения определения данных (изменения схемы), а также любые операции чтения, на которые он указывает. Он планирует каждую транзакцию и определяет, где хранить, обновлять, удалять или находить данные. Все результирующие инструкции по изменению базы данных затем записываются в WAL, и клиенту возвращается сообщение о фиксации, чтобы он знал, что данные были сохранены. Реплики получают эти инструкции от отправителя WAL, сохраняя их в собственной копии WAL каждой реплики. Опять же, каждая реплика всегда существует в режиме горячего резервирования, когда процесс запуска (восстановления) читает из WAL и применяет свои изменения к базе данных, а запросы только для чтения разрешены. Что особенно важно, это означает, что реплики могут свободно вносить эффективные изменения в свой базовый диск на основе информации, уже определенной первичным.
Обычно в режиме восстановления чтение и запись в базу данных не разрешены, но для сервера-реплики его можно перевести в режим горячего резервирования. Режим горячего резервирования запрещает запись и воспроизведение WAL как режим восстановления, но разрешает запросы только для чтения. Затем можно использовать реплику для чтения, все время пока изменения данных передаются и применяются в фоновом режиме.
Различные режимы репликации для разных ситуаций
PostgreSQL поддерживает три основных режима репликации, каждый из которых определяет объем репликации данных, который произойдет до того, как запись будет считаться клиентом завершенной.

В каждом режиме репликации вы можете вносить дальнейшие корректировки в ожидания в отношении согласованности, устойчивости и времени фиксации транзакции. Такое поведение обрабатывается настройками synchronous_commit и synchronous_standby_names (более подробное описание этих настроек см. В нашем руководстве или документации PostgreSQL).

1. Асинхронная репликация
Асинхронная репликация не гарантирует, что данные были отправлены на какие-либо подключенные реплики. Данные считаются записанными после того, как они были записаны в WAL первичного сервера. Отправитель WAL будет передавать все данные WAL на любые подключенные реплики, но это будет происходить асинхронно после записи WAL.
Производительность записи. Асинхронная репликация - наиболее производительный режим репликации для вставок. Клиентам нужно только дождаться, пока основной запишет WAL. Любая задержка между основным и репликами отделена от времени записи, которое видит клиент. Однако любая задержка между записью на первичном сервере и записью на реплике (обычно называемая задержкой репликации) приведет к временной несогласованности данных до тех пор, пока реплики не наверстают упущенное.
Согласованность чтения. Поскольку нет никаких гарантий, что данные были переданы в реплики после успешной записи, этот режим может привести к временной несогласованности данных между первичной и репликой. Пока соответствующий WAL не будет передан репликам и не применен к их базам данных, клиенты, читающие с реплик, не увидят новые данные в своих запросах.
Потеря данных: потеря данных возможна при асинхронной репликации, если основной сервер безвозвратно выходит из строя до того, как WAL был передан на реплики [1]. Однако, если основной сервер выйдет из строя и снова заработает, реплики возобновят потоковую передачу с того места, где они остановились, и в конечном итоге догонят основной сервер.
2. Синхронная репликация записи.
Репликация с синхронной записью гарантирует, что все указанные реплики [2] запишут свои данные в WAL до того, как первичная реплика вернет клиенту успех.
Производительность записи. Производительность записи при синхронной репликации записи намного ниже, чем у ее асинхронного аналога. Запись на основной сервер в этом режиме влечет за собой дополнительные накладные расходы, связанные с обменом данными с репликами по сети, а также с ожиданием записи репликами в WAL.
Согласованность чтения: синхронная запись гарантирует, что WAL был записан, а не то, что данные были применены к постоянному уровню базы данных. Хотя это более надежная гарантия, чем при асинхронной репликации, она все же не является полностью согласованной. Клиент может читать из реплики до того, как сегмент WAL был применен к базе данных реплики, но после того, как он был применен к первичной базе данных. В общем, задержка репликации, возникающая в этом режиме, намного меньше, поскольку запись гарантирует, что данные WAL были отправлены и записаны в реплику.
Потеря данных: потеря данных все еще возможна при синхронной фиксации записи, но она гораздо менее вероятна, чем при асинхронной фиксации. В большинстве случаев синхронной записи как основная, так и все указанные реплики должны были бы безвозвратно вылетать [3]. В любом другом случае данные можно восстановить. Либо первичный сервер вернется в оперативный режим, и реплики смогут возобновить потоковую передачу, либо реплика, у которой гарантированно будет последняя копия WAL, может быть повышена до первичной.
3. Синхронная репликация Apply
Синхронное применение гарантирует не только то, что WAL будет записан во все указанные реплики, но также и то, что сегменты WAL будут полностью применены к базе данных.
Производительность записи: поскольку клиент должен дождаться завершения всех операций записи на первичной и каждой указанной реплике, это самый медленный режим репликации.
Согласованность чтения: каждая указанная реплика гарантированно будет полностью согласована с первичной, поскольку запись не будет считаться успешной, пока она не будет применена к базе данных.
Потеря данных. Синхронное применение обеспечивает еще более надежные гарантии от потери данных, чем синхронная запись. Во всех возможных конфигурациях синхронного режима применения базы данных первичной и всех указанных реплик гарантированно будут полностью обновлены. Потеря данных произойдет только в том случае, если и основная, и все указанные реплики будут безвозвратно утеряны.
Интересный факт: выбирайте компромиссы во время транзакции, а не во время настройки сервера
Одна из самых важных составляющих потоковой репликации в PostgreSQL заключается в том, что можно установить режим репликации для каждой транзакции.
Например, предположим, что у вас есть база данных с рабочей нагрузкой с важными, но нечастыми изменениями реляционных данных. Но у вас также есть другая рабочая нагрузка с менее важными, но гораздо более частыми вставками временных рядов. Вы можете решить потребовать строго согласованный режим репликации для реляционных данных с низкой скоростью вставки, но в конечном итоге согласованный режим для данных временных рядов с высокой скоростью вставки.
Затем вы можете установить Синхронную репликацию в качестве режима по умолчанию, но при записи данных временного ряда измените настройку на Асинхронная репликация только для этой транзакции. Это позволит вам справляться с резкими скачками скорости записи для временных рядов, обеспечивая при этом полную согласованность реляционной транзакции на всех узлах, для каждой транзакции, и все в одной базе данных.
Измерение влияния на производительность каждого режима репликации
Мы обнаружили, что измерения производительности - лучший способ по-настоящему оценить параметры конфигурации базы данных (и базы данных в целом). Мы серьезно относимся к такого рода тестам и используем их для измерения прогресса нашей собственной работы.
(Например, недавно мы обнаружили ограничения PostgreSQL 10 при работе с большим количеством разделов и показали как добиться лучшей производительности при работе с данными временных рядов.)
Поскольку основное влияние потоковой репликации на производительность оказывается на записи, здесь мы сосредоточимся на относительных различиях в производительности записи между каждым из режимов потоковой репликации для базы данных без репликации. Мы также продублировали эксперимент с другой базой данных PostgreSQL с установленным TimescaleDB, чтобы убедиться, что он будет работать аналогичным образом.
Обратите внимание, что производительность записи для PostgreSQL (но не для TimescaleDB) значительно ухудшается, если общий размер таблицы превышает основную память. Таким образом, мы представляем производительность для набора данных из 100 миллионов строк, который умещается в памяти. См. Последний раздел, чтобы узнать, как работать с большими объемами данных.
Кроме того, мы измерили изменение пропускной способности чтения с репликацией и без нее, но только на одном экземпляре TimescaleDB. Хотя необработанные запросы выполняются в TimescaleDB быстрее, чем в обычном PostgreSQL, разница между репликацией с / без репликации сопоставима в обеих конфигурациях.
Настройка эксперимента
Вот наша установка и набор данных:
- 3 узла (1 первичный и 2 реплики), каждый на собственной виртуальной машине Azure.
- Виртуальная машина Azure: D8 Standard (8 ядер, 32 ГБ памяти) с подключенными к сети твердотельными накопителями
- Все базы данных использовали одновременно 8 клиентов
- Набор данных: 4000 смоделированных устройств генерировали 10 показателей ЦП каждые 10 секунд в течение 3 полных дней. Метрики были смоделированы как строка таблицы (или строка гипертаблицы для TimescaleDB) с 10 столбцами (по 1 для каждой метрики) и индексами по времени, имени хоста и одной из метрик (cpu_usage)
- Вставки привели к 1 таблице / гипертаблице со 100 млн строк данных
- Для TimescaleDB мы установили размер блока на 12 часов, в результате получилось 6 блоков (подробнее о настройке TimescaleDB)
Цифры производительности
Производительность записи
В таблице ниже сравнивается количество вставок строк в секунду для PostgreSQL и TimescaleDB в четырех сценариях: без репликации и в каждом из трех режимов репликации.
Каждый режим репликации упорядочен слева направо по уровню гарантии согласованности, от самого низкого (асинхронный) до самого высокого (синхронное применение).

Здесь мы видим, что и PostgreSQL, и TimescaleDB испытывают незначительное снижение производительности записи при асинхронной репликации; это связано с тем, что в этом случае первичный сервер не ждет, пока журналы будут сохранены на диске, а реплики не ждут, пока данные будут применены к первичному серверу. Конечно, этот вариант включает самую низкую гарантию консистенции.
С другой стороны, мы видим, что у обоих наблюдается падение производительности записи на ~ 50% при использовании синхронного применения; это связано с тем, что теперь первичному серверу приходится ждать, пока транзакция будет применена дважды (один раз на первичном сервере и еще раз параллельно на всех репликах). Однако этот вариант обеспечивает самую надежную гарантию согласованности.
Синхронная запись, как и следовало ожидать, находится прямо посередине как с точки зрения производительности вставки, так и с точки зрения гарантии согласованности.
Производительность чтения
Наш эксперимент с производительностью чтения был намного проще, потому что независимо от того, какой режим репликации выбран, запросы выполняются одинаково. Мы использовали тот же набор данных и настройку виртуальной машины, что и для тестов вставки. Мы включили показатели производительности чтения только для TimescaleDB, чтобы упростить задачу, но в обычном PostgreSQL аналогичный прирост производительности достигается за счет распределения операций чтения по репликам.
Здесь мы сравниваем количество запросов в секунду для различных запросов к одному узлу и 3 узлам (1 первичный и 2 реплики):

При потоковой репликации с 2 репликами мы видим в среднем в 2,5 раза более быстрые запросы и большие улучшения по всем направлениям.
Тот же эксперимент с кластером из 5 узлов (1 первичный, 4 реплики) демонстрирует, что мы можем линейно масштабировать операции чтения по мере добавления узлов чтения в кластер, в результате чего запросы выполняются в 4,8 раза быстрее:

Сводка эксперимента
Как мы видим выше, компромисс между производительностью вставки и согласованностью для каждого из режимов репликации нетривиален и требует размышлений о типах рабочих нагрузок, которые вы планируете поддерживать.
Например, для рабочих нагрузок с большим объемом временных рядов, где некоторая потеря данных будет допустима в случае безвозвратной потери основного, вы можете выбрать прирост производительности из Асинхронной репликации [4].
С другой стороны, для пользователей, имеющих дело с транзакционными данными, которые нельзя потерять ни при каких обстоятельствах, гарантии абсолютного постоянства, предоставляемые Synchronous Apply, могут стоить дополнительных накладных расходов.
Или, возможно, лучший вариант для вас - это посередине (но ближе к синхронному применению) синхронная запись. Выбор остается за вами.
При любом из этих вариантов дополнительные узлы приводят к гораздо более высокой пропускной способности чтения (в среднем в 2,9 раза выше в нашем эксперименте с 3-узловым кластером, в 4,8 раза выше с 5 узлами), которая должна масштабироваться довольно линейно с количеством узлов-реплик. .
Решая, какой вариант использовать, не забудьте тщательно взвесить ваши требования и затраты. Для получения дополнительных сведений о том, как настроить желаемую конфигурацию, обратитесь к нашему Руководству по репликации (которое также включает инструкции для TimescaleDB).
Рекомендации для больших наборов данных
Хотя более высокая пропускная способность чтения и высокая доступность важны, некоторые рабочие нагрузки также требуют более высокой производительности вставки, чем та, которая обычно достигается с PostgreSQL, особенно если учесть, что производительность вставки в PostgreSQL резко падает по мере роста вашего набора данных:

Есть несколько неродных вариантов масштабирования производительности вставки в зависимости от типа вашей рабочей нагрузки; их обсуждение, возможно, потребует еще одного сообщения в блоге.
Но если у вас есть данные временных рядов, то мы предлагаем рассмотреть TimescaleDB. Мы видим не только 20-кратное увеличение масштабирования вставок, но также более быстрое удаление в 2000 раз, более быстрые запросы в 1,2–14 000 раз и различные улучшения удобства использования (полные тесты). И все параметры репликации, описанные выше, работают с TimescaleDB "из коробки".
Для получения дополнительной информации о TimescaleDB обратитесь к нашим Github и документации для разработчиков.
Понравился этот пост? Пожалуйста, порекомендуйте и / или поделитесь.
А если вы хотите узнать больше о TimescaleDB, посетите наш GitHub (звезды всегда приветствуются) и дайте нам знать, как мы можем помочь.
👣🎵
[1] Асинхронная репликация может быть достигнута, если для параметра synchronous_commit установлено значение off или local - в каждом случае основной сервер не будет подождите, пока реплики вернут успех писателю. Однако synchronous_commit несет более высокую вероятность потери данных, поскольку он гарантирует только то, что данные WAL были отправлены в ОС для записи на диск. Если ОС выйдет из строя до того, как данные WAL будут записаны, буферизованные данные будут безвозвратно потеряны. См. Https://www.postgresql.org/docs/current/static/wal-async-commit.html для получения дополнительной информации. ^
[2] Вы можете указать, какие реплики обслуживаются в первую очередь, с помощью параметра synchronous_standby_names. Вы также можете использовать этот параметр, чтобы настроить, сколько реплик будет ждать первичный перед возвращением успеха клиенту записи. Пустая настройка synchronous_standby_names приведет к тому, что основной сервер будет ждать только записи на свой собственный узел, что эквивалентно настройке synchronous_commit = local. Для получения дополнительной информации см. Наш учебник. ^
[3] Единственный случай, когда это не полностью верно, - это если для параметра synchronous_commit установлено значение remote_write. В этом случае данные WAL на репликах гарантированно будут сброшены в ОС для записи на диск, но могут быть потеряны, если ОС выйдет из строя до того, как она фактически закончит запись буферизованных данных. ^
[4] Следует отметить, что это будет наиболее выгодно в том случае, если высокая скорость записи не поддерживается постоянно. Если они всегда будут выше, чем могут поспевать реплики, реплики будут все больше и больше отставать, в конечном итоге становясь бесполезными. Однако для периодических рабочих нагрузок, когда важно быстро и последовательно возвращаться к клиенту, но реплики, вероятно, будут иметь относительно небольшой период записи в какой-то момент в будущем, асинхронная репликация может быть очень полезной. ^