Человеческое лицо - важный символ для распознавания людей с древних времен до наших дней. Человеческие лица используются для идентификации личности людей. Люди в социальных сетях делятся своими фотографиями, на которых обычно изображены человеческие лица. Распознавание лиц пользуется спросом, и в этой области было проведено большое количество исследований, например, распознавание лиц, манипуляции с лицами и т. Д. Замена лица - одна из техник, которые находят множество применений. такие как фотомонтаж, виртуальная подгонка прически, защита конфиденциальности и увеличение объема данных для машинного обучения. До того, как нейронные сети стали центром внимания, люди использовали ручные методы для обнаружения лиц или обмена лицами на изображениях.
Одна из широко известных методик смены лица - 3DMM (3D-морфируемая модель). При замене лица геометрическая форма лица получается с соответствующими текстурными картами путем подбора 3D Morphable Model (3DMM). Текстурные карты исходного и целевого изображений меняются местами с расчетными координатами UV. После этого замененная карта текстуры повторно визуализируется с использованием предполагаемых условий освещения. Этот метод позволяет поменять местами лицо с другой ориентацией или в разных условиях освещения. Проблема с этим методом заключается в том, что он не работает, когда условия освещения нереалистичны, а текстура с коррекцией освещения затруднена.
Исследователи используют глубокое обучение для обмена лицами с крупномасштабным набором данных изображений для обучения. FakeApp, настольное приложение, использующее глубокое обучение для обмена лицами, использует сотни изображений для обучения каждого человека. Собирать фотографии знаменитостей довольно легко, но человеку очень сложно исправить сотню изображений собственным лицом. Поэтому непрактично собирать много фотографий и настраивать сеть для создания одного изображения с замененным лицом.
Как это работает
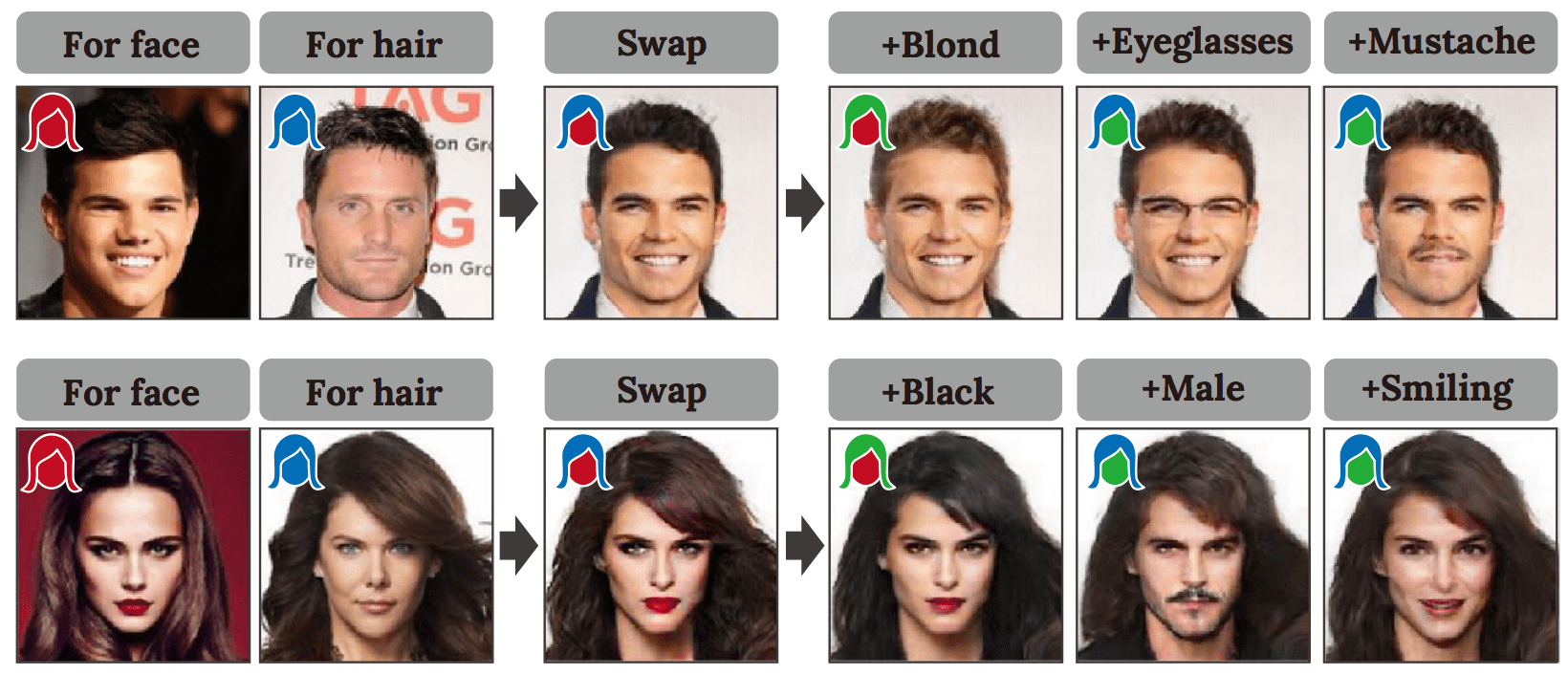
Эта проблема решена с помощью General Adversarial Network и двух вариационных автокодировщиков. Сеть предназначена для обучения из различных скрытых пространств (вы наблюдаете некоторые данные в пространстве и сопоставили эти данные со скрытым пространством, где точки данных расположены ближе) для каждой области лица и волос. Области лица и волос обрабатываются отдельно в пространстве изображения. Эта сеть называется GAN с разделением по регионам (RSGAN). Два автокодировщика, которые были названы разделительной сетью, и один GAN, который в документе упоминается как композиторская сеть. Архитектура представлена на рис.1.

Области лица и волос сначала кодируются в различные представления скрытого пространства с помощью разделительной сети. Затем сеть композиторов генерирует изображение лица с полученными представлениями скрытого пространства, так что первоначальные образы во входном изображении восстанавливаются. Однако обучение с использованием только представлений в латентном пространстве из реальных образцов изображений влечет за собой чрезмерную подгонку.
Пусть x будет обучающим изображением, а c - соответствующим ему вектором визуальных атрибутов. Представления в скрытом пространстве zxf и zxh внешнего вида лица и волос x получены с помощью кодировщика лиц FE-xf и кодировщик волос FE-xh. Точно так же визуальный атрибут c внедряется в скрытые пространства атрибутов. Представления в скрытом пространстве zcf и zch векторов атрибутов лица и волос получаются кодировщиками FE-cf и FE-ch . Сеть композитора G генерирует реконструированный внешний вид x ’ с представлениями скрытого пространства от кодировщиков.
Эти процессы реконструкции сформулированы как

Три функции потерь необходимы для лица (x’f), волос (x’h) и x ’ для входного изображения. Ниже приведены функции потерь для автокодировщиков:

где MBG - это маска фона, которая принимает 0 для пикселей переднего плана и 1 для пикселей фона, а оператор ⨀ обозначает умножение на пиксель. Фоновая маска MBG используется для обучения сети синтезу более подробных представлений в областях переднего плана.
Набор сетей разделителя и составителя, а также две сети дискриминатора обучаются состязательным образом как стандартные сети GAN. Состязательные потери определяются как:

Результат
Предлагаемая система обеспечивает качественную замену лиц, которая является основной целью данного исследования, даже для лиц с разной ориентацией и в разных условиях освещения.



RSGAN обеспечивает качественную замену лиц, которая является основной целью этого исследования, даже для лиц с разной ориентацией и в разных условиях освещения. Поскольку RSGAN может кодировать внешний вид лиц и волос в нижележащие представления скрытого пространства, внешний вид изображений можно изменять, манипулируя представлениями в скрытых пространствах. Успех архитектуры и метода обучения RSGAN в качестве метода глубокого обучения подразумевает, что глубокие генеративные модели могут получать даже класс изображений, которые не подготовлены в наборе обучающих данных.