
Создание развертываемого классификатора машинного обучения на Python
В наши дни машинное обучение стало совершенно необходимым, эффективным и действенным способом поиска решений проблем благодаря сложности проблем и огромному объему связанных с ними данных. В большинстве ресурсов модель машинного обучения разрабатывается на основе структурированных данных только для проверки точности модели. Но в реальном времени одними из основных требований при разработке модели машинного обучения является обработка несбалансированных данных при построении модели, настройке параметров в модели и сохранении модели в файловой системе для последующего использования или развертывания. Здесь мы увидим, как разработать двоичный классификатор на Python, соблюдая все три требования, указанные выше.
При разработке модели машинного обучения мы обычно вкладываем все наши инновации в стандартный рабочий процесс. Некоторые из задействованных шагов - это получение данных, разработка функций на них, построение модели с правильными параметрами посредством итеративного обучения и тестирования и развертывание построенной модели в производственной среде.
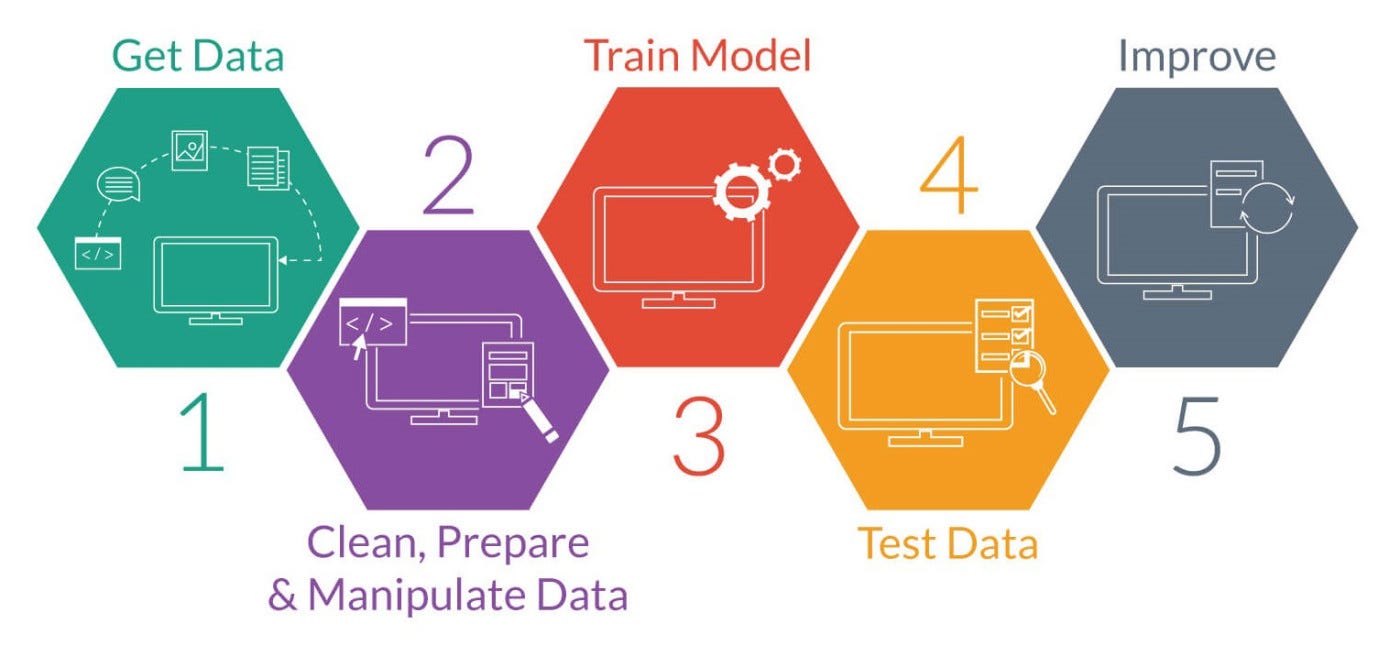
Мы рассмотрим этот рабочий процесс, построив двоичный классификатор для прогнозирования качества красного вина по доступным характеристикам. Набор данных общедоступен в репозитории машинного обучения UCI. Библиотека Scikit Learn используется здесь для проектирования классификатора. Для исходного кода ссылка github -
Сначала нам нужно импортировать все необходимые зависимости и загрузить набор данных. Нам всегда нужны numpy и pandas в любом дизайне модели ml, поскольку во всех задействованы операции с фреймами данных, матрицами и массивами.
import numpy as np
import pandas as pd
df = pd.read_csv("winequality-red.csv")
df.head()
Набор данных выглядит так:

Как видно здесь, качество было представлено числами от 3 до 8. Чтобы сделать это проблемой двоичной классификации, возьмем качество ›5 - хорошо, иначе - плохо.
df["quality_bin"] = np.zeros(df.shape[0]) df["quality_bin"] = df["quality_bin"].where(df["quality"]>=6, 1) #1 means good quality and 0 means bad quality
Чтобы получить сводку описания данных -
df.describe()

Как видно из снимка, значения данных по некоторым атрибутам сильно отклоняются. Рекомендуется стандартизировать значения, так как это приведет к разумному уровню дисперсии. Кроме того, поскольку большинство алгоритмов используют евклидово расстояние в фоновом режиме, масштабирование функций лучше при построении моделей.
from sklearn.preprocessing import StandardScaler X_data = df.iloc[:,:11].values y_data = df.iloc[:,12].values scaler = StandardScaler() X_data = scaler.fit_transform(X_data)
Здесь используется fit_transform, так что StandardScaler подходит для X_data и также преобразует X_data. Если вам нужно подогнать и преобразовать его в двух разных наборах данных, вы также можете вызвать функции fit и transform отдельно. Теперь у нас есть всего 1599 экземпляров данных, из которых 855 - плохого качества, а 744 - хорошего качества. Данные здесь явно несбалансированы. Поскольку существует меньшее количество экземпляров данных, мы будем использовать передискретизацию. Но важно отметить, что повторная выборка всегда должна выполняться только для данных обучения, а не для данных тестирования / проверки. Теперь давайте разделим набор данных на набор данных для обучения и тестирования для модели. строительство.
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.3, random_state=42) #so that 30% will be selected for testing data randomly
Вместо разделения обучения и тестирования вы также можете использовать более эффективный метод перекрестной проверки. Сейчас у нас для обучения 588 экземпляров плохого качества и 531 экземпляров хорошего качества. Для тестирования осталось 267 экземпляров плохого качества и 213 экземпляров хорошего качества. Пришло время выполнить повторную выборку обучающих данных, чтобы сбалансировать их, чтобы модель не была предвзятой. Здесь мы будем использовать алгоритм SMOTE для передискретизации.
from imblearn.over_sampling import SMOTE #resampling need to be done on training dataset only X_train_res, y_train_res = SMOTE().fit_sample(X_train, y_train)
После передискретизации в обучающей выборке оказалось 588 экземпляров вина как хорошего, так и плохого качества. Пришло время выбора модели. Я взял сюда стохастический градиентный классификатор. Но вы можете проверить несколько моделей и сравнить их точность, чтобы выбрать подходящую.
from sklearn.linear_model import SGDClassifier sg = SGDClassifier(random_state=42) sg.fit(X_train_res,y_train_res) pred = sg.predict(X_test) from sklearn.metrics import classification_report,accuracy_score print(classification_report(y_test, pred)) print(accuracy_score(y_test, pred))
Результат выглядит так:

Полученная точность составила 65,625%. Такие параметры, как скорость обучения, функция потерь и т. Д., Играют важную роль в работе модели. Мы можем эффективно выбрать лучшие параметры для модели с помощью GridSearchCV.
#parameter tuning
from sklearn.model_selection import GridSearchCV
#model
model = SGDClassifier(random_state=42)
#parameters
params = {'loss': ["hinge", "log", "perceptron"],
'alpha':[0.001, 0.0001, 0.00001]}
#carrying out grid search
clf = GridSearchCV(model, params)
clf.fit(X_train_res, y_train_res)
#the selected parameters by grid search
print(clf.best_estimator_)

Как видно здесь, здесь указаны только функция потерь и альфа, чтобы найти для них лучший вариант. То же самое можно сделать и с другими параметрами. Лучшим вариантом для функции потерь, по-видимому, является «шарнир», т.е. линейный SVM, а для альфа-значения он кажется равным 0,001. Теперь мы построим модель, используя лучшие параметры, выбранные при поиске по сетке.
#final model by taking suitable parameters clf = SGDClassifier(random_state=42, loss="hinge", alpha=0.001) clf.fit(X_train_res, y_train_res) pred = clf.predict(X_test)
Теперь мы выбрали модель, настроили параметры, так что пришло время проверить модель перед развертыванием.
print(classification_report(y_test, pred)) print(accuracy_score(y_test, pred))

Как видно здесь, после настройки параметров значения метрик улучшились на 2–3%. Точность также улучшилась с 65,625% до 70,625%. Если вас все еще не устраивает модель, вы можете попробовать и другие алгоритмы, выполнив несколько итераций обучения и тестирования. Теперь, когда модель построена, ее необходимо сохранить в файловой системе для дальнейшего использования или развертывания в другом месте.
from sklearn.externals import joblib joblib.dump(clf, "wine_quality_clf.pkl")
Когда вам понадобится классификатор, его можно просто загрузить с помощью joblib, и массив функций будет передан для получения результата.
clf1 = joblib.load("wine_quality_clf.pkl")
clf1.predict([X_test[0]])
Поздравляю! Теперь вы готовы разработать развертываемую модель машинного обучения. :-D
Использованная литература:-