Введение, обзор
Этот документ состоит из трех частей:
- введение в основные компромиссы в дизайне GC (скорость в разных местах, использование RAM, безопасность и т. д.)
- описание того, что SBCL на amd64 делает прямо сейчас, что предлагает (или хочет предложить) LLVM и как они соотносятся друг с другом
- я бормочу, что текущие ограничения LLVM позволяют мне реализовать хорошую сборку мусора, это также мешает мне подбирать многие конструкции, которые я использовал для обеспечения лучшего GC в определенных ситуациях (а именно в поисковой системе QPX ITA / Google в SBCL)
Компромиссы, о которых стоит подумать
Вкратце:
- скорость против космоса, как всегда
- «Скорость» сборщика мусора как компромисс со скоростью во время выполнения основного кода (код, отличный от GC). Почти все схемы сборки мусора требуют, чтобы основной код выполнял действия в интересах сборщика мусора.
- для самого GC общее время ЦП (по всем ЦП) во время GC, GC реального времени и пауз основного кода («GC pauses»)
- для основного кода это в основном: накладные расходы на обслуживание GC - время процессора или системное время; если это системное время, это дешевые или дорогие системные вызовы (изменения карты виртуальных машин и т. д.); становится ли код больше (угрожает захватить больше строк кэша кода L1); имеют ли дополнительные данные для использования GC значительный размер?
Скорость магистрали в сравнении со скоростью сборки мусора - это очень сложный вопрос. Есть много приложений, в которых вы можете принять длительное время сборки мусора, если это ускоряет основной код.
Основным примером являются сервисы, ориентированные на запросы. Просто обслуживайте запрос без сборки мусора (если это не необычный запрос), а затем сборку мусора между запросами, пока никто не ждет результата. Очевидно, вы хотите уменьшить видимую для пользователя задержку, сделав основной код как можно более быстрым, с наименьшими накладными расходами для помощи в ведении бухгалтерского учета GC. Также очевидно, что общее время процессора, используемое сервером в течение дня, может резко возрасти (что также означает счет за электроэнергию). Поисковая система QPX от ITA / Google является классическим примером, она (в основном) ориентирована на запросы, а в некоторых случаях пользователи ждут.
Другой пример, когда вы хотите снизить накладные расходы на ведение бухгалтерского учета for-GC в основном коде, - это возможность «GC-by-fork», которая в основном отбрасывает процессы, как они потребуются для GC, возобновляя операции с уже размещенного сервера (через Unix fork (2). Здесь вы будете запускать медленный код GC только для необычных запросов, и вы хотите уменьшить задержку большинства запросов, сделав основной код быстрым.
GC-by-fork хорошо работал у меня в QPX, однако вы больше не можете его использовать, когда вам нужно использовать библиотеки, которые запускают потоки, но не предлагают API, чтобы сообщить этой библиотеке, чтобы она парковала свои потоки в безопасном для вилки положении. Также существуют сложные взаимодействия между отображениями виртуальной памяти, физическими страницами и тем, как они влияют на скорость fork (2) в разных операционных системах. SBCL использует защиту страницы виртуальных машин для справки по сборщику мусора и, следовательно, создает большое количество отдельных сопоставлений виртуальных машин, что может замедлить разветвление во многих версиях Linux.
Или представьте себе интерактивное приложение, которое ждет ввода данных пользователем. Почему бы не использовать это время для сборки мусора, и если пользователь мешает во время сборки мусора, отказаться от этого запуска сборщика мусора? Или fork, GC в разветвленном процессе, а затем в зависимости от времени пользователя и GC продолжить ваше приложение либо в родительском, либо в дочернем. Во всех этих случаях вы бы предпочли скорость основной линии, а не скорость сборки мусора.
Я не хочу заходить слишком глубоко. Надеюсь, я объяснил, почему один размер подходит всем на самом деле не подходит для сборки мусора. Подробнее на эту тему я написал здесь: https://medium.com/@MartinCracauer/generational-garbage-collection-write-barriers-write-protection-and-userfaultfd-2-8b0e796b8f7f
LLVM и SBCL
Речь идет о немного консервативном GC поколений, который SBCL использует на i386 и amd64. У SBCL есть и другие сборщики мусора, но gencgc является наиболее оптимизированным, поскольку он используется практически во всех производственных целях SBCL.
LLVM имеет несколько различных механизмов для поддержки GC, загрузчик плагинов и множество других вариантов, и все меняется довольно быстро. Также оказывается, что просто базовое распределение памяти в SBCL - это не то, что LLVM ожидает прямо сейчас (LLVM хочет выполнить функцию, но SBCL выделяет, увеличивая указатели, см. Https://github.com/sbcl/sbcl/blob /master/src/compiler/x86-64/alloc.lisp#L89 ).
В настоящее время на LLVM очень мало языков сбора мусора, и до сих пор они определяли большую часть дизайна интерфейса.
Во-первых, описание того, как работает сборщик мусора SBCL:
- написан для CMUCL Питером Ван Эйнде @pvaneynd (ETA: Питер говорит, что это был не он, может быть, Дуглас Крошер?), когда CMUCL был портирован на x86, позже использовался, когда SBCL отделился от CMUCL и был реализован amd64
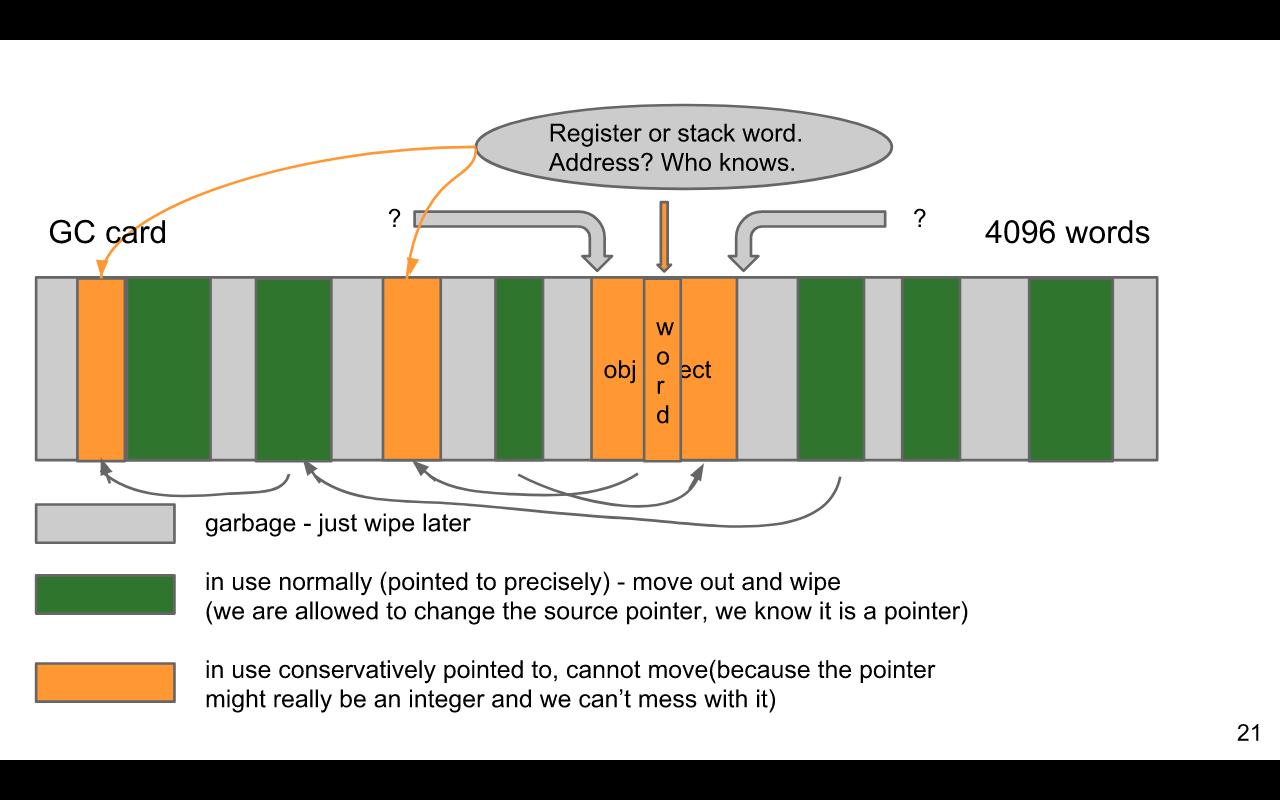
- поколенческий, со страницами / сегментами внутри поколений (я называю их «картами GC», чтобы не путать со страницами ВМ)
- немного консервативен. Из-за нехватки регистров на x86 генератор кода для x86 решил не разделять набор регистров на помеченные и немаркированные (на RISC одна половина регистров может содержать только указатели, а другая половина - только указатели. Таким образом, GC будет специально знать, что такое указатель, а что нет). GenCGC SBCL не консервативен, когда дело доходит до heap-to-heap, только для потенциальных источников указателей, таких как регистры, стек (можно избежать, но пока сделано), контексты сигналов и пара других мест.
- Консервативен в отношении стека. Это создает серьезное противоречие с LLVM, который ожидает карту стека. Карта стека объявляет, какой тип данных может быть найден в стеке для функции (поскольку при каждом вызове этой функции она должна соответствовать), тогда как компилятор SBCL может генерировать и создает код, который просто размещает что-либо в любом месте. Это делает стек намного более компактным в некоторых шаблонах вызовов.
- поддерживает барьер записи, но не барьер чтения. Это означает, что части кучи могут быть исключены из очистки (сканирования), когда можно доказать, что они когда-то не указывали на нашу предполагаемую область и с тех пор не были изменены.
- барьер записи реализуется защитой страницы виртуальной машины и использованием SIGSEGV. Когда я займусь написанием кода, следует использовать более быстрый userfaultfd (2) в Linux. Также может подойти механизм мягкое-грязное долото. Я подробно писал об этом здесь: https://medium.com/@MartinCracauer/generational-garbage-collection-write-barriers-write-protection-and-userfaultfd-2-8b0e796b8f7f https: //www.cons. org / cracauer / cracauer-userfaultfd.html
- это копирование, однако другие проходы, которые просто пробивают дыры в существующих картах (чтобы стереть указатели, на которые больше не указывают, без перемещения большого количества памяти), есть и будут добавлены. Консервативный сборщик мусора и использование из сборщика мусора реализуются путем защиты всей карты сборщика мусора от перемещения с последующим сбором мусора внутри нее, пробивая дыры (что оставляет закрепленные объекты на месте).
Эта схема сборки мусора имеет следующие свойства:
- быстрая память пишет. Нет накладных расходов на инструкции, которые пишут в память. Поскольку мы используем средства ОС для барьера записи, нет необходимости аннотировать каждую запись в память второй записью, выполняющей бухгалтерский учет для барьера записи.
- Можно было бы добиться отличной производительности, если бы ваша система в целом создавала временный мусор во время запросов, сбрасывала весь этот мусор перед следующим запросом, если у вас нет старых вещей, указывающих на него (что, к сожалению, не то, что QPX).
- Глядя на накладные расходы на управление памятью во время GC и времени, отличного от GC, вы увидите, что код, не связанный с GC, страдает очень мало (только некоторые обновления защиты виртуальной машины для карт GC, которые можно настроить с помощью детализации). Быстрое время, отличное от GC, может быть огромным преимуществом для систем, ориентированных на запросы, потому что вы можете выполнять GC между запросами, чтобы видимые клиентом запросы не увеличивали задержку от GC. Вы также можете выполнять более полные сборщики мусора между запросами и быстрые сборщики мусора во время и по-прежнему выигрывать. Конечно, когда вы играете в эти игры, общее потребление ЦП для рабочей нагрузки, связанной с запросами и без запросов, возрастает.
- Барьерные сборщики мусора, которые поддерживают свои собственные растровые изображения с помощью записи с аннотациями, обладают гибкостью, чтобы научить систему большему количеству трюков и выполнять больше учета во время кода без сборщика мусора, немного замедляя запросы, но экономя общее реальное время или время ЦП. Пользователям системы защиты страниц виртуальных машин не с чем поиграть, но userfaultfd (2) даст SBCL кое-что, с чем можно поиграть.
- Сборщик мусора SBCL потенциально может работать в многопоточном режиме, но не одновременно. Это означает, что ему нужно остановить мир, а затем можно использовать несколько потоков и процессоров для выполнения GC (нереализованного), но он не может выполнять сборку мусора в фоновом режиме, пока остальной мир работает. Обычно для этого нужны барьеры для чтения. В настоящее время мне неизвестно, могут ли схемы защиты страниц виртуальных машин реализовать барьеры чтения, достаточные для одновременного GC, и если да, то позволяет ли неизбежная детализация обеспечить достаточную производительность. Это эквивалентно трем режимам сборки мусора в Java. JVM использует аннотированные записи с множеством настроек барьера записи.
Другое управление памятью в SBCL:
- Скомпилированный код SBCL не использует функцию распределения для большинства аллоков. Только большие выделения или выделения, попадающие в конец выделенной области, вызывают функцию. Все промежуточное выделение памяти осуществляется путем атомарного увеличения указателя свободного пространства, нескольких потоков, использующих одну и ту же область распределения и один и тот же указатель свободного пространства (это работает, потому что они используют сравнение и замену для получения выделенного места).
Это потенциально сложно сохранить, но я бы хотел сохранить это. Скорость, с которой может быть образован мусор, огромна, и все это складывается.
GC SBCL копирует (перемещает) по умолчанию, что позволяет использовать эту схему. Нет фрагментации. Просто вставляйте новые объекты на место простым способом один за другим.
Не существует функций типа malloc, которые должны отслеживать фрагменты, чтобы, возможно, их заполнить, поддерживать пулы кучи в списках или других классах коллекций. Функция malloc для всех практических целей должна либо использовать пулы кучи для конкретных потоков, либо использовать блокировку потоков. Выполнение malloc в C на несколько порядков дороже, чем в коде SBCL. Тем более в многопоточном коде. В коде SBCL есть способ без блокировки для создания кучи данных в куче без вызовов функций.
Также нет нулевой инициализации выделенного пространства. Common Lisp не допускает неинициализированных переменных, поэтому выделенное пространство перезаписывается перед использованием с использованием значения инициализации (в отличие от его сначала обнуления, а затем повторной записи со значением инициализации).
Все это делает различные механизмы LLVM медленными, а именно LLVM обычно ожидает, что вы выполняете функции для распределения, и обнуляет память.
Свойства компилятора SBCL:
- отсутствие псевдонимов указателей в сгенерированном коде (мы вернемся к этому позже)
- реализация барьера записи с использованием растрового изображения была доступна как патч для SBCL Полом Кхуонгом @ pkhuon g. Я сравнил его с реализацией страницы виртуальной машины. Непроверенное реальное приложение не показало общей разницы в производительности. Очевидно, что в нем преобладала фактическая работа GC (особенно сканирование памяти), и на самом деле не имело значения, как вы делаете барьер записи, и оба механизма, по-видимому, выполняли одинаковую работу по исключению карт GC из очистки. Я мог бы выкопать некоторые цифры о размере результирующего скомпилированного кода. У меня есть версии SBCL того времени, если вы хотите поиграть с этими двумя.
- очень приличные возможности распределения стека. Это значительно сократило общее время управления кучей моей игрушки на работе. В отличие от Golang, в Лиспе невозможно автоматически определять размер стека для нетривиального кода, вы должны сообщить компилятору (как в C) и надеяться, что вы не ошибаетесь (язык Лисп позволит нам использовать компиляцию в безопасном режиме, чтобы на самом деле сделать это обнаруживаемым во время регрессионных тестов, но этого не было сделано).
Чтобы немного повторить основы: CMUCL и SBCL - это собственные компиляторы. Они компилируются в машинный код, загружают и запускают собственный код. Они не используют компилятор ОС, ассемблер или компоновщик (за исключением исполняемого образа). CMUCL / SBCL имеют различные фазы преобразования в Lisp-подобные абстракции, затем в абстрактный машинный язык, затем очень простой и линейный шаг от абстрактного машинного языка к двоичному коду запрашиваемой архитектуры.
Мой интерес к LLVM проистекает из этого последнего шага. На этом последнем этапе (от абстрактного ассемблера к машинной сборке) оптимизация не производится, и машинный код не оптимизируется. Получающийся в результате код может выглядеть повторяющимся и расточительным, когда его читает человек. LLVM - это именно то, что мне нужно: машина для оптимизации сборки. Если бы я мог просто заменить последние 1 или 2 шага в SBCL на LLVM, я бы получил гораздо более красивый машинный код.
Теперь это спорно и обсуждалось внутри Google, действительно ли текущее положение дел наносит большой вред. Код просто немного больше, меня больше беспокоили ненужные инструкции. Чтобы проверить это, я сделал функции C, которые выполняли примерно то же самое, что и мои функции Lisp, затем скомпилировал C в ассемблер, отредактировал файл ассемблера, чтобы он был расточительным, так же, как последний этап SBCL является расточительным, и протестировал его. Современные процессоры x86 с поразительной скоростью справляются с парой ненужных или неэффективных инструкций. Поскольку зависимости хранилища в потоке инструкций, очевидно, весьма благоприятны (мы говорим о повторяющихся манипуляциях с одними и теми же местоположениями с использованием одних и тех же данных чтения), разница была едва заметна. Я решил не «продавать» этот огромный проект ради работы. Результат неясен. Теперь у меня свободное время, и я хочу узнать больше.
Требования к LLVM GC:
- LLVM может использовать псевдонимы указателей, называя их «производными указателями» в рамках оптимизации. Движущийся сборщик мусора, которому необходимо найти все указатели на перемещаемый объект, должен быть проинформирован о таких копиях и о том, где они находятся, чтобы копию можно было также откорректировать. Обычно это не сложно, если вы просто помещаете копии в кучу (где их найдет очистка), но это не обязательно так (потребует их упаковки). Над этим нужно подумать.
- Что еще хуже, такие производные указатели могут на самом деле не быть копиями указателей на (начало) объекта, они могут указывать на середину. У существующего SBCL GC есть некоторые возможности для решения этой проблемы, но это проблема и замедление. Вам нужно определить окружающий объект при уборке мусора.
- LLVM не зависит от языка и, естественно, предполагает, что в смешанной языковой системе (например, Lisp и C) оба языка могут свободно обращаться друг к другу. Это отличие от SBCL, где вызов Lisp из C поддерживается только в том случае, если вы заключите его в подпрограммы, которые сообщают об этом системе (например, чтобы объекты Lisp, на которые указывает C, не перемещались, это просто складывается в « слегка консервативный »механизм).
За что я не плачу сейчас (в SBCL):
- В SBCL сейчас я не вынужден усложнять запись в память. Я хотел бы направить средства LLVM для псевдонима указателя, чтобы сохранить это. В зависимости от того, как работает userfaultfd (2), я мог бы переключиться на растровую схему для барьера записи, но прямо сейчас я ожидаю, что подход страницы виртуальной машины будет для меня лучше при надлежащей поддержке ОС. Я бы не хотел, чтобы память записывала медленнее.
- Мои системы основаны на Лиспе. C используется как вспомогательное средство. Я редко передаю указатели в кучу Лиспа на C. Когда я это делаю, доступен простой механизм защиты таких данных от перемещения. Безопасность этого механизма можно повысить с помощью SBCL, например, с помощью защиты виртуальных машин областей кучи Lisp от чтения, когда такая область освобождается сборщиком мусора. Я не хотел бы платить цену за скорость кода за автоматические механизмы, чтобы справиться с этим, особенно за скорость во время кода, отличного от GC.
- Даже если бы мне пришлось научиться больше любить барьеры записи растровых изображений, чем сейчас, игры для защиты виртуальных машин используются повсюду, например, для защитных страниц и других средств обеспечения безопасности. Вы легко можете оказаться в ситуации, когда некоторые накладные расходы на сборщик мусора и безопасность можно разделить, тем самым снизив затраты на оптимизацию сборщика мусора на основе виртуальной машины.
Заключительные слова
Текущие возможности LLVM позволяют написать хороший сборщик мусора. Однако ваш выбор для выбора конкретных компромиссов ограничен.
Очень сложно оценить, как это работает на практике, поскольку в LLVM прямо сейчас нет языка (насколько мне известно), который произвольно генерирует такой же компактный код, как C, и выполняет сборку мусора, как это делает SBCL. Сравнительный анализ схем GC для общего времени, а тем более для основных затрат времени по сравнению с GC не может быть выполнен на языках, которые используют кучную память в гораздо большем количестве мест, чем код, сгенерированный C или SBCL.
Очень редко можно увидеть два одинаково настроенных GC в одной и той же языковой реализации (нет, три сборщика мусора JVM - это всего лишь один, с парой вариантов его запуска). Требование, чтобы наиболее быстрые сборщики мусора нуждались в основном коде для ведения бухгалтерского учета, очень утомляет переключение между сборщиками мусора, не говоря уже о том, чтобы правильно реализовать их в первую очередь.
В случае с SBCL. Ну, как люди знают, мой любимый проект - использовать LLVM в качестве замены последней стадии SBCL, которая представляет собой абстрактную сборку для машинной сборки. На этом этапе оптимизация в SBCL не выполняется прямо сейчас, и LLVM полностью посвящен этим конкретным оптимизациям. Я разочаровался в возможном приросте скорости, когда тестировал рукописный ассемблерный код, чтобы делать глупые вещи, которые SBCL делает на своем последнем этапе, по сравнению с кодом, который этого не делает. Результатом этих тестов стало то, что современным процессорам все равно. Они пробуют немного неэффективный ассемблерный код почти так же, как и оптимизированный код. Очевидно, что оптимизации, которые я упустил на последнем этапе SBCL и которые есть в LLVM, в значительной степени реализованы и в процессорах.
(Мне нужно уточнить, что это работает только для оптимизаций после перестройки потока программы, например, когда у вас уже есть абстрактная сборка и сгенерирована машинная сборка. Все предыдущие этапы оптимизации имеют решающее значение для скорости, и игры с интеллектуальным графиком зависимостей ЦП не могут помочь, если вы просто запустите через гораздо больше кода в масштабе, который не покрывается прогнозом микроархитектуры. Например, ненужное использование большого объема кучи всегда убьет вас, независимо от того, как долго вы удерживаете эту память кучи)
В целом я оставил это со смешанными чувствами. Возможности GC в LLVM неплохие, и ограничения того, что вы можете делать в отношении проектирования GC, небезосновательны с точки зрения универсального специалиста.
В то же время я уверен, что если бы вы запускали движок QPX от ITA / Google с ограничениями, которые LLVM налагает в то время, когда я участвовал в предоставлении ему услуг (2001–2017 гг.), Вы бы увидели много горя. нездорово для стартапов. Управление памятью на всех уровнях (куча, стек, виртуальная машина, оперативная память) было ключевым фактором успеха ITA. Благодаря тому, что авиакомпании установили множество сумасшедших правил тарифов, нам понадобилась способность подчинять память своей воле.
Приложение 1 - негерметичный ГХ
Я просто заметил, что не говорил о точности и даже правильности.
Нежелательное сохранение. Очевидно, что сборщик мусора, который в любом случае является консервативным, имеет риск удерживать память, когда этого не следует делать. Целое число, плавающее в консервативно отсканированной области, которое может быть указателем, и вы там. Теоретически это могло удерживать очень большие объемы физической памяти. Представьте себе, что такое целое число с ложным псевдонимом указывает на связанный граф связного размера. Это само по себе не так уж и маловероятно, особенно в системе, ориентированной на запросы. Представьте, что вы строите большой граф для каждого запроса и хотите отбросить его в начале следующего запроса. Если у вас есть консервативный сборщик мусора, который регулярно строит такой график из предыдущего запроса, вы можете умножить использование памяти.
С другой стороны, в 64-битном адресном пространстве виртуальных машин вы можете переместить кучу Lisp достаточно высоко, чтобы ложные псевдонимы стали менее вероятными (целые числа в компьютерных системах статистически гораздо более вероятно будут маленькими). Имейте в виду, что SBCL не консервативен. Большие кучи не являются источниками возможных консервативных указателей (ни Лисп, ни куча C). Стеки - самый большой источник для SBCL. Это контрастирует, например, с сборщик Boehm для C, который всегда полностью консервативен, а также от куча к куче, стеки, регистры и т. д.
Как известно моим друзьям, у SBCL был недостаток, заключающийся в том, что закрепление памяти одним консервативным указателем могло распространиться на еще 4095 указателей (все на карте GC), что вызвало некоторые проблемы для моей игрушки на работе и привело к разговору о ELS 2015. Конференция по Лисп в Лондоне.
Потеря памяти: Не смейтесь, с моей точки зрения систем, ориентированных на запросы и привыкших к фактическому клонированию процессов (fork (2) или быстрый старт из образов mmap (2) и Lisp) I Можно представить себе использование GC, который иногда собирает слишком много. Это должно было подкупить меня некоторыми значительными преимуществами в скорости или, конечно, чем-то еще. То, как это будет работать, заключается в том, что освобожденная память заменяется областями памяти, которые не отображаются, что дает мне segfault, когда что-то пытается получить доступ к памяти, которая теперь некорректно исчезла. Этот segfault - это то же самое, что SBCL теперь использует для отслеживания поколений, которые не были изменены с момента последнего сканирования и помечены как только для чтения. Это не экзотическое понятие, виртуальные машины тоже его используют. Сейчас это очень дорого, здесь должен помочь userfaultfd (2). Https://www.cons.org/cracauer/cracauer-userfaultfd.html
В любом случае, я получаю уведомление о том, что у меня есть фрагмент кода, в котором был оставшийся указатель на фрагмент данных, который должен был быть сохранен, но не был. Я могу решить, как я хочу с этим справиться. Представьте еще раз, что у меня есть система, которая (а) ориентирована на запросы и (б) создает новые экземпляры с помощью вилки. Я могу просто удалить дочерний элемент и перезапустить запрос в родительском (или новом дочернем), на этот раз с указанием GC, чтобы быть точным. В зависимости от того, какое ускорение вы получите от сборщика мусора fast-n-loo, это может окупиться. Если у вас много ЦП, вы также можете запустить быструю и медленную версию одновременно, используя результат медленной версии, если у ребенка не получается, или отмените медленную версию, когда быстрая версия сделала это.
Думайте об этом как о общесистемном варианте использования слабых указателей, редко, когда они могут повысить скорость, а реакции на слабые указатели либо выполняются системой (в отличие от кода, непосредственно использующего указатели), либо кодом, который может справиться с ситуацией. может поступать так, как считает нужным. Вы могли бы немного настроить это, например вы, вероятно, не захотите выбрасывать код, который все еще используется.
Эталонное изображение карт SBCL GC: