
В этой статье я расскажу о представлении и обслуживании моделей глубокого обучения через Tensorflow, а также продемонстрирую свою настройку для гибкого и практичного решения для генерации текста.
С помощью генерации текста я предполагаю автоматическую задачу создания новых семантически действительных фрагментов текста переменной длины с учетом необязательной исходной строки. Идея состоит в том, чтобы иметь возможность использовать разные модели для разных вариантов использования (вопросы и ответы, утилиты чат-бота, упрощение, предложение следующего слова), также на основе различного типа контента (например, повествовательного, научного, кода), источников или авторы.
Вот первый предварительный просмотр настройки в действии для предложения предложения.

На этой записи показано создание текста по запросу с использованием трех разных моделей, каждая из которых обучена соответствующему источнику текста (например, тексты песен, Библии в версии короля Джеймса и книге Дарвина О происхождении видов), основанных на разных исходных строках. . Как и ожидалось, каждая модель отражает тон и содержание исходного источника - как и все другие потенциальные модели - и показывает его потенциал для конкретных применений и сценариев, все еще в основном в зависимости от потребностей и ожиданий автора. Предварительный просмотр также позволяет получить интуитивное представление о характеристиках моделей, намекая на то, какая модель потребует улучшений для соответствия определенным требованиям.
Следующие параграфы будут точно отображать архитектурный подход, которого я придерживался, чтобы получить подготовку и использование возможностей генерации текста, лежащих в основе этого первого и последующих примеров.
Предварительный просмотр архитектуры
Даже если демонстрация сосредоточена на задаче генерации текста, большая часть контента, связанного с управлением моделями, может быть абстрагирована. Например, мы можем выделить три отдельных шага, которые доказали свою пригодность для множества различных сценариев использования и ситуаций:
- Обучение: то, к чему в основном привыкли многие в этой области; исследовать лучший подход, определять архитектуру / алгоритм, обрабатывать данные, обучать и тестировать модели.
- Обслуживание: представьте обученные модели для использования.
- Потребление: используйте представленные модели для получения прогнозов на основе необработанных данных.
Разница между двумя последними шагами более тонкая и сильно зависит от рабочей настройки и того, что определяется как модель . Для начала подумайте о том, какая часть предварительной обработки данных, которую вы выполнили для обучения, на самом деле не встроена в ваше фактическое обучение с использованием Keras (или любой другой библиотеки, если на то пошло). Вся эта работа просто переходит к следующему архитектурному блоку, но должна быть отложена до потребляющего промежуточного программного обеспечения, чтобы мы могли предоставить только базовые требуемые возможности через чистый интерфейс.
Здесь схематический обзор наших архитектурных шагов и взаимодействий.
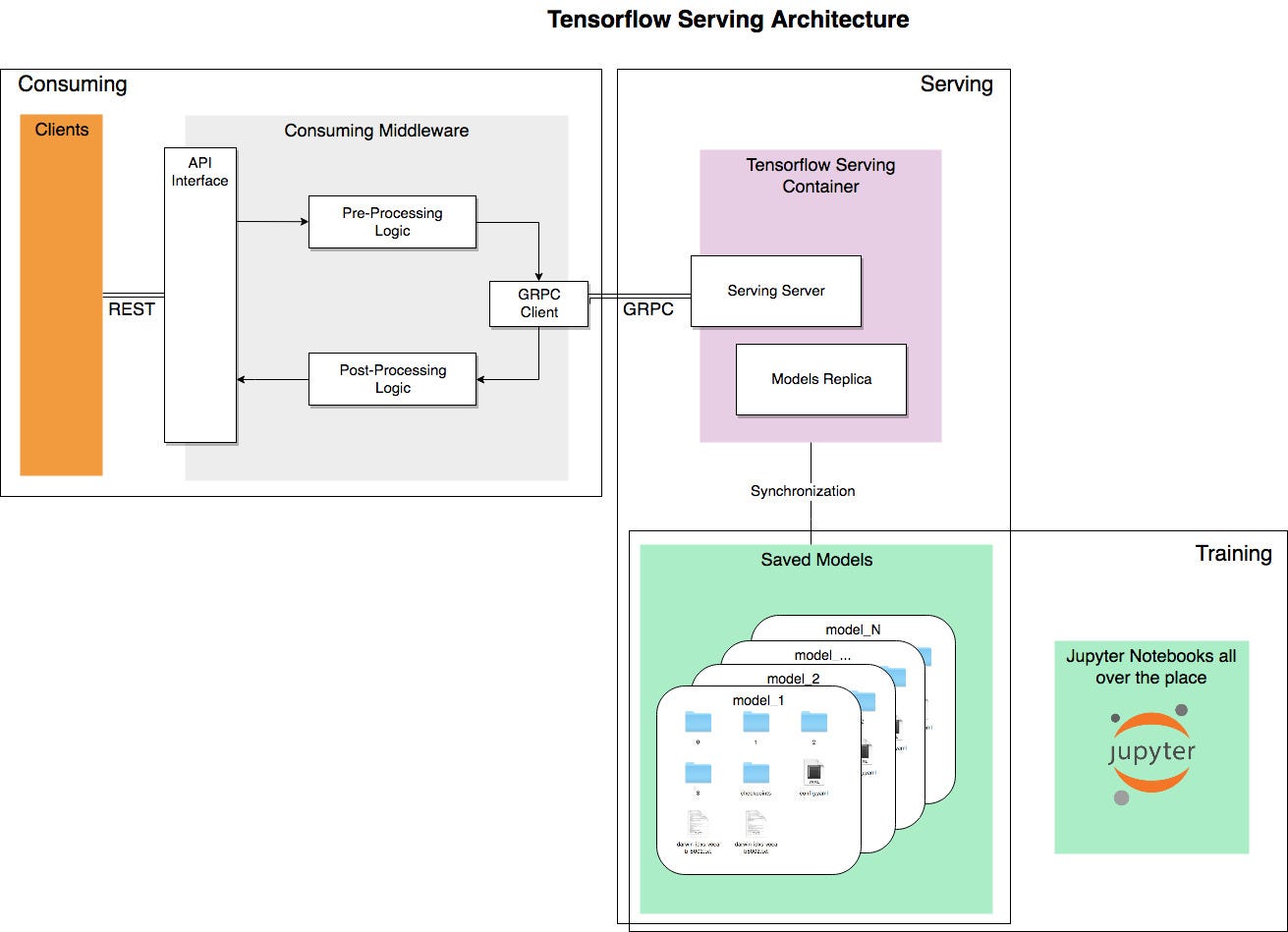
Обучение
Я не буду вдаваться в технические детали обучения генерации текста, но если интересно, вы можете найти большую часть обучающего кода для этой статьи, а также дополнительные указатели и ресурсы в этом блокноте Jupyter.
Хорошая особенность обслуживающей архитектуры заключается в том, что обучение может быть полностью отделено от других компонентов. Это обеспечивает быструю, простую и прозрачную доставку улучшенных версий за счет предоставления более эффективных моделей. Более качественные обучающие данные, более контролируемая процедура обучения, реализация более сложного алгоритма или тестирование новой архитектуры - все это варианты, которые могут генерировать лучшие модели, которые, в свою очередь, могут, по-видимому, заменить те, которые обслуживаются в настоящее время.
Что касается аспектов, которые нарушают то, что в противном случае было бы идеальным разъединением, рассмотрим, например, следующие наиболее важные зависимости:
- подпись модели (форма и тип входов / выходов), которая должна быть известна клиенту и следовать ей. В настоящее время нет возможности обнаружить это непосредственно с обслуживающего сервера, поэтому согласование с этапом обучения необходимо гарантировать «вручную», чтобы избежать ошибок. После определения сигнатуры вы можете обслуживать модели для новых версий или тестировать новые архитектуры без дополнительных затрат, если она согласована для всех таких моделей.
- предварительная и постобработка, выполняемая во время обучения, должна быть «воспроизведена» на уровне потребления.
- внешние / дополнительные данные модели (например, индексы слов) для предварительной / постобработки должны быть доступны потребляющему слою, при этом гарантируя соответствие тому, что использовалось во время обучения.
Модели
Модели - это результаты нашего тренировочного процесса. Мы можем классифицировать их сначала по их функциям (например, классификация, создание текста, вопросы и ответы), а затем по версии.
В нашем случае создания текста мы могли бы рассмотреть модели для обслуживания различных функций в зависимости от текстового содержимого, на котором они обучаются, даже если основная задача практически одинакова. В большинстве сценариев процесс / код обучения будут фактически одинаковыми, вместо этого будут использоваться используемые данные обучения. В этом случае управление версиями будет специфичным для этой функции и содержимого модели и может быть определено в простейшем случае с помощью базовых снимков в процессе обучения нескольких эпох или иным образом путем принятия или тестирования новых алгоритмов и архитектур.
Идея состоит в том, чтобы иметь центральный репозиторий множества моделей, куда можно добавлять новые обученные версии по мере необходимости.
В качестве практического примера рассмотрим этот снимок моей папки для базовой генерации текста с нашими тремя моделями, каждая из которых имеет несколько возможных версий, готовых к обслуживанию, более детализированный выбор контрольных точек обучения (или снимков) и данных для индексации слов.

Обслуживание
Когда модели готовы, нужен способ их обслуживать: сделать их доступными для эффективного и результативного использования.
«TensorFlow Serving - это гибкая, высокопроизводительная система обслуживания моделей машинного обучения, разработанная для производственных сред». Это отличный и незамедлительный подход для тех, кто уже знаком с Tensorflow и не в настроении писать свою собственную обслуживающую архитектуру.
Он включает автоматическое управление моделями на основе соответствующего каталога моделей и предоставляет их через GRPC. Сверху вишня, ее легко докеризовать.

У вас может быть копия всех ваших моделей и связанных версий на машине, на которой запущен сервер Tensorflow, или вы уже можете фильтровать, исходя из потребностей в более легком обслуживающем контейнере. Затем вы можете указать, какую модель запускать напрямую или через файл конфигурации модели, который необходимо передать при запуске обслуживающего сервера. В файле должен быть указан список конфигураций моделей для всех моделей, которые мы планируем выставить.
Затем Tf позаботится об обслуживании каждой из перечисленных моделей и автоматически управляет версией. Добавление новой версии будет автоматически выполнено Tensorflow, в то время как внедрение совершенно новой модели потребует перезапуска обслуживающей службы.
Все это можно сделать вручную, но для производственной настройки можно было бы предпочесть разработать утилиту «синхронизации», которая должна заботиться о синхронизации данных модели внутри обслуживающего контейнера Tensorflow из любого внешнего хранилища, в котором размещаются фактические результаты обучения. шаг.
Потребление
Рассмотрим наш текущий вариант использования: мы хотим получить сгенерированный текст определенного типа или из определенного источника и, возможно, обусловленный исходным текстом. К сожалению, конечная точка, обслуживающая чистый Tensorflow, работает далеко не так быстро. Нам нужно не только преобразовать текст (туда и обратно), но мы также должны реализовать процедуру генерации, которую мы хотели бы сделать полностью прозрачной в конечном интерфейсе. Все это должно быть отложено до промежуточного программного обеспечения потребителя и реализовано им.
Это будет характерно для многих других сценариев науки о данных, где экспортированная модель на самом деле является лишь частичным шагом в конвейере от сырых данных до пригодных для использования прогнозов. Потребительское промежуточное ПО потребуется для заполнения этих пробелов до и после обработки, как показано в исходной архитектурной схеме. В нашем случае с генерацией текста это промежуточное ПО и связанный с ним код снова определены в моем репозитории Github. Он включает в себя базовый класс, отвечающий за предварительную и постобработку текста, процедуру генерации текста (которая основывается на нескольких вызовах моделей и вторичных требованиях) и прокси для обработки различных моделей.
Прокси-сервер можно использовать напрямую, предполагая, что необходимые зависимости разрешены, в противном случае я предлагаю еще больше упростить задачу и представить все как действительно базовый REST API: с Python и Flask действительно нужна пара строк. Кроме того, модульность всех наших компонентов позволяет легко переносить и масштабировать решение с помощью таких технологий, как Docker и AWS.
Время витрины!
Как на самом деле использовать описанную до сих пор установку - это чистое дело воображения и потребностей (эта статья прекрасно исследует различные формы машинного письма). Лучшим аспектом является именно то, что теперь у нас есть гибкая архитектура, которую можно многократно использовать для всех сценариев без особой дополнительной нагрузки.
Первый практический пример, который я приготовил и который сейчас активно использую, - это плагин для базового текстового редактора. В моем случае я полагаюсь на Sublime 3 и Notepad ++. Написание плагина для первого было довольно тривиальным после того, как у меня был запущен и запущен API генерации текста; на самом деле это весь необходимый код.
Что здесь происходит, так это то, что я что-то пишу сам, выбираю текст, который хочу использовать в качестве начального числа, а затем вызываю генерацию на предпочтительной модели. Вот еще одна демонстрация. Еще раз обратите внимание, что здесь я полагаюсь на три разные модели, обученные соответственно текстам песен, Библии в версии короля Якова и книге Дарвина О происхождении видов.

Этот «плагин для текстовых приложений» позволяет мне придумывать или черпать вдохновение из контента (будь то полные предложения или отдельные слова), которые в противном случае редко бы возникли из моего чисто спонтанного письма. Хотя более творческий контекст повествования и поэзии, кажется, позволяет лучше использовать этот инструмент, я часто нахожу полезные советы также для более формального и «строгого» контента, полагаясь на исходный набор данных, используемый для обучения. , будучи уверенным, что «скорее подразумевает правильность».
Еще одно использование, над которым я работаю, - это плагин веб-браузера для автоматического ответа в чате и мгновенных сообщениях, опять же путем простого использования открытого REST API. Посмотрим, сколько моих друзей могут отличить меня от RNN.


Выводы
Возможности создания текста методами на основе глубокого обучения уже доказаны для множества различных вариантов использования и сценариев. В этой статье я показал, как базовое архитектурное решение на основе Tensorflow может гарантировать высокую гибкость и эффективность при создании практичного небольшого набора инструментов для генерации текста для вашего внутреннего писателя.
Я также уверен, что вскоре мы увидим более структурированный, детализированный и демократичный доступ к предварительно обученным моделям. Что-то вроде репозитория самообслуживания - наподобие других популярных сервисов - такого, что можно легко подключать и запускать новые модели и встраивать их напрямую в любой контекст по выбору, без необходимости обучать их практически с нуля.
В контексте этой статьи, например, было бы неплохо иметь доступ к моделям, обученным другими для различных задач, текстовому контенту или авторам, а также иметь возможность поделиться результатами моего собственного обучения на общая платформа или модель-хаб.
Но теперь уходи; эффективно использовать эти мощные машины в производственных и творческих целях; скоро они станут слишком умными для этой задачи.