Base64 — одна из основных схем кодирования данных. Он преобразует документы с 8-битными данными, такими как электронные письма, в код ASCII. Он также используется для встраивания изображений в веб-сайты. Например, в Python есть модуль base64 для поддержки этих кодировок и декодирования, который можно легко использовать, как показано ниже.
>>>import base64 >>>string = "string to be encoded" >>>encoded = base64.b64encode(b'string') b'c3RyaW5n' >>decoded = base64.b64decode(encoded) b'string'
Здесь мы рассмотрим Base64 без использования этих библиотек, чтобы полностью понять, что происходит.
Как это работает?
Сначала рассмотрим схему кодирования. В качестве примера закодируем строку «Hello».
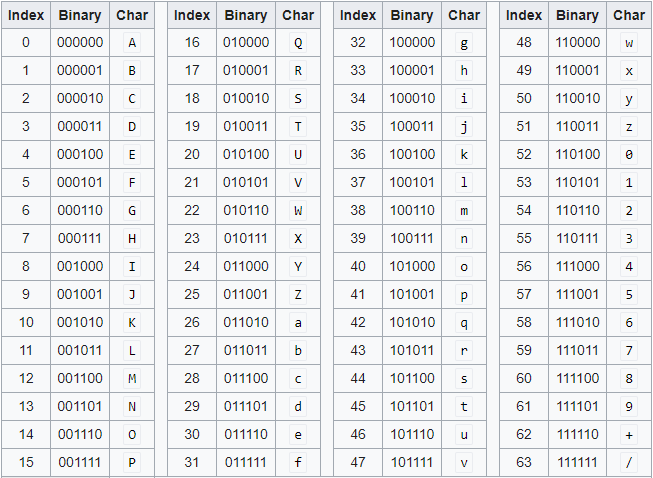
Сначала мы преобразуем каждый символ в шестнадцатеричный код, а затем преобразуем его в двоичный. Затем мы разбиваем его на группу из 6 бит. Если последняя группа короче 6 бит, добавьте 0. Для каждой группы преобразуйте ее в соответствующий символ, используя таблицу Base64. Эту таблицу можно найти в Интернете. Затем мы группируем его в 4 символа. Если последняя группа меньше 4 символов, добавьте =.
H | e | l | l | o
0x48 | 0x65 | 0x6c | 0x6c |0x6f
01001000 | 01100101 | 01101100 | 01101100 | 01101111
010010 | 000110 | 010101 | 101100 | 011011 | 000110 | 111100
S | G | V | s | b | G | 8
SGV | bG8=
Итак, теперь у нас есть «SGVsbG8=».
Далее рассмотрим схему расшифровки.
При декодировании строки нужно быть осторожным, чтобы не декодировать знак = полностью. = появляется в конце строки и не более 2 раз. После этого нам просто нужно проследить схему кодирования.
Декодирование кода в Python
def decode_base64(ct):
#remove = if there is one
ct = ct.replace('=', '')
#from the base64 table, convert it to binary
base64_dict = {"110000": "w", "110001": "x", "110101": "1", "110100": "0", "010100": "U", "010101": "V", "001100": "M", "001101": "N", "011110": "e", "011111": "f", "001001": "J", "001000": "I", "011011": "b", "011010": "a", "000110": "G", "000111": "H", "000011": "D", "000010": "C", "100100": "k", "100101": "l", "111100": "8", "111101": "9", "100010": "i", "100011": "j", "101110": "u", "101111": "v", "111001": "5", "111000": "4", "101011": "r", "101010": "q", "110011": "z", "110010": "y", "010010": "S", "010011": "T", "010111": "X", "010110": "W", "110110": "2", "110111": "3", "011000": "Y", "011001": "Z", "001111": "P", "001110": "O", "011101": "d", "011100": "c", "001010": "K", "001011": "L", "101101": "t", "000000": "A", "000001": "B", "100111": "n", "100110": "m", "000101": "F", "000100": "E", "111111": "/", "111110": "+", "100001": "h", "100000": "g", "010001": "R", "010000": "Q", "101100": "s", "111010": "6", "111011": "7", "101000": "o", "101001": "p"}
ct_bi = ""
for i in ct:
keys = [k for k, v in base64_dict.items() if v == i]
keys_str = "".join(keys)
ct_bi += keys_str
#brake it into 8 bits, remove the 0 left
ct_bi = [ct_bi[i:i+8] for i in range(0, len(ct_bi), 8)]
if len(ct_bi[-1]) != 8:
ct_bi.pop()
#convert to binary
ct_binary = []
for i in ct_bi:
ct_binary.append(i.encode())
#convert to hex
ct_hex = []
for i in ct_binary:
ct_hex.append(hex(int(i, 2)))
#convert to char
ct_decode = ""
for i in ct_hex:
ct_decode += chr(int(i, 16))
return ct_decode
Приведенным выше кодом можно декодировать правильно закодированную строку. Однако, чтобы использовать это на практике, вы должны иметь дело с неожиданными символами, которые могут появиться в исходной строке.
Одна проблема с этой схемой кодирования заключается в том, что она значительно увеличивает объем данных. Поэтому отправка больших файлов по электронной почте не очень эффективна.
Иногда полезно кодировать без использования библиотек, чтобы углубить свое понимание!