Думаю, в 2017 году объяснять значение таких терминов, как машинное обучение и искусственный интеллект, не нужно. Вы можете найти множество обзорных статей и научных работ на эту тему. Итак, я предполагаю, что читатель знаком с темой и знает определения основных терминов. Говоря о машинном обучении, исследователи данных и инженеры-программисты обычно имеют в виду глубокие нейронные сети, которые стали довольно популярными из-за своей производительности. На сегодняшний день существует множество программных решений и пакетов для решения задач искусственных нейронных сетей: Caffe, TensorFlow, Torch, Theano(рип), cuDNN и др.
Быстрый
Swift — это инновационный язык программирования с открытым исходным кодом, ориентированный на протоколы, написанный в Apple Крисом Латтнером (который недавно покинул Apple и после SpaceX обосновался в Google).
В Apple OS уже есть различные библиотеки для работы с матрицами и векторной алгеброй. , такие как BLAS, BNNS, DSP, которые впоследствии были собраны в единую библиотеку Accelerate.
В 2015 году появились мелкомасштабные решения на основе графической технологии Metal для реализации математики.
В 2016 году CoreML был представлен:
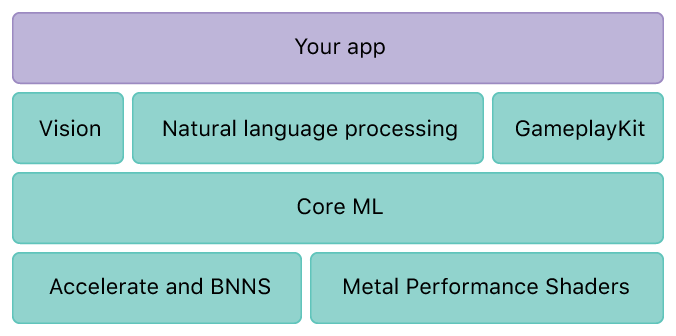
CoreML может импортировать готовую и обученную модель (CaffeV1, Keras, scikit-learn) и позволяет разработчику экспортировать ее в приложение.
Итак, в первую очередь нужно подготовить модель на другой платформе с помощью Python или язык C++ и сторонние платформы. Во-вторых, вам необходимо обучить его с помощью стороннего аппаратного решения.
Только после этого вы сможете импортировать его и начать работать с языком Swift. Как по мне, все это кажется слишком сложным.
ТензорФлоу
TensorFlow, как и другие программные пакеты, реализующие искусственные нейронные сети, предоставляет множество готовых абстракций и механизмов для работы с элементами обработки, связями между ними, оценкой ошибок и обратным распространением. Однако отличие TensorFlow от других пакетов заключается в том, что Джефф Дин (сотрудник Google, автор DFS, TensorFlow и многих других замечательных решений) решил внедрить в TensorFlow идею разделения модели исполнения данных и процесса выполнения данных. Это означает, что в первую очередь нужно описать так называемый граф вычислений, а уже после этого запускать процесс вычислений. Такой подход позволяет разделить и добавить гибкости работе с моделью исполнения данных и самим процессом исполнения данных, разделив выполнение на разные блоки (процессоры, видеокарты, компьютеры и кластеры). ).
TensorFlowKit
Для решения всех перечисленных задач, начиная от подготовки модели и заканчивая работой с ней в финальном приложении, я написал интерфейс, предоставляющий доступ и позволяющий работать с TensorFlow на одном языке.
Архитектура решения состоит из двух уровни: средний и высокий.
- На низком уровне C-модуль позволяет общаться с libtensorflow с помощью языка Swift.
- На среднем уровне можно перейти от использования указателей C к работе с «понятными ошибками».
- Высокий уровень реализует различные абстракции, используемые для доступа к элементам модели, и различные утилиты для экспорта, импорта и визуализации графиков.

Таким образом, вы можете создать модель (график расчета) с помощью Swift, обучить ее на сервере под управлением ОС Ubuntu с использованием нескольких видеокарт, а после этого легко открыть ее в своем приложении, работающем на Mac OS или tvOS. Разработку можно вести с помощью знакомого Xcode со всеми его достоинствами и недостатками.
Документация и API находятся по этой ссылке.
Кратко о теории нейронных сетей
Искусственные нейронные сети реализуют модель, напоминающую упрощенную модель нейронных связей в тканях нервной системы. Входной сигнал в виде вектора большой размерности поступает на входной слой, состоящий из обрабатывающих элементов. После этого каждый входной элемент обработки преобразует сигнал на основании свойств связи (весов) между элементами обработки и свойств элементов обработки следующих слоев и передает сигнал следующему слою. В процессе обучения формируется сигнал наводки и сравнивается с ожидаемым. Основываясь на различиях между фактическим сигналом датчика и ожидаемым сигналом, определяется частота ошибок. В дальнейшем эта ошибка используется для расчета так называемой оценки. Градация — это вектор, в направлении которого нужно корректировать связи между элементами обработки, чтобы сеть в дальнейшем выдавала сигналы, аналогичные ожидаемым. Этот процесс называется обратным распространением. Таким образом, обрабатывающие элементы и связи между ними накапливают информацию, необходимую для обобщения свойств модели данных, которую реализует в данный момент текущая нейронная сеть. Техническая реализация сводится к различным математическим операциям над матрицами и векторами, которые, в свою очередь, в той или иной степени уже реализованы такими решениями, как BLAS, LAPACK, DSP и др.

МНИСТ
- TensorFlowKit на GitHub [Добавьте репозиторий в свои старты!]
- Пример MNIST на GitHub [Добавьте репозиторий в свои старты!]
- MNISTKit на GitHub [Добавьте репозиторий в свои старты!]
- ТензорФлоу API
Я взял Hello World! во вселенной нейронных сетей как пример задача по систематизации изображений MNIST. Набор данных MNIST включает в себя тысячи изображений рукописных чисел, размер каждого изображения составляет 28×28 пикселей. Итак, у нас есть десять классов, которые аккуратно разделены на 60 000 изображений для обучения и 10 000 изображений для тестирования. Наша задача — создать нейронную сеть, способную классифицировать изображение и определять, к какому классу оно относится (из 10 классов).
Прежде чем вы сможете начать работать с TensorFlowKit, вам необходимо установить TensorFlow. На Mac OS вы можете использовать менеджер пакетов brew:
Сборка для Linux доступна здесь.
Давайте создадим проект Swift и добавим зависимость:
Теперь нам нужно подготовить набор данных MNIST.
Я написал Пакет Swift для работы с набором данных MNIST, который вы можете найти здесь. Этот пакет загрузит набор данных во временную папку, распакует его и представит в виде готовых к использованию классов.
Например:
Теперь давайте создадим необходимый граф операций.
Пространство и подпространство расчетного графа называется областью видимости и может иметь собственное имя. Мы предоставим два вектора для входных данных сети. Первый содержит изображения, представленные в виде вектора высокой размерности 784 (28×28 пикселей). Таким образом, каждый компонент вектора x будет содержать значение Float от 0,0 до 1,0, соответствующее цвету пикселя на изображении. Второй вектор будет зашифрованным соответствующим классом (см. ниже), где соответствующий компонент 1 соответствует номеру класса. В следующем примере это класс 2.
Поскольку входные параметры будут меняться в процессе обучения, давайте создадим заполнитель для ссылки на них.
Вот так Input выглядит на графике:
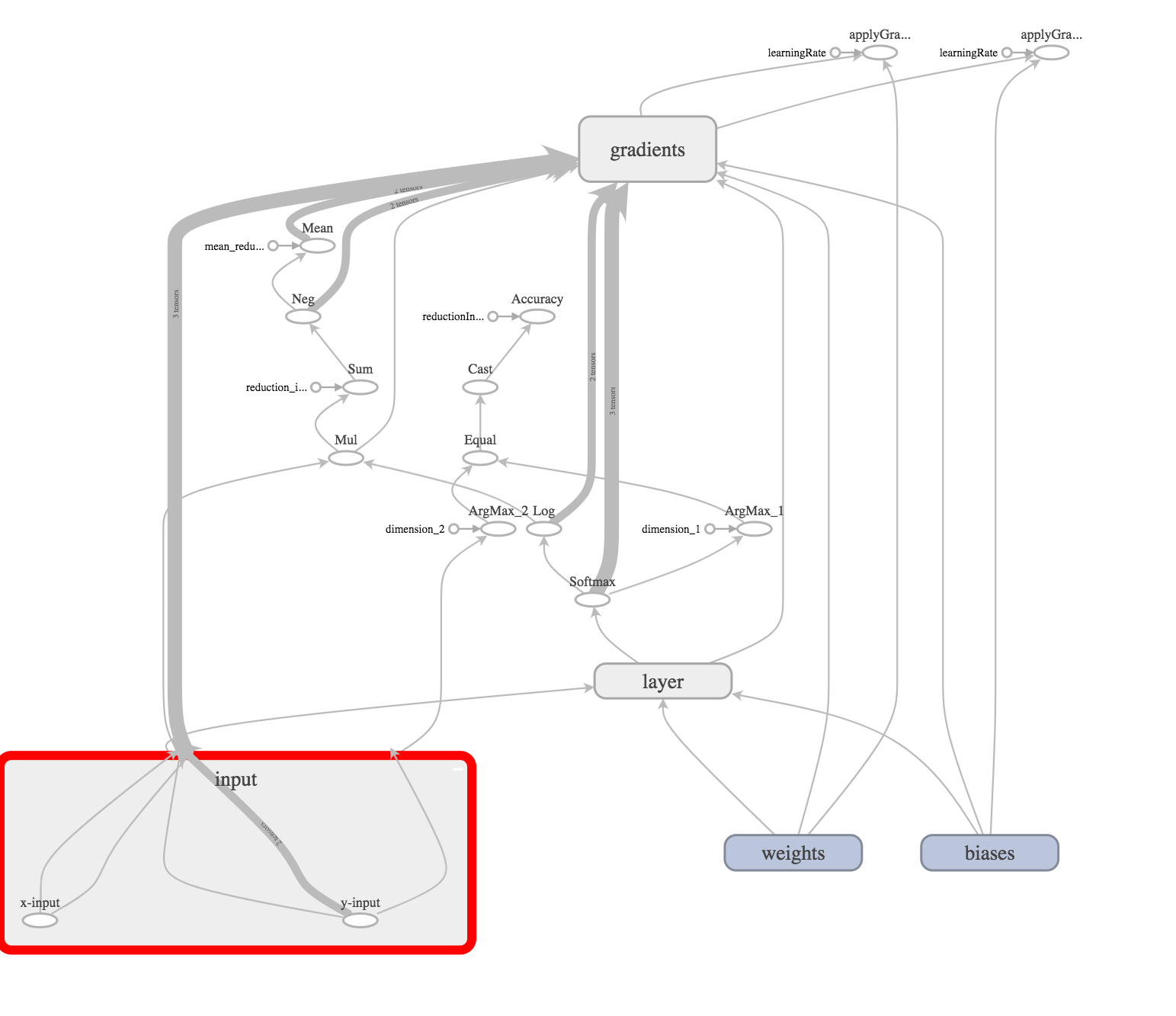
Это наш входной слой. Теперь давайте создадим веса (связи) между входным и скрытым слоями.
Мы создадим переменную операцию на графике, потому что веса и основания будут настроены в процессе обучения. Давайте инициализируем их, используя тензор, заполненный нулями.

Теперь давайте создадим скрытый слой, который будет выполнять такую примитивную операцию, как (x * W) + b. Эта операция умножает вектор x (размер 1×784) на матрицу W (размер 784×10) и добавляет базис.
В нашем случае скрытый слой — это выходной слой (задача уровня Hello World!), поэтому нам необходимо проанализировать выходной сигнал и определить победителя. Для этого мы должны использовать операцию softmax.

Я предлагаю рассматривать нашу нейронную сеть как сложную функцию, чтобы лучше понять, о чем я буду говорить дальше. Мы вводим вектор x (представляющий изображение) в нашу функцию. На выходе мы получаем вектор, который показывает вероятность принадлежности входного вектора каждому из доступных классов.
Теперь возьмем натуральный логарифм полученной вероятности для каждого класса и умножим на аккуратно переданное в самом начале значение вектора нужного класса (yLabel). Таким образом мы получим значение ошибки и будем использовать его для «оценки» нейронной сети. На рисунке ниже показаны два образца. В первом примере для класса 2 значение ошибки равно 2,3, а во втором примере для класса 1 значение ошибки равно 0.

Что делать дальше?
Говоря математическим языком, мы должны минимизировать целевую функцию. Для этого можно использовать метод градиентного спуска. Если возникнет необходимость, я постараюсь описать этот метод в другой статье.
Итак, мы должны вычислить, как скорректировать каждый из весов (составляющих матрицы W) и базисный вектор b, чтобы нейронная сеть делала меньшую ошибку при получении аналогичные входные данные. В контексте математики мы должны найти частные производные выходного узла по значениям всех промежуточных узлов. Имеющиеся у нас символические градиенты позволяют «перемещать» значения переменных W и b в зависимости от того, насколько это повлияло на результат предыдущих вычислений.
Магия TensorFlow
Дело в том, что TensorFlow может выполнять все (правда, не все в данный момент) эти сложные вычисления автоматически, анализируя созданный нами граф.
После вызова этой операции TensorFlow создаст еще около пятидесяти операций.

Теперь достаточно добавить операцию обновления весов до значения, которое мы получили ранее методом градиентного спуска.
Вот и все — график готов!

Как я уже сказал, TensorFlow разделяет модель и расчеты. Поэтому созданный нами график является лишь моделью для выполнения расчетов. Мы можем использовать Session, чтобы начать процесс вычисления. Подготовим данные из датасета, поместим в тензоры и запустим сессию.
Диапазон ошибок отображается после каждых 100 операций. В следующей статье я расскажу, как рассчитать точность нашей сети и как ее визуализировать средствами TensorFlowKit.
Вы можете добавить Репозиторий TensorFlowKit, чтобы начать следить за будущими изменениями.