В прошлом году AlphaGo из DeepMind обыграла чемпиона мира по го Ли Седола со счетом 4–1. Более 200 миллионов человек наблюдали, как обучение с подкреплением (RL) вышло на мировую арену. Несколькими годами ранее DeepMind произвел фурор с помощью бота, который мог играть в игры Atari. Вскоре компания была приобретена Google.
Многие исследователи считают, что RL - наш лучший шанс создать общий искусственный интеллект. Это захватывающая область с множеством нерешенных проблем и огромным потенциалом.
Хотя поначалу это может показаться сложным, начать работу в RL на самом деле не так уж и сложно. В этой статье мы создадим простого бота с Керасом, который сможет играть в игру Catch.
Игра

Catch - очень простая аркадная игра, в которую вы, возможно, играли в детстве. Фрукты падают сверху экрана, и игроку приходится ловить их корзиной. За каждый пойманный фрукт игрок получает очко. За каждый потерянный фрукт игрок теряет одно очко.
Цель здесь - позволить компьютеру играть в Catch самостоятельно. Но мы не будем использовать красивую игру выше. Вместо этого мы воспользуемся упрощенной версией, чтобы упростить задачу:

Играя в Catch, игрок выбирает одно из трех возможных действий. Они могут перемещать корзину влево, вправо или оставаться на месте.
Основанием для этого решения является текущее состояние игры. Другими словами: положение падающих фруктов и корзины.
Наша цель - создать модель, которая, учитывая содержимое игрового экрана, выбирает действие, которое приводит к максимально возможному количеству очков.
Эту задачу можно рассматривать как простую задачу классификации. Мы могли бы попросить опытных игроков-людей поиграть в игру много раз и записывать свои действия. Затем мы могли бы обучить модель выбирать «правильное» действие, отражающее опытных игроков.
Но люди учатся не так. Люди могут изучить такую игру, как Catch, самостоятельно, без руководства. Это очень полезно. Представьте, что вам нужно нанять группу экспертов для выполнения задачи тысячи раз каждый раз, когда вы хотите узнать что-то столь же простое, как Catch! Это будет дорого и медленно.
При обучении с подкреплением модель обучается на опыте, а не на размеченных данных.
Глубокое обучение с подкреплением
Обучение с подкреплением вдохновлено поведенческой психологией.
Вместо того, чтобы предлагать модели «правильные» действия, мы предоставляем ей награды и наказания. Модель получает информацию о текущем состоянии окружающей среды (например, экран компьютерной игры). Затем он выдает действие, подобное движению джойстика. Окружение реагирует на это действие и обеспечивает следующее состояние вместе с любыми наградами.

Затем модель учится находить действия, которые приводят к максимальному вознаграждению.
На практике это может работать разными способами. Здесь мы рассмотрим Q-Learning. Q-Learning произвел фурор, когда его использовали для обучения компьютера игре в игры Atari. Сегодня это все еще актуальное понятие. Большинство современных алгоритмов RL представляют собой некоторую адаптацию Q-Learning.
Q-Learning интуиция
Хороший способ понять Q-обучение - сравнить игру в Catch с игрой в шахматы.
В обеих играх вам дано состояние S. В шахматах это расположение фигур на доске. В Catch это расположение фруктов и корзины.
Затем игрок должен выполнить действие A. В шахматах это движение фигуры. В Catch это перемещение корзины влево или вправо или сохранение в текущем положении.
В результате будет некоторая награда R и новое состояние S’.
Проблема как с Catch, так и с шахматами заключается в том, что награды не появляются сразу после действия.
В Catch вы получаете награду только тогда, когда фрукты попадают в корзину или падают на пол, а в шахматах вы получаете награду только тогда, когда выигрываете или проигрываете игру. Это означает, что вознаграждения распределяются редко. В большинстве случаев R будет нулевым.
Когда есть награда, она не всегда является результатом действия, предпринятого непосредственно перед этим. Некоторые действия, предпринятые задолго до этого, могли стать причиной победы. Выяснение того, какое действие отвечает за вознаграждение, часто называют проблемой присвоения кредита.
Поскольку награды откладываются, хорошие шахматисты не выбирают свою игру только по немедленной награде. Вместо этого они выбирают по ожидаемому будущему вознаграждению.
Например, они не только думают о том, смогут ли они исключить фигуру соперника следующим ходом. Они также думают, как определенные действия сейчас помогут им в долгосрочной перспективе.
В Q-обучении мы выбираем свое действие, основываясь на наивысшей ожидаемой будущей награде. Мы используем Q-функцию, чтобы вычислить это. Это математическая функция, которая принимает два аргумента: текущее состояние игры и заданное действие.
Мы можем записать это как: Q(state, action)
Находясь в состоянии S, мы оцениваем будущую награду за каждое возможное действие A. Мы предполагаем, что после того, как мы выполнили действие A и перешли в следующее состояние S’, все работает отлично.
Ожидаемое будущее вознаграждение Q(S,A) для данного состояния S и действия A рассчитывается как немедленное вознаграждение R плюс ожидаемое будущее вознаграждение после этого Q(S',A'). Мы предполагаем, что следующее действие A' является оптимальным.
Поскольку есть неопределенность в отношении будущего, мы дисконтируем Q(S’,A’) на коэффициент гамма γ.
Q(S,A) = R + γ * max Q(S’,A’)
Хорошие шахматисты очень хорошо мысленно прикидывают будущие награды. Другими словами, их Q-функция Q(S,A) очень точна.
Большая часть шахматной практики вращается вокруг улучшения Q-функции. Игроки просматривают множество старых игр, чтобы узнать, как конкретные ходы разыгрывались в прошлом и насколько вероятно, что данное действие приведет к победе.
Но как машина может оценить хорошую Q-функцию? Здесь в игру вступают нейронные сети.
В конце концов, регресс
Играя в игру, мы получаем много «впечатлений». Этот опыт состоит из:
- начальное состояние,
S - предпринятые действия,
A - заработанная награда,
R - и последующее состояние
S’
Эти опыты - наши тренировочные данные. Мы можем сформулировать проблему оценки Q(S,A) как проблему регрессии. Чтобы решить эту проблему, мы можем использовать нейронную сеть.
Учитывая входной вектор, состоящий из S и A, нейронная сеть должна предсказывать значение Q(S,A), равное цели: R + γ * max Q(S’,A’).
Если мы хорошо умеем предсказывать Q(S,A) для различных состояний S и действий A, у нас есть хорошее приближение Q-функции. Обратите внимание, что мы оцениваем Q(S’,A’) с помощью той же нейронной сети, что и Q(S,A).
Учебный процесс
С учетом набора опыта < S, A, R, S’ > процесс обучения выглядит следующим образом:
- Для каждого возможного действия
A’(влево, вправо, оставаться) спрогнозируйте ожидаемую будущую наградуQ(S’,A’)с помощью нейронной сети. - Выберите наивысшее значение из трех прогнозов как
max Q(S’,A’). - Рассчитайте
r + γ * max Q(S’,A’). Это целевое значение для нейронной сети. - Обучите нейронную сеть, используя функцию потерь. Это функция, которая вычисляет, насколько близко или далеко прогнозируемое значение от целевого значения. Здесь мы будем использовать
0.5 * (predicted_Q(S,A) — target)²в качестве функции потерь.
Во время игры все впечатления сохраняются в памяти повторов. Это действует как простой буфер, в котором мы храним < S, A, R, S’ > пар. Класс воспроизведения опыта также занимается подготовкой данных для обучения. Посмотрите код ниже:
Определение модели
Теперь пора определить модель, которая будет изучать Q-функцию для Catch.
Мы используем Keras в качестве интерфейса для Tensorflow. Наша базовая модель представляет собой простую трехуровневую плотную сеть.
Эта модель уже неплохо работает с этой простой версией Catch. Перейдите на GitHub для полной реализации. Вы можете поэкспериментировать с более сложными моделями, чтобы увидеть, сможете ли вы повысить производительность.
Исследование
Последний ингредиент Q-Learning - исследование.
Повседневная жизнь показывает, что иногда вам нужно делать что-то странное и / или случайное, чтобы узнать, есть ли что-то лучше, чем ваша повседневная рысь.
То же самое и с Q-Learning. Всегда выбирая лучший вариант, вы можете упустить некоторые неизведанные пути. Чтобы этого избежать, учащийся иногда выбирает случайный вариант, и не обязательно лучший.
Теперь мы можем определить метод обучения:
Я позволил игре тренироваться 5000 эпох, и сейчас она неплохо справляется!
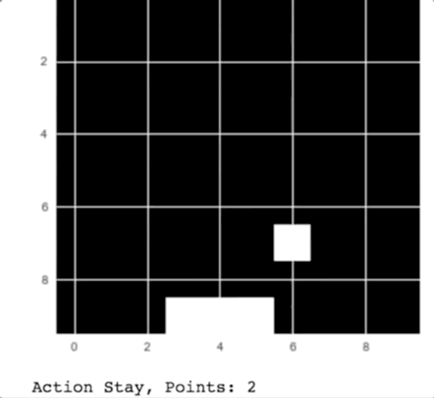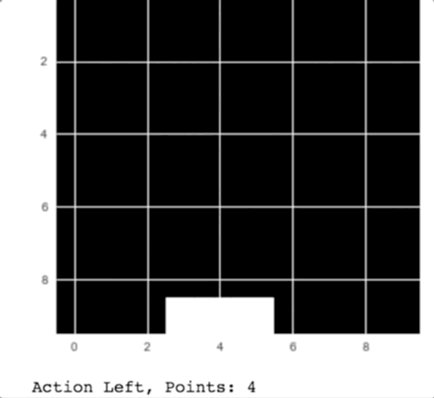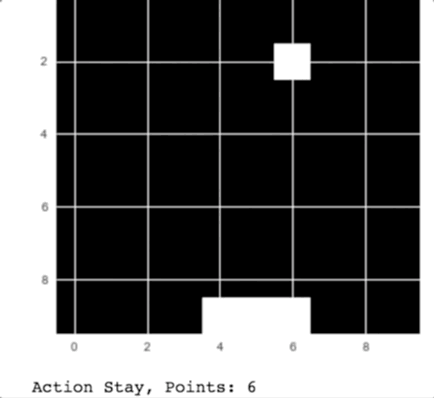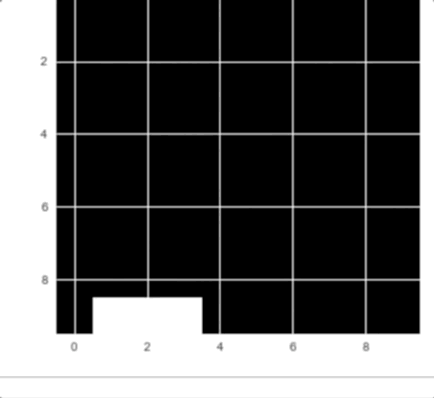
Как вы можете видеть на анимации, компьютер ловит падающие с неба яблоки.
Чтобы визуализировать процесс обучения модели, я построил скользящую среднюю побед по эпохам:

Куда пойти отсюда
Теперь вы получили первый обзор и интуитивное понимание RL. Я рекомендую взглянуть на полный код этого урока. Вы можете поэкспериментировать с этим.
Вы также можете посмотреть Сериал Артура Джулиани. Если вы хотите более формального представления, взгляните на Stanford’s CS 234, Berkeley’s CS 294 или Лекции Дэвида Сильвера из UCL.
Отличный способ практиковать свои навыки RL - OpenAI’s Gym, который предлагает набор обучающих сред со стандартизованным API.
Благодарности
Эта статья основана на простом примере RL Эдера Сантаны из 2016 года. Я реорганизовал его код и добавил пояснения в записную книжку, которую написал ранее в 2017 году. Для удобства чтения на Medium я показываю здесь только наиболее релевантный код. . Чтобы узнать больше, перейдите в блокнот или исходную запись Эдера.
О яннесе клаасе
Этот текст является частью материала курса Машинное обучение в финансовом контексте, который помогает студентам, изучающим экономику и бизнес, понять машинное обучение.
Я потратил десять лет на создание программного обеспечения и теперь нахожусь в пути, чтобы принести машинное обучение в финансовый мир. Я учусь в Роттердамской школе менеджмента и занимаюсь исследованиями в Институте жилищного строительства и городского развития.
Вы можете следить за мной в Твиттере. Если у вас есть вопросы или предложения, оставьте комментарий или напишите мне на Medium.