PostgreSQL 10 обещает более легкое разбиение на разделы для масштабирования больших данных. Но как это работает с рабочими нагрузками временных рядов? И как это соотносится с TimescaleDB?

PostgreSQL 10, официально выпущенный несколько недель назад, включает новую функцию под названием декларативное разбиение, предназначенную для масштабирования PostgreSQL для рабочих нагрузок с большими данными.
В TimescaleDB мы также работаем над масштабированием PostgreSQL, но в первую очередь для одного конкретного типа рабочей нагрузки с большими данными: данных временных рядов. Мы делаем это, создавая надстройку над уже существующими в PostgreSQL функциями разделения.
Мы часто слышим вопрос: как PostgreSQL 10 работает с данными временных рядов?
Этот пост отвечает на этот вопрос, исследуя проблемы, с которыми мы столкнулись при попытке использовать PostgreSQL 10 для рабочих нагрузок временных рядов, которые мы часто наблюдаем, посредством подробного сравнения подходов к разделению в PG10 и TimescaleDB.
В частности, это сообщение начинается с примера, а затем рассматривается многомерное разбиение. Из этого следует, что при более внимательном рассмотрении производительности вставки, производительности запросов, легкости перераспределения и управления таблицами.
Краткое введение в TimescaleDB и гипертаблицы
Для тех, кто не знаком с TimescaleDB, это расширение PostgreSQL для данных временных рядов, которое обеспечивает автоматическое разбиение таблиц с помощью гипертаблиц. Гипертаблицы обеспечивают масштабируемость за счет разделения данных по нескольким измерениям (обычно одно временное измерение и одно или несколько пространственных измерений), но в остальном выглядят и работают так же, как обычная таблица.
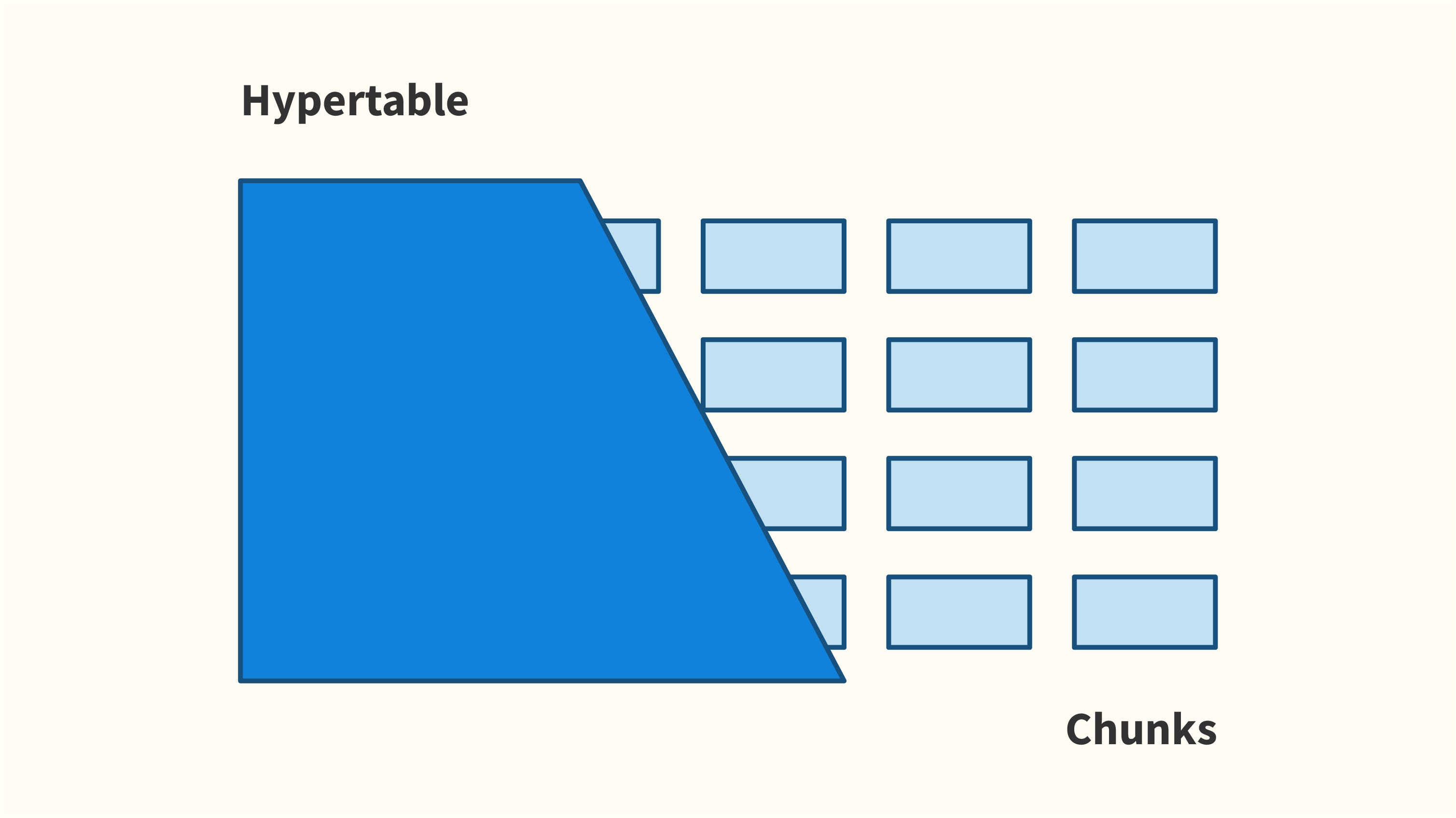
Другими словами, гипертаблица представляет собой абстракцию единой непрерывной таблицы по всем пространственным и временным интервалам, так что пользователь может запрашивать и взаимодействовать со всеми своими данными, как если бы они находились в обычной таблице. Это позволяет гипертаблицам увеличиваться до очень больших размеров, которые обычные таблицы PostgreSQL просто не могут поддерживать, сохраняя при этом знакомые функции управления. Под капотом гипертаблицы полагаются на старый механизм наследования таблиц PostgreSQL, на котором также построено декларативное секционирование.
Итак, с этой общей ДНК, как сравнить два разных подхода TimescaleDB и PostgreSQL 10?
Пример: от нуля до запроса
Лучший способ ответить на поставленный выше вопрос - это посмотреть на примере. Представьте себе сценарий данных временных рядов Интернета вещей, в котором датчики развертываются в зданиях для отслеживания температуры и влажности воздуха в помещении, обеспечивая оптимальные условия работы. Простая схема таблицы для хранения таких данных может выглядеть следующим образом:
CREATE TABLE conditions (
time timestamptz,
temp float,
humidity float,
device text
);
Чтобы масштабировать эту таблицу для большого количества данных временных рядов, нам потребуется разделить таблицу на два измерения: время и устройство. Это уменьшает размеры индекса и обеспечивает более быстрый доступ за счет исключения вложенных таблиц во время запроса. Для этого мы укажем четыре раздела устройств, в то время как измерение времени останется открытым с интервалом в одну неделю.
С TimescaleDB вам нужен только один дополнительный вызов функции для вставки вашего первого фрагмента данных:
-- Turn ‘conditions’ into a hypertable partitioned by time and device
SELECT create_hypertable(‘conditions’, ‘time’, ‘device’, 4, chunk_time_interval => interval ‘1 week’);
INSERT INTO conditions VALUES ('2017-10-03 10:23:54+01', 73.4, 40.7, 'sensor3');
При вставке TimescaleDB автоматически создает подтаблицы, называемые фрагментами, в соответствии с исходной спецификацией разделения (обратите внимание, что мы будем использовать «фрагменты» для обозначения разделов / вложенных таблиц в TimescaleDB). Он также будет создавать любые индексы, ограничения или триггеры для фрагментов, которые пользователь объявил в гипертаблице, в том числе по умолчанию для создания индекса времени для ускорения запросов.
Теперь, чтобы добиться чего-то подобного с декларативным разбиением PG10, вам необходимо:
-- Create device partitions
CREATE TABLE conditions_p1 PARTITION OF conditions
FOR VALUES FROM (MINVALUE) TO ('g')
PARTITION BY RANGE (time);
CREATE TABLE conditions_p2 PARTITION OF conditions
FOR VALUES FROM ('g') TO ('n')
PARTITION BY RANGE (time);
CREATE TABLE conditions_p3 PARTITION OF conditions
FOR VALUES FROM ('n') TO ('t')
PARTITION BY RANGE (time);
CREATE TABLE conditions_p4 PARTITION OF conditions
FOR VALUES FROM ('t') TO (MAXVALUE)
PARTITION BY RANGE (time);
-- Create time partitions for the first week in each device partition
CREATE TABLE conditions_p1_y2017m10w01 PARTITION OF conditions_p1
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
CREATE TABLE conditions_p2_y2017m10w01 PARTITION OF conditions_p2
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
CREATE TABLE conditions_p3_y2017m10w01 PARTITION OF conditions_p3
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
CREATE TABLE conditions_p4_y2017m10w01 PARTITION OF conditions_p4
FOR VALUES FROM ('2017-10-01') TO ('2017-10-07');
-- Create time-device index on each leaf partition
CREATE INDEX ON conditions_p1_y2017m10w01 (time);
CREATE INDEX ON conditions_p2_y2017m10w01 (time);
CREATE INDEX ON conditions_p3_y2017m10w01 (time);
CREATE INDEX ON conditions_p4_y2017m10w01 (time);
INSERT INTO conditions VALUES ('2017-10-03 10:23:54+01', 73.4, 40.7, 'sensor3');
Как видно из этого примера, декларативное разбиение на разделы является довольно мощным, но трудоемким в установке и настройке.
А для такого неограниченного измерения, как время, часто нет смысла предварительно создавать все разделы. Например, если объемы данных изменяются, таблица, секционированная с постоянным интервалом времени, внезапно потребует, чтобы каждая секция содержала больше данных, что может привести к превышению размера секций. Наш пример выше охватывает только первую неделю; разделы для других периодов времени нужно будет создавать вручную по мере необходимости. Кроме того, неупорядоченные данные, которые выходят за пределы временных диапазонов, охватываемых текущими разделами, просто не удаются при вставке, в то время как TimescaleDB автоматически создает фрагменты независимо от того, в какое время они попадают.
Простота использования - не единственная область, в которой декларативное секционирование PG10 не подходит для рабочих нагрузок временных рядов. Разберем и сравним подходы к разделению более подробно.
Многомерное разбиение
Примеры PG10 и TimescaleDB, приведенные выше, разделяют данные в нескольких измерениях, что часто желательно для увеличения пропускной способности (например, для хранения каждого раздела пространства на другом диске) или для целей локализации данных (например, для обеспечения всех измерений для конкретного этажа в здании заканчивается вверх в том же разделе пространства).
Давайте посмотрим, как разбивается каждый пример.
Разметка PostgreSQL 10
Вариант 1: пространственно-временное разбиение
В нашем примере декларативного разбиения PG10 мы создали дерево таблиц с таблицей условий в качестве корня, а затем с четырьмя устройствами. таблицы на следующем подуровне, а затем произвольное количество временных таблиц на третьем подуровне. На рисунке ниже показано концептуальное представление многомерного разделения таблицы.
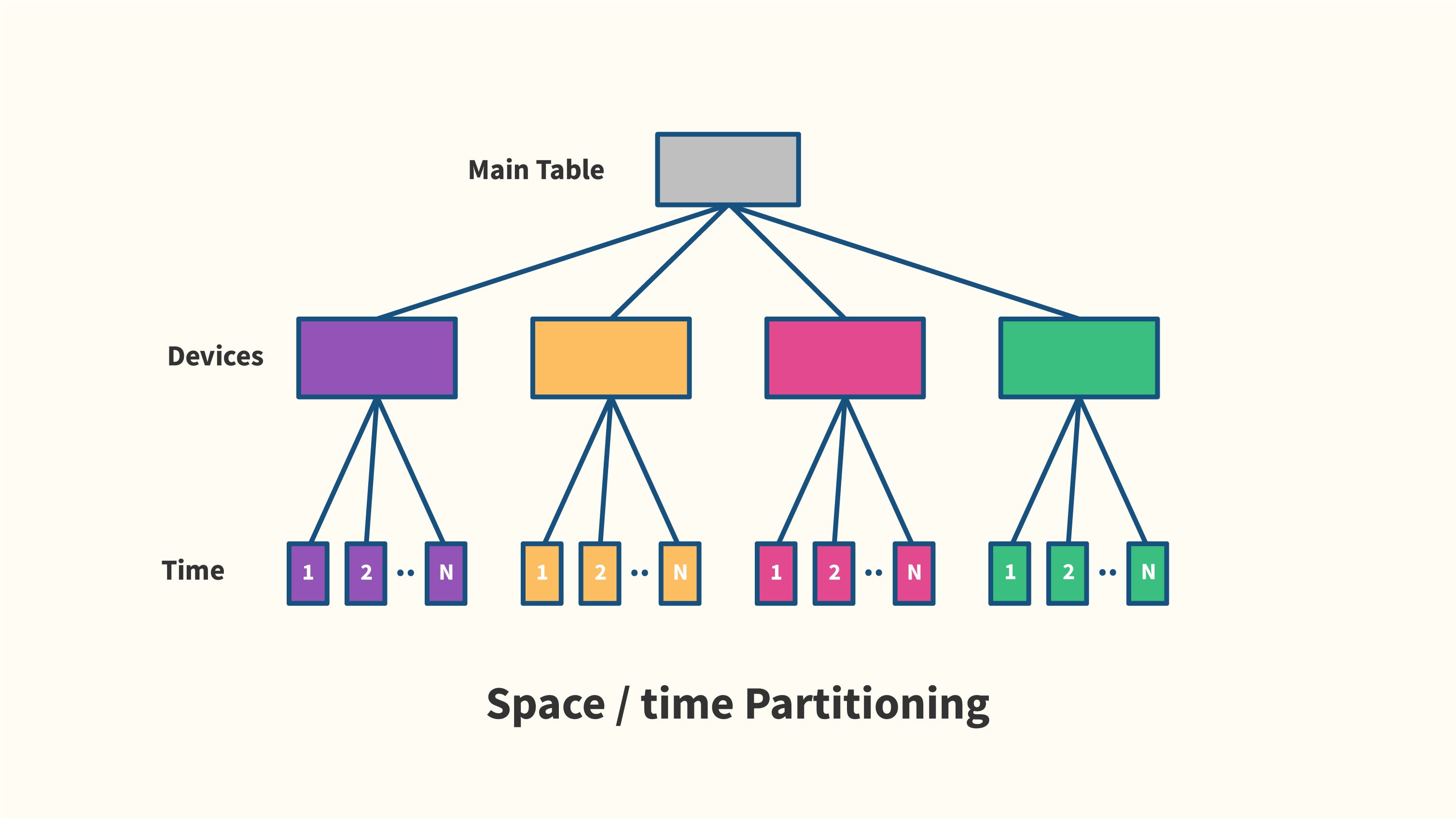
Каждый подуровень в дереве соответствует набору таблиц с ограничением CHECK, которое наследуется дочерними таблицами, так что конечные разделы имеют одно ограничение CHECK для каждого измерения разделения. Ограничения CHECK гарантируют целостность данных для определенного раздела и позволяют планировщику выполнять исключение ограничений для оптимизации запросов. Обратите внимание, что только листовые таблицы содержат фактические данные.
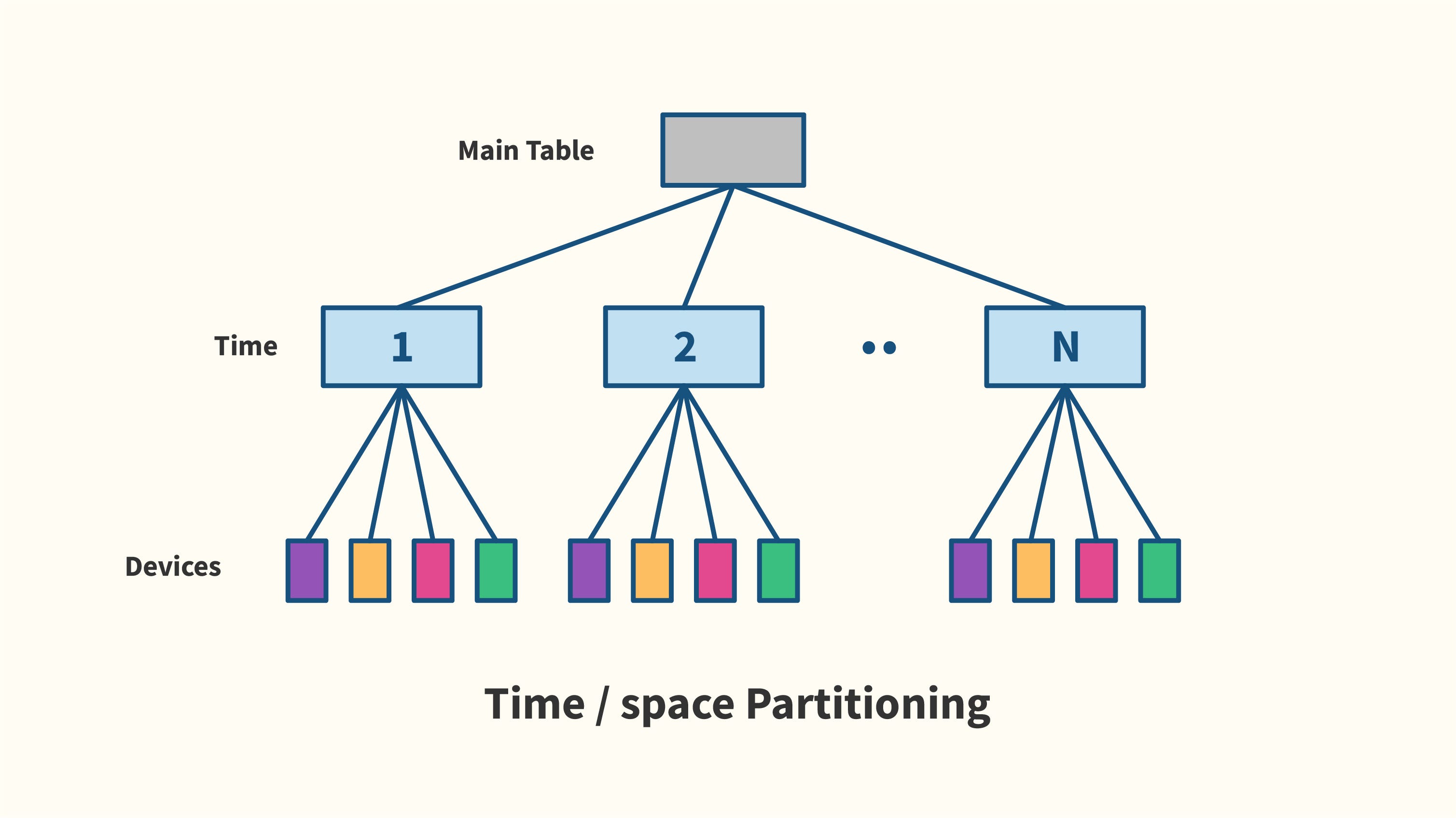
Вариант 2: разделение времени / пространства
Кто-то, возможно, уже заметил, что мы могли бы спроектировать это по-другому, вместо этого поместив время на первый подуровень и устройство на второй подуровень. как показано ниже. Хотя это еще один вариант, он также создает проблемы, как мы увидим.
Оценка обоих параметров PG10
Выбор способа упорядочивания измерений в дереве влияет на количество таблиц, которые необходимо создать для расширения измерения времени новыми таблицами (а также для повторного разбиения и отбрасывая данные, как мы покажем позже в этом посте).
Помещение измерения устройства на первый подуровень, как и в первом варианте, требует создания четырех новых таблиц каждый временной интервал (по одной для каждого измерения пространства). Во втором варианте нам нужно будет создать пять таблиц (одну для нового временного интервала и четыре пространственных подраздела). Дополнительные измерения еще больше усложнят возможные стратегии разделения и потребуют излишне больших деревьев наследования с дополнительными подуровнями.
Все эти дополнительные таблицы могут отрицательно повлиять на производительность и масштабируемость, поскольку необходимо обрабатывать больше таблиц как для вставок, так и для запросов (подробнее см. Ниже с графиками измерений).
TimescaleDB: разделение времени + пространства
TimescaleDB также полагается на наследование таблиц, но избегает глубоко вложенных многоуровневых деревьев наследования. Вместо этого он создает неглубокое дерево из кусочков листьев непосредственно в корне, независимо от количества измерений разделения, как показано ниже.
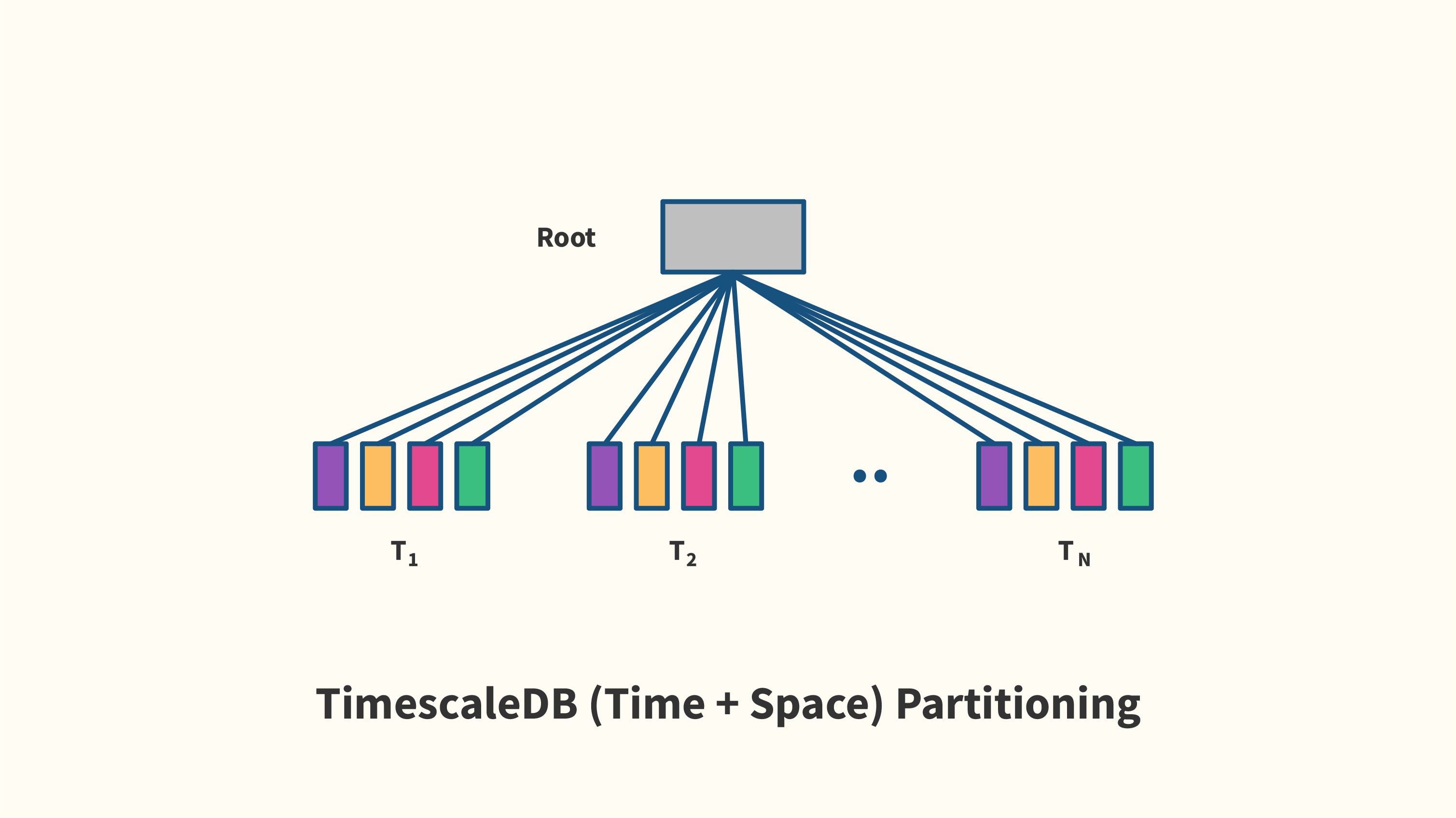
Каждый блок имеет одно CHECK ограничение на измерение и создается только при необходимости.
Это важно, поскольку сокращает количество таблиц в дереве и позволяет избежать вложенности. Таким образом, TimescaleDB повышает производительность вставки и запросов, упрощает повторное разбиение на разделы и упрощает управление (и хранение) таблиц.
В оставшейся части этого поста каждая из этих областей рассматривается более подробно.
Производительность вставки: PG10 страдает при увеличении количества разделов
Важным требованием к рабочим нагрузкам данных временных рядов является быстрая и стабильная производительность вставки. Многомерное разбиение является ключом к достижению такой производительности.
Многомерное разбиение позволяет обрабатывать входящие данные по частям более управляемыми блоками нужного размера. В TimescaleDB он позволяет базе данных достигать довольно согласованной скорости записи, независимо от размера и объема данных. Этому способствует тот факт, что данные временного ряда в основном предназначены только для добавления, что позволяет записывать в самые последние фрагменты и индексы, которые можно хранить в памяти в «теплом» состоянии. Для этой цели TimescaleDB имеет оптимизированный путь вставки, который направляет кортежи (значения данных) в нужные фрагменты во время вставки.
Декларативное разделение в PG10 также делает большой шаг вперед в этом отношении, реализуя собственную маршрутизацию кортежей. Однако наш обзор кода показывает, что один оператор INSERT всегда открывает все листовые таблицы во время вставки, включая любые индексы. Для рабочих нагрузок с большими данными с тысячами подтаблиц это доказывает проблему масштабируемости, поскольку каждую из этих таблиц (включая все индексы) необходимо обрабатывать и открывать. И тысячи подтаблиц не редкость для данных временных рядов. Например, один из наших клиентов разделяет время на пятиминутные интервалы для обработки своих уникальных скоростей передачи данных, в результате чего всего за несколько дней получается более 50 000 блоков.
Вставить графики измерения производительности
Чтобы подтвердить наши подозрения, мы запустили несколько рабочих нагрузок временных рядов через PostgreSQL 10 с настройкой разделения из нашего предыдущего примера. Мы варьировали количество секций, чтобы увидеть влияние на производительность вставки с размерами пакета из 1 строки (кортежа) и 1000 строк (кортежей) на оператор INSERT.
Результаты можно увидеть ниже.


Очевидно, что производительность вставки с использованием декларативного разбиения PG10 страдает по мере увеличения количества разделов, в то время как TimescaleDB поддерживает довольно постоянную скорость.
Но производительность вставки - не единственная проблема. Перед запуском каждого теста нам также нужно было предварительно создать все наши разделы в PostgreSQL 10, поскольку он не создает разделы для пользователя автоматически. Простое создание разделов в начале теста заняло несколько минут, и нам пришлось значительно увеличить max_locks_per_transaction, поскольку PG10 должен получить блокировки для всех разделов, даже во время вставки только одного кортежа.
Напротив, TimescaleDB создает новый фрагмент только тогда, когда кортеж выходит за границы существующих фрагментов. Кроме того, он сохраняет только ограниченное количество открытых фрагментов на INSERT, закрывая и открывая фрагменты по мере необходимости, чтобы уменьшить состояние в памяти и количество блокировок, поддерживаемых во время вставок. Таким образом, TimescaleDB не страдает от снижения скорости вставки при увеличении количества блоков. И, в основном, при добавлении рабочих нагрузок и запросах к недавним временным интервалам, только несколько фрагментов обычно должны быть открыты в памяти одновременно.
В случае, если объемы данных меняются со временем, в TimescaleDB можно легко изменить размер фрагмента, просто установив другой интервал разделения для измерения времени; новые блоки будут созданы с этим обновленным интервалом. Хотя сейчас это ручной процесс, он включает в себя изменение только одного параметра для настройки размера блока. Кроме того, в настоящее время мы разрабатываем функцию автонастройки, которая автоматически адаптирует интервал измерения времени для достижения заданного целевого размера блока при изменении скорости передачи данных и объемов.
Производительность запроса
Хотя производительность вставки имеет первостепенное значение для данных временных рядов, производительность запросов также важна, потому что вам также необходимо эффективно анализировать все вставленные данные. В этой области PG10 выиграет от дополнительной работы.
Например, TimescaleDB включает ряд функций, ориентированных на время и оптимизацию запросов, недоступных в обычном PostgreSQL, которые упрощают и повышают эффективность работы с данными временных рядов.
Эти оптимизации включают, но не ограничиваются:
- Оптимизация планировщика, позволяющая повторно использовать существующие временные индексы в группе по запросам. Без этой оптимизации эти запросы должны были бы использовать полное сканирование таблицы. В качестве альтернативы можно указать индекс выражения для каждой временной группировки (поминутно, ежечасно, ежедневно), используемой в таком запросе, но это сильно повлияет на производительность записи.
- Модификация выполнения запроса, которая может исключать фрагменты, даже если они содержат непостоянные выражения, которые обычно превращаются в сканирование всех подтаблиц в обычном PostgreSQL. Например,
SELECT * FROM conditions WHERE time > now() - interval ‘1 day’;будет полным сканированием всех данных в обычном PostgreSQL, тогда как TimescaleDB будет сканировать только те фрагменты, которые имеют данные для данного временного интервала. - Функция
time_bucket()для группировки данных по времени. По сути, это более гибкая версияdate_trunc(), которая добавляет возможность группировки, например, по 15 минутам вместо простого усечения значения времени с точностью до полных недель, дней, часов и т. Д. - Функция
histogram(), которая дает представление о распределении данных при группировке по времени, а не, например, дает только простые средние значения.
По мере развития TimescaleDB список функций запросов, ориентированных на время, будет расширяться, и мы внимательно прислушиваемся к бесценным отзывам, которые дают нам наши клиенты и сообщество.
Связано с производительностью: диапазон или хеш-секционирование
Другая ключевая область, в которой отсутствует декларативное разделение, связана с тем, как значения распределяются по разделам. Декларативное разбиение PG10 поддерживает только разбиение по диапазону и разбиение по списку. С другой стороны, TimescaleDB допускает секционирование хэша, что упрощает секционирование за счет лучшего распределения всего диапазона значений по секциям.
Используя декларативное разбиение, можно распределить набор значений с высокой мощностью, используя разбиение по диапазону. Однако разбиение по диапазонам может быть непросто, потому что разделы (1) должны охватывать все возможные значения, а (2) в идеале должны быть равномерно распределены по разделам.
В нашем примере вставка данных с использованием разделения по диапазонам с устройствами с именами sensorX или Xsensor (где X - число) приведет к тому, что все данные окажутся в одном разделе. Даже использование целочисленного поля для разделения диапазона (например, с использованием инкрементного идентификатора) может быть проблематичным, поскольку это приводит к тому, что разделы заполняются один за другим по мере увеличения идентификатора.
Чтобы избежать такого неравномерного распределения без хеш-секционирования, потребуется более тщательно спроектированная и более детальная конфигурация секционирования по диапазонам. Это в основном относит разделение диапазона к полям, которые более случайны по своей природе, например, UUID, или приложениям, где локальность данных более важна, чем равномерное распределение данных.
Легкость переразметки
При многомерном разбиении можно не только изменить интервал временного измерения, но также и пространственное измерение.
Представьте, что мы хотим перераспределить измерение устройства так, чтобы оно охватывало восемь разделов вместо четырех. (Например, если мы сопоставили каждый раздел устройства с определенным табличным пространством [диск] и теперь хотим добавить четыре новых диска.) Это было бы невозможно с декларативной схемой разделения в приведенном выше примере, потому что подтаблицы измерения времени являются дочерние к родительским таблицам устройств. Сначала нам нужно удалить все подтаблицы времени, чтобы иметь возможность перераспределить измерение устройства.
Изменение разделения на разделы таким образом, чтобы время находилось на первом уровне в дереве таблицы, могло бы помочь, но это все еще не идеально. С одной стороны, это позволило бы расширить следующий временной интервал до восьми разделов устройств, распределенных по разным табличным пространствам. Такая конфигурация может быть предпочтительнее для повторного разбиения на разделы, но она все равно увеличивает количество таблиц в дереве.
Благодаря неглубокому дереву наследования TimescaleDB позволяет избежать этих проблем, обрабатывая меньше таблиц и обеспечивая легкое перераспределение независимо от количества измерений из-за отсутствия зависимостей вложенных таблиц. Повторное разбиение можно выполнить, просто обновив конфигурацию разбиения. Система применяет любые изменения разделения только к новым данным, помогая избежать необходимости перемещать существующие данные. TimescaleDB также упрощает связывание табличных пространств с гипертаблицами, чтобы фрагменты могли автоматически распределяться по нескольким дискам.
Управление и хранение таблиц
Управление таблицами - еще один важный аспект работы с данными временных рядов (и на самом деле всеми данными) в PostgreSQL: оптимизация таблиц для запросов; обеспечение целостности данных с ограничениями, уникальными индексами, внешними ключами; расширение функциональности с помощью триггеров и управление хранением данных.
К сожалению, декларативное разбиение имеет ряд ограничений в этом отношении:
- Индексы, ограничения и триггеры не могут быть созданы в корневой таблице (за некоторыми исключениями). Эти объекты необходимо вручную создавать на каждом листовом разделе.
- Уникальные индексы и ограничения, включая первичные ключи, не поддерживаются в многораздельных таблицах. Это означает, что нельзя делать
ON CONFLICTпредложений (например, upserts). Однако уникальные индексы поддерживаются для конечных разделов, но гарантируют уникальность только для этой конкретной таблицы. - Многие команды управления, такие как
CREATE TRIGGER,ALTER TABLE,REINDEX TABLE, обычно не обращаются к субтаблицам. - Удаление старых данных может быть трудоемким, поскольку требует ручного удаления старых таблиц и схемы секционирования, которая обеспечивает согласованность данных по всем измерениям пространства. Это затрудняет реализацию политик хранения для данных временных рядов.
TimescaleDB стремится заставить гипертаблицы работать так же, как обычные таблицы, без перечисленных выше ограничений. Например, индексы, триггеры и ограничения работают должным образом, переходя в блоки при создании в гипертаблице. Гипертаблицы даже поддерживают уникальные индексы и предложения ON CONFLICT, если уникальный индекс охватывает все столбцы секционирования. Политики хранения легко реализовать с помощью команды drop_chunks(), которая безопасно удаляет все фрагменты за пределами заданного временного горизонта.
Будет ли TimescaleDB когда-либо применять декларативное разделение?
Несмотря на то, что декларативное секционирование является важной разработкой для масштабирования традиционных рабочих нагрузок, улучшения по сравнению с наследованием обычных таблиц несущественны для рабочих нагрузок с временными рядами. Декларативное создание таблиц - это приятная новая функция, но она мало что дает разницы для TimescaleDB, поскольку подтаблицы уже создаются автоматически под капотом.
Самая большая особенность декларативного разделения - это добавление маршрутизации кортежей, которую TimescaleDB уже реализует по-своему. Было бы неплохо иметь возможность использовать маршрутизацию кортежей в PostgreSQL 10, но, как указано в этом посте, есть некоторые опасения, что текущая реализация плохо масштабируется с большим количеством подтаблиц. Поэтому маловероятно, что в ближайшем будущем мы воспользуемся именно этой функцией декларативного разбиения.
Могут быть и другие причины для принятия декларативного разделения, например использование определенных оптимизаций запросов. Однако в настоящее время мы не знаем о каких-либо основных оптимизациях запросов, которые относятся к декларативному секционированию и не применяются к обычным таблицам наследования.
Заключение
В заключение скажу, что PostgreSQL 10 с декларативным секционированием - это большой шаг вперед, но это общая реализация, которая кажется более ориентированной на традиционные рабочие нагрузки среднего размера, чем на типичные данные временных рядов.
Декларативное секционирование может хорошо работать с рабочими нагрузками, которые имеют более простую схему секционирования (например, масштабирование большой таблицы клиентов путем секционирования по customerID). Он также может хорошо работать для данных с временным измерением, если объем не слишком велик и если не следует ожидать данных вне порядка (или если неудачные вставки допустимы для данных вне порядка).
Однако если вы ожидаете больших объемов данных временных рядов, вам, вероятно, понадобится что-то более производительное, обеспечивающее оптимизацию запросов с учетом времени, требующее меньше ручной работы и более удобное.
Если вы хотите узнать больше о TimescaleDB, посетите наш GitHub (всегда приветствуются звезды) и дайте нам знать, как мы можем помочь.
Понравился этот пост? Пожалуйста, порекомендуйте / поделитесь. Вопросов? Напишите нам по электронной почте или Slack.