Создание конвейера Train в Azure DevOps для AutoMLVision
Предпосылка
- Учетная запись Azure
- Хранилище Azure
- Служба машинного обучения Azure
- Azure DevOps
- Аккаунт и репозиторий Github
- Учетная запись участника службы Azure
- Предоставление участникам-участникам доступа к ресурсу машинного обучения
- Azure Keyvault для хранения секретов
- Обновите хранилище ключей с помощью секретов субъекта-службы.
- Скрипты поезда рассчитаны на 3 параметра
- Идентификатор арендатора
- Идентификатор клиента субъекта-службы
- Секрет субъекта-службы
- Приведенные выше сведения будут переданы из Azure DevOps в виде секретных переменных.
- Это автоматизирует обучающий код и регистрирует модель.
Шаги
- Создать сценарий поезда
- Создание сценариев зависимостей агента
- Создание конвейера Azure DevOps
Сценарий поезда
- Откройте код Visual Studio
- Создайте новый проект с именем visionautoml.
- Создайте новый каталог с именем train
- Создайте новый файл Python с именем train.py.
- Обучить сценарий для проверки подлинности с использованием субъекта-службы, чтобы он мог выполняться в автоматическом режиме.
- Замените идентификатор подписки, имя группы ресурсов и имя рабочей области для запуска.
- DevOps передает запуск эксперимента службам машинного обучения Azure.
- DevOps будет вести мониторинг и выводить журналы
import azureml.core
from azureml.core import Workspace
from azureml.core import Keyvault
import os
from azureml.core import Workspace, Experiment
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling
from azureml.train.hyperdrive import choice
from azureml.contrib.dataset.labeled_dataset import _LabeledDatasetFactory, LabeledDatasetTask
from azureml.core import Dataset
from azureml.core.authentication import ServicePrincipalAuthentication
from azureml.core.compute import AmlCompute, ComputeTarget
from azureml.core import Experiment
from azureml.core import Workspace
import os
import urllib
from zipfile import ZipFile
print("SDK version:", azureml.core.VERSION)
import argparse
parse = argparse.ArgumentParser()
parse.add_argument("--tenantid")
parse.add_argument("--clientid")
parse.add_argument("--secret")
args = parse.parse_args()
sp = ServicePrincipalAuthentication(tenant_id=args.tenantid, # tenantID
service_principal_id=args.clientid, # clientId
service_principal_password=args.secret) # clientSecret
ws = Workspace.get(name="workspacename",
auth=sp,
subscription_id="xxxxxxxxxxxxxxxxxxxxxxx", resource_group="resourcegroupname")
#ws = Workspace.from_config()
keyvault = ws.get_default_keyvault()
tenantid = keyvault.get_secret(name="tenantid")
acclientid = keyvault.get_secret(name="acclientid")
accsvcname = keyvault.get_secret(name="accsvcname")
accsecret = keyvault.get_secret(name="accsecret")
print(accsvcname)
sp = ServicePrincipalAuthentication(tenant_id=tenantid, # tenantID
service_principal_id=acclientid, # clientId
service_principal_password=accsecret) # clientSecret
ws = Workspace.get(name="gputraining",
auth=sp,
subscription_id="c46a9435-c957-4e6c-a0f4-b9a597984773", resource_group="mlops")
ws.get_details()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
cluster_name = "gpu-cluster"
try:
compute_target = ws.compute_targets[cluster_name]
print('Found existing compute target.')
except KeyError:
print('Creating a new compute target...')
compute_config = AmlCompute.provisioning_configuration(vm_size='Standard_NC6',
idle_seconds_before_scaledown=1800,
min_nodes=0,
max_nodes=4)
compute_target = ComputeTarget.create(ws, cluster_name, compute_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min_node_count is provided, it will use the scale settings for the cluster.
compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
experiment_name = 'automl-image-notebook'
experiment = Experiment(ws, name=experiment_name)
# download data
download_url = 'https://cvbp-secondary.z19.web.core.windows.net/datasets/object_detection/odFridgeObjects.zip'
data_file = './odFridgeObjects.zip'
urllib.request.urlretrieve(download_url, filename=data_file)
# extract files
with ZipFile(data_file, 'r') as zip:
print('extracting files...')
zip.extractall()
print('done')
# delete zip file
os.remove(data_file)
from IPython.display import Image
Image(filename='./odFridgeObjects/images/31.jpg')
import json
import os
import xml.etree.ElementTree as ET
src = "./odFridgeObjects/"
train_validation_ratio = 5
# Retrieving default datastore that got automatically created when we setup a workspace
workspaceblobstore = ws.get_default_datastore().name
# Path to the annotations
annotations_folder = os.path.join(src, "annotations")
# Path to the training and validation files
train_annotations_file = os.path.join(src, "train_annotations.jsonl")
validation_annotations_file = os.path.join(src, "validation_annotations.jsonl")
# sample json line dictionary
json_line_sample = \
{
"image_url": "AmlDatastore://" + workspaceblobstore + "/"
+ os.path.basename(os.path.dirname(src)) + "/" + "images",
"image_details": {"format": None, "width": None, "height": None},
"label": []
}
# Read each annotation and convert it to jsonl line
with open(train_annotations_file, 'w') as train_f:
with open(validation_annotations_file, 'w') as validation_f:
for i, filename in enumerate(os.listdir(annotations_folder)):
if filename.endswith(".xml"):
print("Parsing " + os.path.join(src, filename))
root = ET.parse(os.path.join(annotations_folder, filename)).getroot()
width = int(root.find('size/width').text)
height = int(root.find('size/height').text)
labels = []
for object in root.findall('object'):
name = object.find('name').text
xmin = object.find('bndbox/xmin').text
ymin = object.find('bndbox/ymin').text
xmax = object.find('bndbox/xmax').text
ymax = object.find('bndbox/ymax').text
isCrowd = int(object.find('difficult').text)
labels.append({"label": name,
"topX": float(xmin)/width,
"topY": float(ymin)/height,
"bottomX": float(xmax)/width,
"bottomY": float(ymax)/height,
"isCrowd": isCrowd})
# build the jsonl file
image_filename = root.find("filename").text
_, file_extension = os.path.splitext(image_filename)
json_line = dict(json_line_sample)
json_line["image_url"] = json_line["image_url"] + "/" + image_filename
json_line["image_details"]["format"] = file_extension[1:]
json_line["image_details"]["width"] = width
json_line["image_details"]["height"] = height
json_line["label"] = labels
if i % train_validation_ratio == 0:
# validation annotation
validation_f.write(json.dumps(json_line) + "\n")
else:
# train annotation
train_f.write(json.dumps(json_line) + "\n")
else:
print("Skipping unknown file: {}".format(filename))
ds = ws.get_default_datastore()
ds.upload(src_dir='./odFridgeObjects', target_path='odFridgeObjects')
training_dataset_name = 'odFridgeObjectsTrainingDataset'
if training_dataset_name in ws.datasets:
training_dataset = ws.datasets.get(training_dataset_name)
print('Found the training dataset', training_dataset_name)
else:
# create training dataset
training_dataset = _LabeledDatasetFactory.from_json_lines(
task=LabeledDatasetTask.OBJECT_DETECTION, path=ds.path('odFridgeObjects/train_annotations.jsonl'))
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
# create validation dataset
validation_dataset_name = "odFridgeObjectsValidationDataset"
if validation_dataset_name in ws.datasets:
validation_dataset = ws.datasets.get(validation_dataset_name)
print('Found the validation dataset', validation_dataset_name)
else:
validation_dataset = _LabeledDatasetFactory.from_json_lines(
task=LabeledDatasetTask.OBJECT_DETECTION, path=ds.path('odFridgeObjects/validation_annotations.jsonl'))
validation_dataset = validation_dataset.register(workspace=ws, name=validation_dataset_name)
print("Training dataset name: " + training_dataset.name)
print("Validation dataset name: " + validation_dataset.name)
training_dataset.to_pandas_dataframe()
image_config_yolov5 = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}))
automl_image_run = experiment.submit(image_config_yolov5)
automl_image_run.wait_for_completion(wait_post_processing=True)Создание файлов зависимостей агента
- Создайте новые файлы оболочки
- Устанавливаем все необходимое для Azure ML SDK
python --version
pip install azure-cli==2.0.72
pip install --upgrade azureml-sdk
pip install azureml-sdk[notebooks]
pip install --upgrade azureml-sdk[cli]
pip install argparse
pip install tensorflow==2.0.0
pip install --upgrade "azureml-train-core<0.1.1" "azureml-train-automl<0.1.1" "azureml-contrib-dataset<0.1.1" --extra-index-url "https://azuremlsdktestpypi.azureedge.net/automl_for_images_private_preview/"- Храните оба из них в github, чтобы код можно было поддерживать для версий.
Azure DevOps
- Войдите в Azure DevOps
- Создать новый проект
- Выберите Github в качестве репозитория
- Выберите проект или репозиторий, который был создан
- Перейдите в Pipeline и создайте новый конвейер
- Я выбираю классический редактор
- Создать пустую работу
- Настроить ОС агента
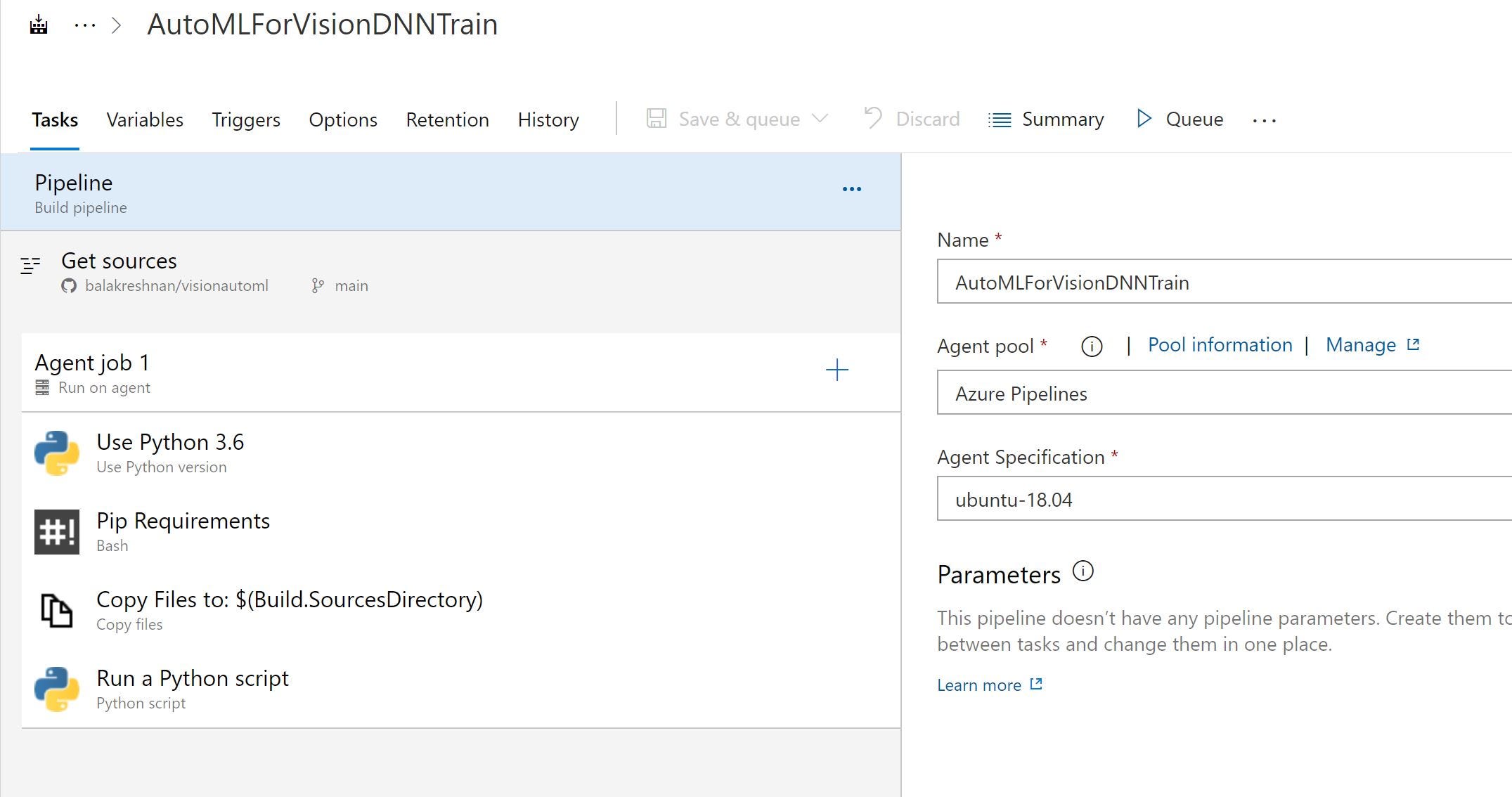
- Выберите версию Python

- Установить пакеты агента python

- Скопируйте артефакт агенту для отправки
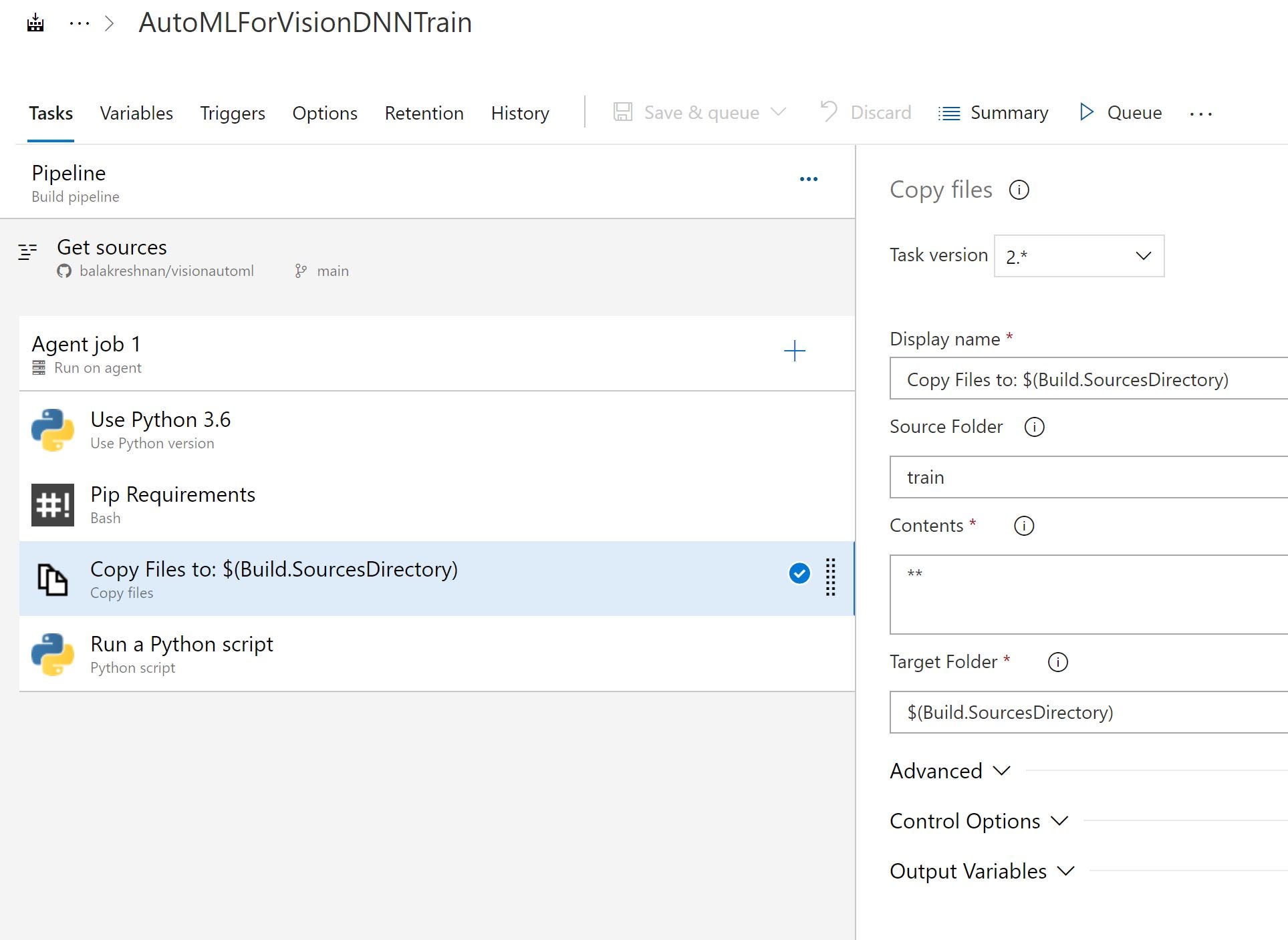
- Перетащите скрипт Python и запустите файл train.py.

--tenantid $(tenatid) --acclientid $(acclientid) --accsecret $(accsecret)- Создайте переменные для передачи
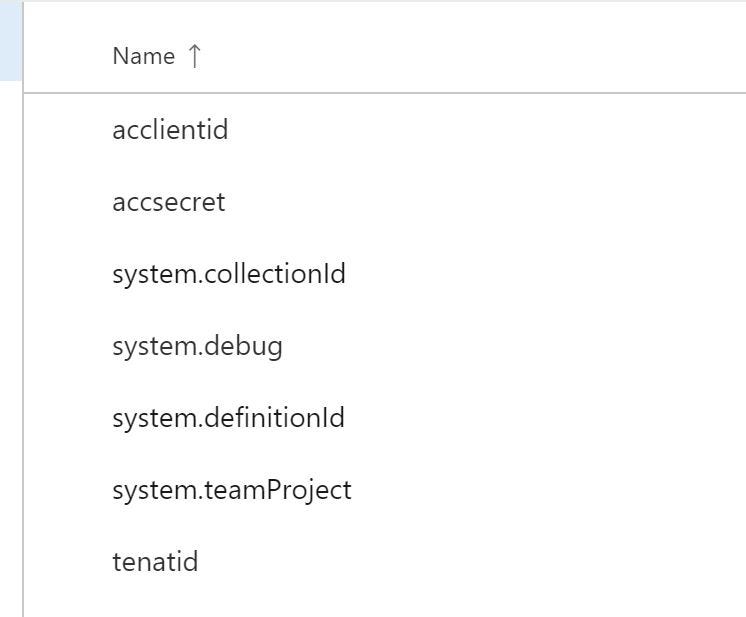
- Запустите конвейер и дождитесь его завершения
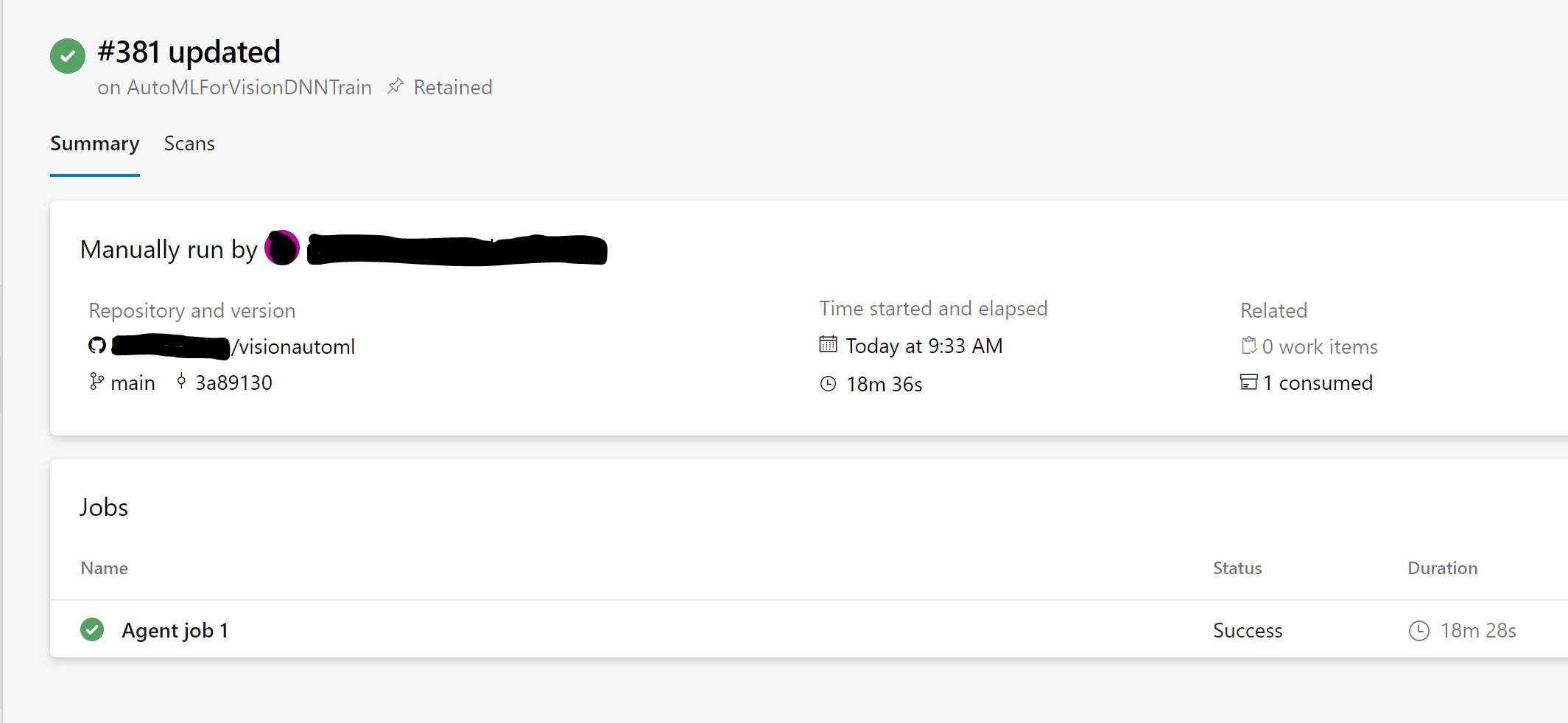
- Войдите в рабочую область Azure ML и перейдите к экспериментам, чтобы просмотреть сведения об экспериментах.
оригинал статьи на Samples2021/automltraindevops.md на главной · balakreshnan/Samples2021 (github.com)