Что такое MLOps?
MLOps - это новая и зарождающаяся область в мире науки о данных. NVIDIA определяет MLOps как набор передовых методов, позволяющих предприятиям успешно использовать ИИ. Это также относительно новая область, потому что коммерческое использование ИИ само по себе довольно ново. Поскольку MLOps может охватывать несколько процессов жизненного цикла проекта машинного обучения, в этой статье основное внимание будет уделено только части MLOps, связанной с данными, а именно проблемам шума этикеток и нехватки качественных данных.
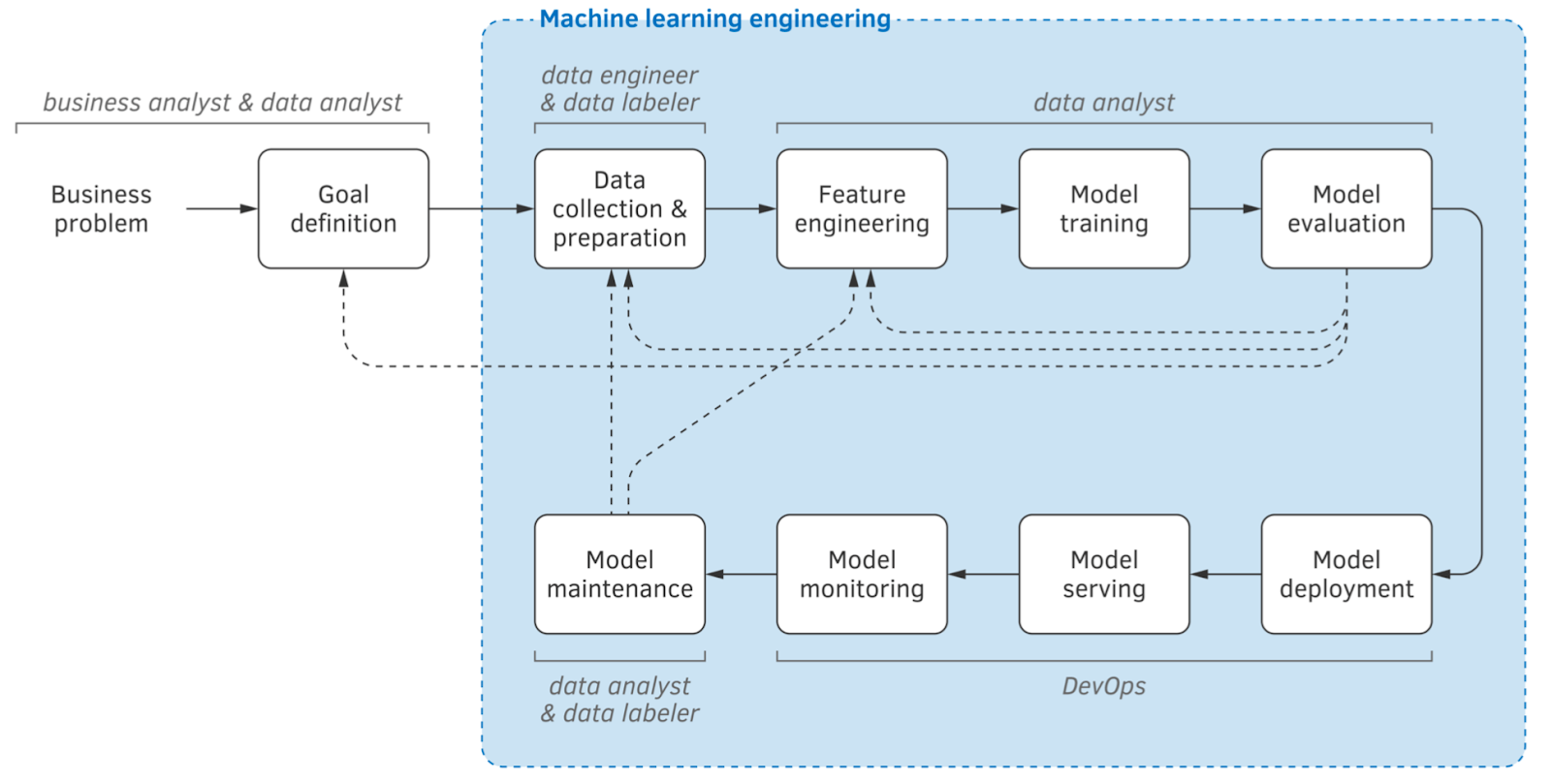
Я также буду опираться на доклад Эндрю Нг под названием MLOps: From Model-Centric to Data-Centric AI и книгу Андрея Буркова «Машинное обучение». Я настоятельно рекомендую вам оба этих ресурса, потому что они фантастические!
Что считается хорошими данными?

Эндрю Нг определяет данные хорошего качества как определяемые в соответствии с недвусмысленным определением ярлыка. Хорошие данные также должны охватывать важные случаи с хорошим охватом входных функций. Хорошие данные также должны иметь своевременную обратную связь с производственными данными, чтобы гарантировать, что они охватывают дрейф данных и дрейф концепций.
Этикетка согласованности
Данные необходимы для разработки моделей машинного обучения. Однако, как гласит известная пословица, «мусор на входе - мусор на выходе». Данные низкого качества и их метки могут привести к снижению производительности модели. Эта проблема часто усугубляется, если набор данных невелик или если есть определенные наблюдения или классы, которые составляют меньшинство.
Плохо маркированные данные также могут затруднить оценку моделей и анализ ошибок. Мы не можем доверять нашим оценочным показателям, если нельзя доверять самим лейблам. Эта проблема усугубляется, если данные трудно понять и интерпретировать, для того, какие эксперты в предметной области необходимы для правильного определения названия каждого наблюдения.

Например, наша команда занимается юридическими контрактами между SAP и ее клиентами. Эти контракты часто бывают очень длинными, некоторые из них содержат более 50 страниц, и наша задача состоит в классификации этих документов на основе определенных критериев. Однако для нас сложнее и труднее иметь дело с данными, которые могли быть неправильно маркированы, поскольку для маркировки наблюдения необходимо знание предметной области.

Шум на этикетке может возникать не только из-за задачи классификации. В своем выступлении Эндрю Нг привел пример несовместимой аннотации ограничивающего прямоугольника для обнаружения объектов. Он предположил, что это может быть связано с разными методологиями маркировки между этикетировщиками или даже с тем, как этикетировщик может по-разному маркировать наблюдения с течением времени.
Как мы можем улучшить единообразие этикеток?
Во-первых, Эндрю Нг предлагает иметь четкие и конкретные инструкции по маркировке. Он также предлагает, чтобы два независимых специалиста по маркировке маркировали выборку наблюдений. Если они не согласны с определенным типом наблюдения или набором классов, инструкции по маркировке могут быть пересмотрены, пока они не станут более ясными.
Андрей Бурков также подсказывает, как разные этикетировщики могут предоставлять этикетки разного качества, поэтому важно отслеживать, кто создал какой из этикеток. Поэтому управление версиями данных очень важно. Кроме того, он предлагает попросить нескольких человек наклеить ярлыки для одного и того же учебного примера. В некоторых ситуациях команда может принять этот ярлык только в том случае, если все люди присвоили один и тот же ярлык этому примеру. В менее сложных ситуациях команда может принять ярлык, если его присвоило большинство людей.
Ориентация на модель VS ориентированная на данные
В своем выступлении о MLOps Эндрю Нг подчеркнул различия между подходом, ориентированным на модель, и подходом, ориентированным на данные. В своем определении подхода, ориентированного на модель, группа специалистов по науке о данных собирает доступные данные, фиксирует их и улучшает код. Улучшение кода может включать использование различных моделей, разных гиперпараметров и т. Д. И наоборот, ориентированный на данные подход сохраняет код фиксированным и итеративно пытается улучшить качество данных.
Несмотря на то, что большинство людей согласны с тем, что данные являются ключевыми, большая часть исследований и шумихи вокруг ИИ часто связана с новейшими алгоритмами и технологиями. Эндрю Нг провел неформальный обзор последних статей, опубликованных на ArXiv, и обнаружил, что около 99% статей были посвящены алгоритмам машинного обучения, и только одна была посвящена увеличению данных. Большинство курсов, которые я посещал, будь то в школе или онлайн, как правило, были сосредоточены на алгоритмах, с небольшим акцентом на аспекте данных.

Эндрю Нг утверждает, что подход, ориентированный на данные, приводит к более быстрому и лучшему повышению производительности модели. Он поделился примером модели, обнаруживающей стальные листы на предмет дефектов, и прокомментировал, как ориентированный на модель акцент на коде не привел к увеличению производительности модели, но ориентированный на данные подход к повышению качества данных повысил производительность модели с 76,2% до 93,1 %.
Это отражает мой опыт разработки моделей машинного обучения в моей текущей работе и в прошлой работе с компаниями. Работа с проблемами данных, такими как смещение распределения, шум этикеток, качество данных и анализ ошибок, как правило, давали гораздо лучшие результаты по сравнению с слепой тратой часов на настройку гиперпараметров или опробованием все более сложных моделей. Для меня очень важно выяснить, какие данные ошибочно предсказывались и почему.
В том же ключе Эндрю Нг утверждает, что современные архитектуры нейронных сетей довольно сложны и являются моделями с низким смещением. Таким образом, необходимо решить проблемы дисперсии, и один из эффективных способов их решения - повысить качество данных. Он считает, что как только данные будут достаточно хорошими, появится множество моделей, которые могут хорошо работать.
Небольшие наборы данных и шум этикеток

Эндрю Нг упоминает, что небольшой размер набора данных, как правило, обостряет проблему шума этикеток. Обзор наборов данных Kaggle его коллегой и вопрос, который он задал своей аудитории во время выступления, показали, что во многих случаях наборы данных имеют небольшой или средний размер.
Однако даже в случае больших данных, таких как поисковые запросы или видеоматериалы для беспилотных автомобилей, все еще может существовать проблема «длинного хвоста», когда наблюдение появляется редко. Например, крайне редкий поисковый запрос или очень уникальная дорожная ситуация.

Затем Эндрю рассмотрел пример воздействия шума этикеток на небольшие данные. Как видно из изображения, модель, подходящая для небольших данных, но шумных меток, как правило, плохо работает, тогда как с большими данными модель все еще может хорошо соответствовать, несмотря на зашумленные метки. Однако наиболее важным моментом, который пытался поднять Эндрю, было то, что небольшие данные с чистыми и согласованными метками уже достаточно хороши.
Очистка данных VS сбор дополнительных данных
С шумными этикетками Эндрю Нг предлагает либо собрать больше данных, либо очистить существующие данные. Он предлагает сценарий, при котором, если у вас есть 500 примеров, а 12% из них являются шумными, устранение шума или сбор еще 500 новых примеров примерно одинаково эффективны.

Эндрю также представляет здесь другой сценарий графически. Чтобы достичь того же уровня производительности с чистым набором данных, вам потребуется почти утроить объем обучающих данных. Следовательно, в зависимости от стоимости очистки необходимо оценивать больше данных.
Один из способов очистки этикеток - более автоматизированный способ обнаружения ошибочно маркированных примеров. Андрей Бурков предлагает применить модель к обучающим данным, на основе которых она была построена, и проанализировать примеры, для которых она сделала другой прогноз по сравнению с метками, предоставленными людьми. Другой метод - изучить прогнозы с оценкой, близкой к порогу принятия решения.

Если команда решила пометить новые данные, Бурков предлагает рассмотреть еще один интересный подход. Он предлагает использовать лучшую модель для оценки непомеченных примеров и пометить те примеры, оценка прогноза которых близка к порогу предсказания. И наоборот, если анализ ошибок выявил паттерны ошибок посредством визуализации, то можно было бы сосредоточить внимание на таких примерах.
Анализ систематических ошибок
Эндрю предлагает следующий системный подход к улучшению данных. Сначала обучите модель, выполните анализ ошибок, чтобы определить типы данных, с которыми алгоритм работает плохо. Затем получите больше таких данных с помощью увеличения данных, генерации данных, сбора данных или изменения меток, если необходимо.
Я считаю, что этот метод также можно объединить с более систематической формой анализа ошибок, предложенной Андреем Бурковым. Он предполагает, что ошибки могут быть единообразными, появляться с одинаковой частотой во всех вариантах использования, или сфокусированными и чаще появляться в определенных типах вариантов использования.
Я по словам Андрея Буркова: «Сфокусированные ошибки по определенной схеме - это те, которые заслуживают особого внимания. Исправляя шаблон ошибки, вы исправляете его один раз для многих примеров. Сфокусированные ошибки или тенденции к ошибкам обычно возникают, когда некоторые варианты использования недостаточно хорошо представлены в обучающих данных ... Это можно сделать путем кластеризации тестовых примеров и тестирования модели на примерах из разных кластеров ».

Бурков предлагает использовать инструменты уменьшения размерности, такие как UMAP или автоэнкодер, чтобы уменьшить размерность данных до 2D, а затем визуально проверить распределение ошибок. Затем мы можем использовать разные цвета или формы для представления точек, принадлежащих разным классам, независимо от того, правильно ли модель предсказала наблюдение или нет. Затем мы можем сосредоточиться на регионах, которые постоянно ошибочно предсказываются. Он предлагает рассматривать 100–300 примеров за раз, а затем итеративно улучшать модель.