Как мы заняли третье место в ActivityNet Challenge в 2017 году.

Недавно мы заняли третье место в категории распознавания усеченных действий в ActivityNet Challenge, проводившемся в качестве семинара на CVPR 2017. Набор данных для этой категории, Kinetics, был выпущен Google DeepMind. Задача состоит в том, чтобы распознать действия в обрезанных видеопоследовательностях, где каждое видео содержит одно действие (метку) длительностью не более 10 секунд. Всего около 300 000 видео по 400 классам действий, созданных на YouTube.
В документе, опубликованном DeepMind в рамках выпуска набора данных Kinetics, базовая точность составляет 61,0% (первое место) и 81,3% (первое место 5), что было превзойдено лучшими участниками испытания со значительным отставанием. .

Как видно из таблицы лидеров, мы получили наивысшую точность в пятерке лучших среди трех заявок, что на 15,7% больше базового уровня в абсолютном выражении. В целом мы заняли третье место по среднему показателю для топ-1 и топ-5.
В этом посте мы подробно расскажем, как подать заявку. По сути, наш подход использует как аудио, так и визуальные потоки, присутствующие в видео. Мы обучили глубокие нейронные сети, которые фиксировали различные статистические модальности, присутствующие в данных, и объединили полученные прогнозы для получения окончательного результата.
Мы использовали PyTorch для всех наших материалов во время челленджа. Это отличная библиотека глубокого обучения для быстрого прототипирования, более простая, чем библиотеки статических графов, которые не позволяют вам определять, изменять и выполнять узлы на ходу.
Мы предварительно обработали видео и разбили их на кадры с 8 FPS. Затем эти кадры были объединены в определенный формат данных, который мы назвали GulpIO. Мы разработали GulpIO параллельно с нашей задачей, направленной на молниеносную передачу видеоданных между диском и памятью GPU / CPU. В ближайшее время мы планируем предоставить GulpIO с открытым исходным кодом для сообщества, и более подробная информация будет опубликована позже.
2D-CNN модели
Исходя из базовых инстинктов, мы извлекли 2048 пространственных характеристик ResNet-101 после последнего слоя объединения для каждого кадра видео. Мы объединили полученные характеристики путем их усреднения и обучили многослойный персептрон (MLP) поверх него.
Resfeat-1: мы экспериментировали с разными нелинейностями и получили:
- PReLU: 64% (топ-1),
- Максимальное количество юнитов: 65% (топ-1)
Resfeat-2: в дополнение к вышесказанному мы сгруппировали полученные функции в 25 групп с помощью RSOM [3] и обучили MLP поверх него, чтобы получить:
- PReLU: 66,2% (топ-1),
- Максимальное количество юнитов: 67,8% (топ-1)
Этот простой подход дал результаты, превосходящие исходные. Это открытие проливает свет на важность контекста, не связанного с движением, в видеороликах этого набора данных, в отличие от мгновенных временных изменений. Например, часто достаточно увидеть волны и доску для серфинга, чтобы сделать вывод, что кто-то «занимается серфингом».
3D-CNN модели
Мы также исследовали 3D-модели, которые обрабатывают видеосегменты, свертывая не только пространственное измерение, но и временное измерение. Следовательно, это позволяет сети узнавать временные закономерности в видео.
Resnet3D: вдохновившись [2], мы увеличили слои Resnet-50 во временной области, чтобы получить инициализацию ImageNet для 3D-модели CNN, и получили точность 64,30% (первое место) и 85,58% (топ-5)
Оптический поток: мы использовали OpenCV для вычисления плотного оптического потока и преобразовали двухканальные векторы оптического потока (u, v) в его величину и направлении перед сохранением их как изображений RGB для сжатия. Используя вышеупомянутую архитектуру Resnet3D на этих фреймах, мы получили точность 42,65% (первое место) и 68,09% (пятерка лучших). Эти результаты не были сопоставимы с современной моделью оптического потока, но мы не смогли исследовать этот поток дальше из-за нехватки времени во время конкурса. Однако для этого найти правильный конвейер оптического потока так же важно, как и найти оптимальную архитектуру сети.
AudioNet
Мы использовали архитектуру DeepSpeech-2 [1] для построения аудиомодели и усреднили полученные выходные данные скрытого состояния RNN, чтобы передать их через уровень FC для задачи классификации. Он с высокой степенью уверенности решил большинство специфичных для звука классов. В целом, мы получили точность проверки 17,86% (первое место) и 34,39% (первое пятерка).
BesNet
Во время испытания мы представили новую архитектуру 3D CNN, в которой используются разделяемые фильтры свертки для пространственной и временной области. Кроме того, мы добавили случайное расширение во временном измерении в качестве регуляризатора, чтобы сделать модель более устойчивой к информации, содержащейся в разных временных масштабах. Эта единственная модель показала точность 70% на вершине валидации и была нашей лучшей отдельной моделью. Подробнее в сопроводительном посте здесь.
Хард-майнинг на основе энтропии.
Мы применили хард-майнинг к обучению BesNet. С этой целью мы ждали, пока модель получит достойные результаты на проверочном наборе. Затем мы начали выбирать сложные экземпляры, определяемые высокой энтропией на основе предсказанной достоверности. Это привело к отобранным экземплярам, которые нельзя было с уверенностью классифицировать как тяжелые. Мы обучили сеть для дополнительной эпохи с этими жесткими примерами и повторили эту процедуру пару раз. Это увеличило точность топ-1 с 70% до 72% для BesNet. Хотя мы наблюдали чрезмерную подгонку при обычном жестком майнинге, энтропийный подход улучшил наши результаты без каких-либо дополнительных последствий.
Ансамбль
Все описанные модели в итоге были собраны в ансамбль:
1. Максимальное значение
Мы объединили прогнозы, полученные на основе вышеупомянутых моделей, и получили оценку 77% (первое место). Кроме того, мы получили 71% (топ-1) со средним пулом и 72% (топ-1) с большинством голосов.
2. Укладка
Мы использовали следующую процедуру:
- Обучайте модели с обычным обучением и проверкой.
- Получите значения достоверности класса для набора для проверки из каждой модели.
- Разделите набор проверки на 2 как val-1 и val-2.
- Обучите метамодель на val-1 с уверенностью первого уровня.
- Проверить потерю валидации на вал-2
Примечание. Все приведенные выше точности оцениваются при проверке достоверности данных.
Схематическая диаграмма
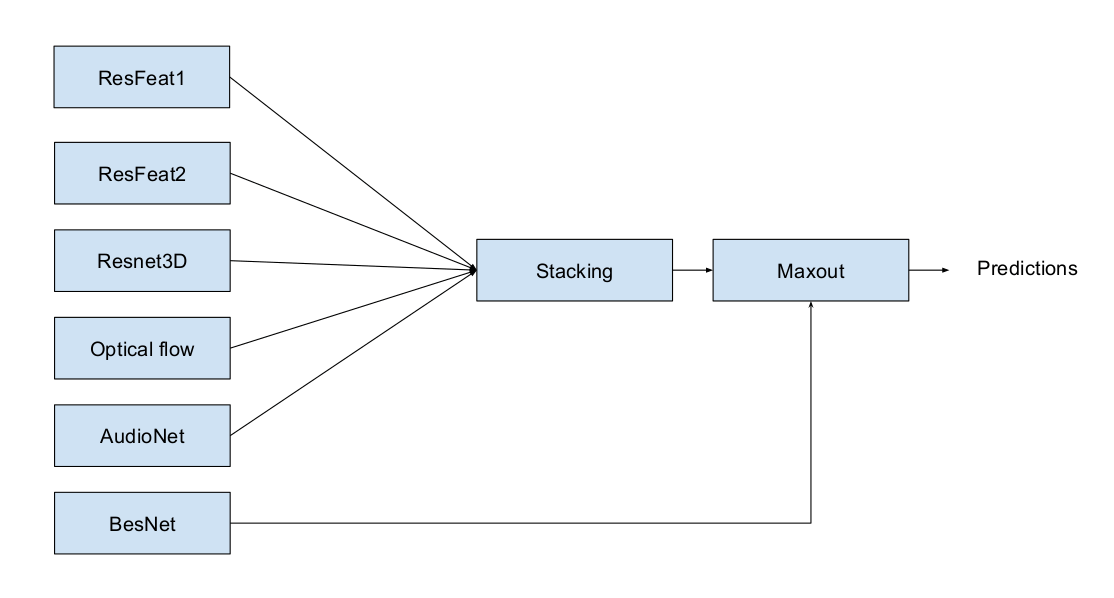
Обсуждение
В TwentyBN мы стремимся к решению проблемы понимания видео и создания систем искусственного интеллекта, которые обеспечивают человеческое визуальное понимание мира. Чтобы ускорить развитие машин, которые могут воспринимать мир как люди, мы недавно выпустили два крупномасштабных набора видеоданных (256 591 видео с ярлыками), чтобы научить машины визуальному здравому смыслу. Наборы данных были опубликованы вместе с бумагой, которая появится на ICCV 2017.
Набор данных Kinetics, один из крупнейших наборов данных по распознаванию активности, был получен и отфильтрован из видеороликов YouTube. Как и другие наборы данных, использующие видео из Интернета, Kinetics не может представить простейшие взаимодействия физических объектов, которые потребуются для моделирования визуального здравого смысла. Тем не менее, мы считаем, что наша способность получать конкурентные результаты по этому набору данных, имея ограниченное время и ресурсы, является убедительным сигналом о нашем стремлении значительно улучшить современные системы понимания видео.
Авторы Eren Golge, Raghav Goyal и Valentin Haenel
использованная литература
[1] Д. Амодеи, С. Анантанараянан, Р. Анубхай, Дж. Бай, Э. Баттенберг, К. Кейс, Дж. Каспер, Б. Катандзаро, К. Ченг, Г. Чен и др. Глубокая речь 2: Сквозное распознавание речи на английском и мандаринском языках. В ICML, 2016.
[2] Дж. Каррейра и А. Зиссерман. Quo vadis, признание действия? Новая модель и набор данных кинетики. Препринт arXiv arXiv: 1705.07750, 2017
[3] Э. Голге, П. Дуйгулу. Карта концепций: анализ зашумленных веб-данных для изучения концепций. В Европейской конференции по компьютерному зрению, страницы 439–455. Спрингер, Чам, 2014 г.