Терминология:
Основная очередь транзакций (TMQ): очередь, которая представляет собой FIFO и имеет только одного подписчика для поддержания атомарности транзакции путем последовательного доступа к сообщениям.
Поэтапное развертывание: новый код развертывается без простоев в существующем пуле, при этом старая версия также работает. Самый важный фактор, который следует учитывать в B2C, где нельзя позволить себе простои. Ожидается откат и т. д.
Издатели : запись в очередь
Подписчики: прослушивание очереди
Тип сообщения (MT): например, тот же идентификатор бронирования, тот же идентификатор кошелька, то же сообщение пользователя и т. д.
Экспериментальная система A-B: система, которая обрабатывает тестовые случаи A-B.
Пул серверов: один тип серверов с одинаковым кодом за балансировщиком нагрузки.
Разделенная очередь транзакций (TSQ): отвечает за хранение выделенных МТ.
Зеркальные TSQ: Временные очереди на временной период. Это очереди с высоким приоритетом. Сопоставление один к одному с TSQ
Постановка проблемы. Очередь растет, так как скорость потребления меньше скорости приема
Издатели пишут в очередь, для которой есть только один подписчик, чтобы транзакция не прерывалась. Время обработки, затрачиваемое подписчиком на обработку сообщения, выше, и, следовательно, размер очереди увеличивается под нагрузкой.
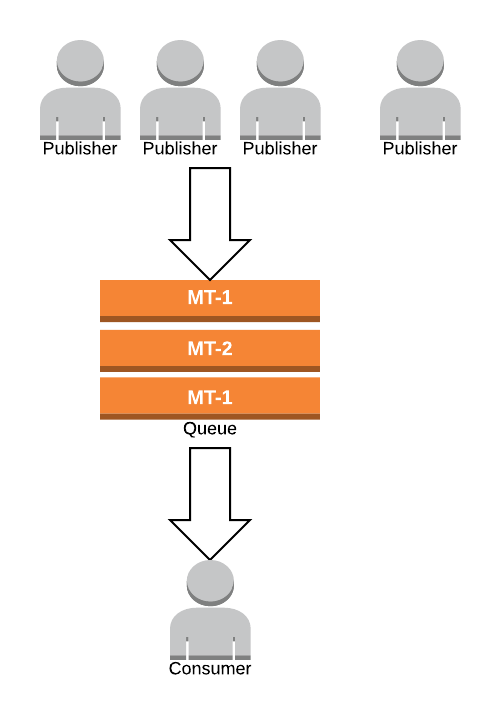
Чтобы решить эту проблему, я могу придумать несколько алгоритмов.
Алгоритм — I: (LOCK — BASED) Параллельные подписчики берут блокировку на определенный тип сообщения ( MT ), поэтому несколько сообщений одного и того же MT не должны обрабатываться в разном порядке приема.
Алгоритм — II: (LOCK — FREE) Один подписчик только для транзакционной очереди (TMQ), который разбивает сообщение на основе MT и играет роль издателя для нескольких очередей (TSQ).
Алгоритм — III: (БЛОКИРОВКА — БЕСПЛАТНО) Издатель(и) разбивает данные и отправляет их в TSQ на основе уникальных MT.
Плюсы и минусы каждого алгоритма:
Алгоритм — I : Взятие блокировки — сложная операция. Многие базы данных NoSQL создают для этой цели временный ключ для пессимистической блокировки. И в этом случае нам нужна пессимистическая блокировка, а не оптимистическая блокировка. Это задерживает операцию, а также увеличивает нагрузку на базы данных NoSQL. Некоторые NoSQL могут создать блокировку, атомарно пометив сообщение с помощью операции CAS, чтобы другие знали, что это сообщение находится в работе и, следовательно, заблокировано. Проблема многогранна. Либо ожидающий подписчик использует спин-блокировку, либо он просто получает информацию от базовой системы. И то, и другое требует учета на системном уровне.
Алгоритм — II: Если предположить, что на стороне издателя нет никаких изменений, подписчик TMQ должен играть обе роли: подписчик TMQ и издатель Mirror-TSQ. Следовательно, любое изменение в логике сегментирования повлечет за собой время простоя конечной точки подписчика. Таким образом, изменение должно быть отражено в очень короткие сроки. В противном случае TMQ под нагрузкой будет расти быстрее.
Алгоритм — III. Это лучший подход, поскольку прием данных распределяется между несколькими очередями. В конечном итоге мы придем к этому решению, когда я буду описывать алгоритм ниже. При поэтапном развертывании издателей, даже при достижении этого алгоритма, нам нужен Алгоритм-II, который будет существовать в течение переходного времени.
Для достижения Алгоритма-III в производственной среде самой большой проблемой является «Пошаговый выпуск» кодовой базы.
Любая система реального времени не допускает простоев с точки зрения издателя, и поэтому мы должны развертывать новый код в том же пуле серверов, в котором есть существующая база старого кода, одновременно принимающая на себя нагрузку. Чтобы убедиться, что новая кодовая база обратно совместима, я буду использовать экспериментальную систему AB, чтобы убедиться, что она выполняет старый поток кода. Как только на всех серверах в пуле серверов будет развернут новый код, система AB переключит его значение. Как только значение системы AB будет переключено, каждый сервер в пуле серверов начнет выполнять новую кодовую базу. Так что подумайте о новом коде, содержащем старый поток кода в «else» части проверки «if». Условие «если» проверяет значение A-B для выполнения «нового» потока. В противном случае будет выполняться «старый» поток кода.
Мы уже говорили об алгоритме — я знаю, что он требует блокировки, и нам не нравится механизм блокировки в загруженной среде.
Решение для алгоритма — II: изменение на стороне подписчика
Подход без блокировки и не требует изменения кода издателя. Иногда издатель принадлежит третьей стороне, и нет никакого контроля над этим.
Помните, что нам нужно каким-то образом разделить данные, чтобы добиться параллелизма и, следовательно, масштабирования.

Подписчик TMQ играет обе роли, извлекая сообщение из TMQ и публикуя его в TSQ. Допустим, подписчик основной очереди (TMQ) извлекает сообщения, применяет сегментирование к типу сообщения (MT) и помещает сообщение в выделенную очередь каждая транзакционная сегментированная очередь (TSQ). Аналогичным образом каждый TSQ будет иметь только одного подписчика для поддержания транзакционного поведения. Достигается и порядок МП, и параллелизм.
Предостережение: у нас все еще есть TMQ как удушающая трубка. Что делать, если подписчик TMQ потребляет сообщения с меньшей скоростью. Эта очередь все равно будет расти.
Это заставляет нас задуматься о реализации Алгоритма-III.
Решение для алгоритма — III: изменение как на стороне издателя, так и на стороне подписчика
Как насчет полного удаления TMQ и того, чтобы сами издатели применяли сегментирование и отправляли данные в TSQ?
Это позволит удалить ненужный TMQ, который является узким местом в архитектуре.
Шаги :
Давайте создадим TSQ, применив «согласованное хеширование» или любой другой метод.
Создайте такое же количество зеркал — TSQ. Думайте о них как о зеркальном отображении соответствующих TSQ. Таким образом, у нас будет такое же количество зеркал — TSQ, как и количество TSQ.
Назначьте каждому TSQ одного подписчика, чтобы транзакционное поведение не нарушалось.
Каждый подписчик TSQ также будет слушать Mirror-TSQ. Сначала они обработают любое сообщение в TSQ-зеркале, и только после получения End-Of-Message от TSQ-зеркала они начнут использовать сообщения из соответствующего TSQ.
Каждый подписчик TSQ будет ждать, пока он не получит сообщение с пометкой End-Of-Message в Mirror-TSQ.
Это гарантирует, что любой подписчик не будет обрабатывать сообщения от TSQ до тех пор, пока они не получат сообщение с пометкой End-of-Message в Mirror-TSQ.
Логика сегментирования подписчика TMQ такая же, как и используемая издателем (издателями) TMQ.
Резюме:
Мы создали — TSQ и соответствующие Mirror-TSQ для каждого TSQ.
У нас также есть логика сегментирования, которая будет решать, какое сообщение будет отправлено в какой TSQ.
Давайте теперь перейдем к процедуре развертывания: самая сложная часть.
Развертывание подписчика (TMQ) с логикой сегментирования
Издатели все еще публикуют сообщения в TMQ.
Пришло время развернуть измененного подписчика TMQ, который имеет логику сегментирования для распространения сообщений от TMQ ко всем MIRROR-TSQ.
Это гарантирует, что последовательность сохраняется, а сообщения от TMQ передаются на несколько зеркальных TSQ.
Таким образом, сообщения от TMQ теперь одновременно обрабатываются каждым потребителем Mirror-TSQ, которые также прослушивают основной TSQ, но сначала будут обрабатывать сообщение от Mirror-TSQ, пока не получат сообщение с пометкой End-of-Message. Mirror-TSQ можно создать на другом оборудовании для горизонтального масштабирования.
End-of-Message будет отправлен подписчиком TMQ, когда он обнаружит, что TMQ пуст, а также все издатели получат новый код и получат возможность отправлять данные в TSQ. Эта конкретная информация хранится, скажем, в БД, и за нее отвечает менеджер выпуска издателя (издателей).

Развертывание издателей с логикой сегментирования
Пришло время развернуть издателей.
Важно, чтобы новый код (подписчик TMQ) не начал отправлять данные в TSQ до тех пор, пока все новые издатели не будут развернуты с новой кодовой базой. В противном случае какой-то издатель со старой базой кода будет по-прежнему отправлять данные в TMQ, а какой-то новый издатель будет отправлять данные в TSQ. Это нарушит последовательный характер и, следовательно, поведение транзакций.
Следовательно, код издателя должен быть обратно совместимым.
Перед отправкой данных они считывают конфигурацию (либо через систему A/B, либо через базу данных, либо конфигурацию и т. д.). Если конфигурация говорит, что пора публиковать данные в TSQ, то только они будут отправлять данные в TSQ. В противном случае они все равно будут отправлять данные в TMQ.
Поскольку издатели также используют ту же логику сегментирования. Они будут отправлять те же сообщения в TSQ, которые подписчик TMQ также использует для отправки сообщения в Mirror-TSQ.

Когда маркер в БД установлен, все издатели развернуты. Подписчик TMQ убедится, что в TMQ нет данных, а рынок установлен в БД. Это означает, что настало время отправить End-of-Message на каждый Mirror-TSQ, чтобы подписчики каждого Mirror-TSQ также переключились на получение сообщений из основного TSQ.
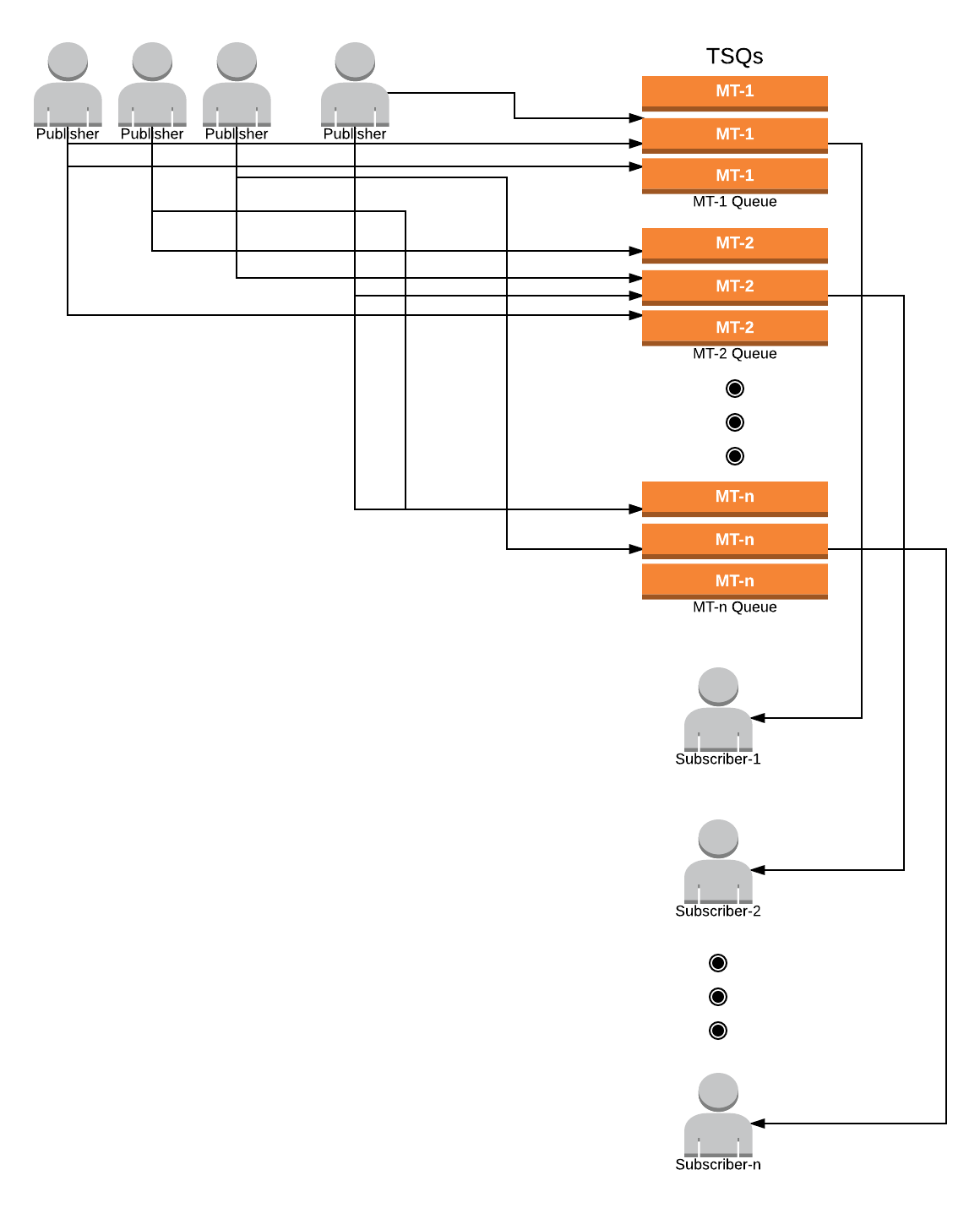
Теперь мы добились того, что несколько производителей распределяют данные по нескольким TSQ, и у каждого нескольких TSQ будет только один подписчик для обеспечения последовательной обработки.
Наконец, мы должны получить увеличенное решение, как показано на диаграмме ниже.
Читатели, пожалуйста, оставьте свои комментарии, если хотите, или, что более важно, вы нашли какую-то ошибку и т. д.…