Как использовать scikit-learn, pickle, Flask, Microsoft Azure и ipywidgets для полного развертывания алгоритма машинного обучения Python в реальной производственной среде.

Введение
В октябре 2021 года я написал статью Развертывание проектов машинного обучения и науки о данных в виде общедоступных веб-приложений (см. https://towardsdatascience.com/deploying-machine-learning-and-data-science-projects-as-public- веб-приложения-3abc91088c11).
В этой статье я рассмотрел, как развернуть Jupyter Notebooks как общедоступные веб-приложения с помощью Voila, GitHub и mybinder.
После того, как статья была опубликована, я получил отзывы от читателей, которые интересовались, как продвигать производственное развертывание дальше, чтобы изучить, как алгоритм машинного обучения может быть полностью развернут в реальной производственной среде, чтобы его можно было «использовать» независимо от платформы. и это привело к идее этой статьи…
Шаг 1. Разработайте алгоритм машинного обучения
Первым шагом является разработка алгоритма машинного обучения, который мы хотим развернуть. В реальном мире это может занять много недель или месяцев разработки и множество итераций по этапам конвейера обработки данных, но для этого примера я разработаю базовый алгоритм машинного обучения, поскольку основная цель этой статьи — найти способ развернуть алгоритм для использования «потребителями».
Я выбрал набор данных из kaggle (https://www.kaggle.com/prathamtripathi/drug-classification), который был создан автором с лицензией CC0: Public Domain, что означает, что он не имеет авторских прав и что его можно использовать в другой работе без ограничений (подробнее см. https://creativecommons.org/publicdomain/zero/1.0/).
Код Python для разработки алгоритма прогнозирующего машинного обучения для классификации рецептов на лекарства с учетом ряда критериев пациента выглядит следующим образом:
0.99 0.012247448713915901
На данный момент мы видим, что у нас есть алгоритм машинного обучения, обученный прогнозировать рецепты на лекарства, и что перекрестная проверка (т.е. сложение данных) использовалась для оценки точности модели на уровне 99%.
Все идет нормально ...
Мы собираемся развернуть эту модель в производственной среде, и, хотя это простой пример, мы не хотели бы переобучать нашу модель в реальной среде каждый раз, когда пользователь хочет предсказать рецепт лекарства, поэтому наш следующий шаг — сохранить состояние нашей обученной модели с использованием pickle...
Теперь всякий раз, когда мы хотим использовать обученную модель, нам просто нужно перезагрузить ее состояние из файла model.pkl, а не повторно выполнять шаг обучения.
Шаг 2: Сделайте индивидуальный прогноз на основе обученной модели
Я собираюсь сделать пару предположений на шаге 2 -
- У потребителей алгоритма машинного обучения есть требования делать прогнозы для отдельных пациентов, а не для группы пациентов.
- Эти потребители хотят общаться с алгоритмом, используя текстовые значения для параметров (например, кровяное давление = «НОРМАЛЬНОЕ» или «ВЫСОКОЕ», а не их эквиваленты, закодированные на этикетке, такие как 0 и 1.
Поэтому мы начнем с рассмотрения значений всех закодированных метками категориальных признаков, используемых в качестве входных данных для алгоритма…
Sex ['F', 'M'] [0, 1] BP ['HIGH', 'LOW', 'NORMAL'] [0, 1, 2] Cholesterol ['HIGH', 'NORMAL'] [0, 1] Drug ['DrugY', 'drugC', 'drugX', 'drugA', 'drugB'] [0, 3, 4, 1, 2]
И вот у нас есть список каждой категориальной функции с уникальными значениями, которые появляются в данных, и соответствующими числовыми значениями, преобразованными с помощью LabelEncoder().
Вооружившись этими знаниями, мы можем предоставить набор словарей, которые отображают текстовые значения (например, «ВЫСОКИЙ», «НИЗКИЙ» и т. д.) в их закодированные эквиваленты, а затем разработать простую функцию для создания отдельных прогнозов следующим образом…
Затем эту реализацию можно проверить, вызвав функцию, чтобы сделать некоторые прогнозы на основе значений исходных данных, чтобы мы знали, какими должны быть выходные данные…
'drugC'
'DrugY'
Обратите внимание, что нашей функции predict_drug не нужно обучать модель, она скорее «повторно гидратирует» модель, состояние которой ранее было сохранено с помощью pickle, в файл model.pkl, и из вывода мы видим, что прогнозы для рекомендаций по лекарствам верны.
Шаг 3. Разработайте оболочку веб-службы
Пока все выглядит хорошо, но вот главная проблема: клиенты или потребители нашего алгоритма машинного обучения должны быть написаны на языке программирования Python, и не только это, мы должны иметь возможность изменять и модифицировать приложение.
Что, если стороннее приложение захочет использовать и использовать наш алгоритм, и что, если это стороннее приложение не написано на Python? Возможно, он написан на Java, C#, JavaScript или каком-то другом языке, отличном от Python.
Здесь на помощь приходят веб-службы. Веб-служба — это «оболочка», которая получает запросы от клиентов и потребителей с помощью команд http GET и http PUT, вызывает код Python и возвращает результат в виде ответа HTML.
Это означает, что клиентам и вызывающим сторонам нужно только иметь возможность формулировать HTTP-запросы, и почти все языки программирования и среды имеют способ сделать это.
В мире Python доступно несколько различных подходов, но я выбрал тот, который заключается в использовании flask для создания оболочки нашего веб-сервиса.
Код не очень сложен, но может быть сложно настроить VS Code, чтобы разработчики могли отлаживать приложение flask. Если вам нужен учебник для этого шага, ознакомьтесь с моей статьей Как отлаживать приложения Flask в VS Code, которую можно найти здесь — https://towardsdatascience.com/how-to-debug-flask-applications-in. -vs-код-c65c9bdbef21».
Вот код оболочки для веб-сервиса…
Запустите IDE VS Code со страницы Anaconda Navigator (или запустив командную строку Anaconda и введя code). Это запустит VS Code с базовой средой conda, которая требуется для запуска и отладки приложения flask.
Веб-службу можно запустить изнутри VS Code, нажав «Запустить и отладить», а затем выбрав «Запуск и отладка веб-приложения Flask».

Если все пошло по плану, последним сообщением в окне ТЕРМИНАЛА должно быть Running on http://127.0.0.1:5000/ (Press CTRL+C to quit), что указывает на то, что ваше веб-приложение flask запущено и работает.
Теперь вы должны протестировать веб-службу, используя один из этих методов:
- Откройте веб-браузер и введите: http://127.0.0.1:5000/drug?Age=60&Sex=F&BP=LOW&Cholesterol=HIGH&Na_to_K=20
- Откройте командную строку анаконды и введите:
curl -X GET "http://127.0.0.1:5000/drug?Age=60&Sex=F&BP=LOW&Cholesterol=HIGH&Na_to_K=20"

Если вы хотите узнать больше о разработке flask приложений и веб-сервисов, эти статьи — отличное место для начала:
- https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask
- https://code.visualstudio.com/docs/python/tutorial-flask
Шаг 4. Разверните веб-службу в Microsoft Azure.
Теперь у нас есть прогностический алгоритм машинного обучения, который может прогнозировать назначение лекарств с точностью 99%, у нас есть вспомогательная функция, которая может делать индивидуальные прогнозы, и у нас есть оболочка веб-сервиса, которая позволяет вызывать эти компоненты из браузера или командной строки.
Однако все это по-прежнему можно вызывать только из среды разработки. Следующий этап — развернуть все в облаке, чтобы клиенты могли «потреблять» веб-службу через общедоступный Интернет.
Существует множество различных общедоступных сервисов, доступных для развертывания веб-приложений, в том числе:
- Google — https://cloud.google.com/appengine/docs/standard/python3/building-app/writing-web-service
- Amazon Web Services — https://medium.com/@rodkey/deploying-a-flask-application-on-aws-a72daba6bb80
- Microsoft Azure — https://medium.com/@nikovrdoljak/deploy-your-flask-app-on-azure-in-3-easy-steps-b2fe388a589e
Я выбрал Azure, потому что он бесплатный (для учетной записи начального уровня), простой в использовании, быстрый и полностью интегрированный с VS Code, который является моей любимой средой разработки.
Шаг 4.1. Добавьте расширение службы приложений Azure в VS Code.
Переключите задачи в VS Code, перейдите в «Расширения» (Ctrl+Shft_X) и добавьте расширение «Azure App Service». После добавления расширения вы увидите новый значок Azure на панели действий —

Шаг 4.1. Создайте учетную запись Azure.
У вас должна быть учетная запись, чтобы начать развертывание в облаке Azure, и вы должны предоставить данные кредитной карты в процессе регистрации. Однако с вас не будет взиматься плата, если вы специально не решите отказаться от бесплатной лицензии.
Вы можете следовать инструкциям на этой странице — https://azure.microsoft.com/en-gb/free/, чтобы создать бесплатную учетную запись Azure через браузер, но проще всего нажать на новый значок Azure в на панели действий и выберите Создать бесплатную учетную запись Azure (или Войти в Azure, если она у вас уже есть).

Шаг 4.3. Создайте веб-приложение Azure.
Следующим шагом является создание веб-приложения Azure для размещения вашего приложения, нажав значок «+» в окне «APP SERVICE». Вам будет предложено ввести имя для приложения. Имя будет использоваться в конечном URL-адресе, и оно должно быть уникальным, но в остальном имя не имеет особого значения.
Когда будет предложено указать тип лицензии, выберите «Бесплатная пробная версия» — теперь ваше веб-приложение будет создано, и вы готовы к развертыванию.
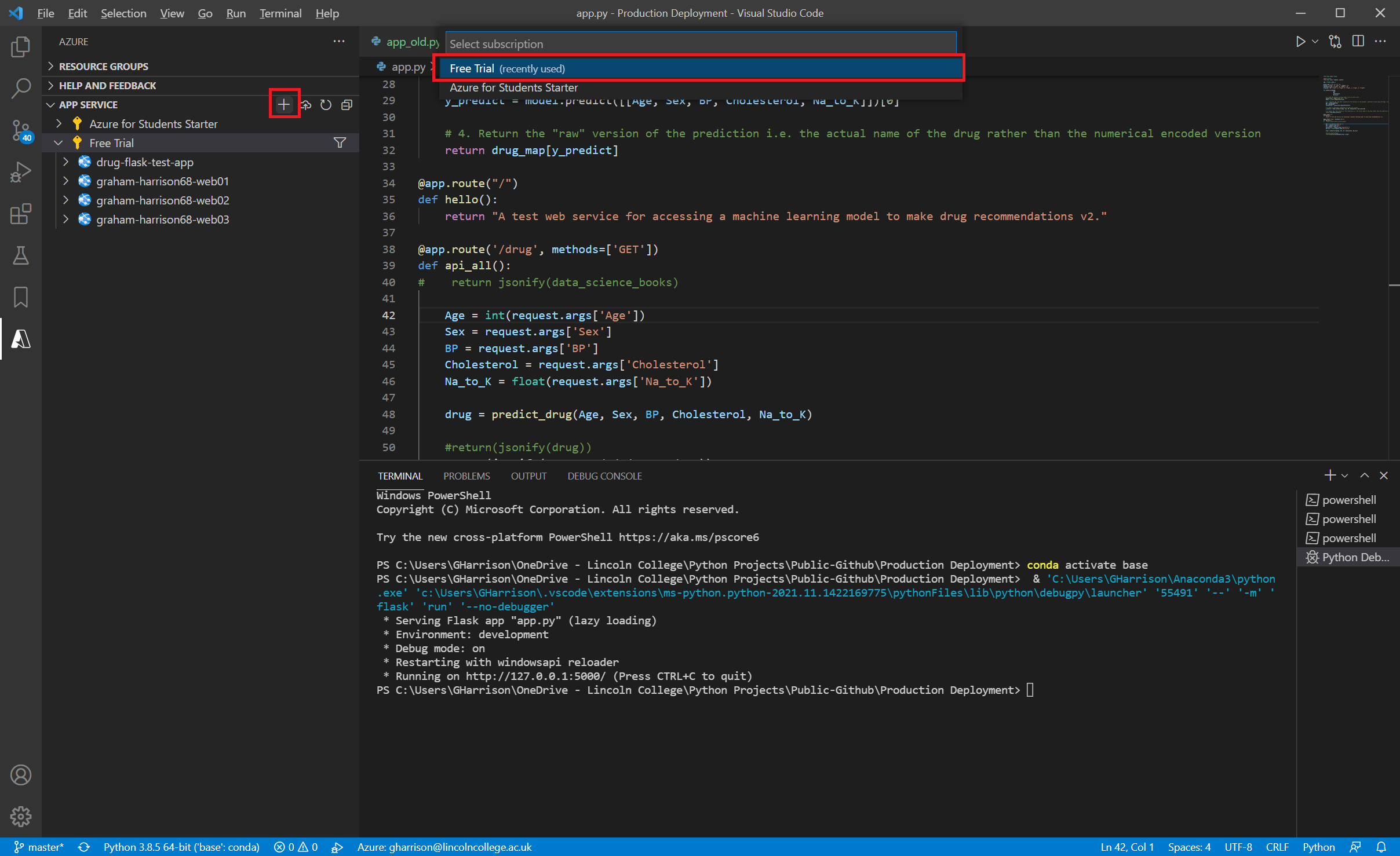
Шаг 4.4. Создайте файл развертывания «requirements.txt»
Прежде чем вы сможете развернуть приложение в Azure, вы должны создать файл «requirements.txt» в той же папке, что и ваше веб-приложение Flask, который содержит список всех зависимостей и библиотек, которые Azure должна установить для запуска вашего приложения. Этот шаг жизненно важен, так как если библиотеки не находятся в развернутой среде, приложение выйдет из строя.
Содержимое requirements.txt для нашего приложения следующее:
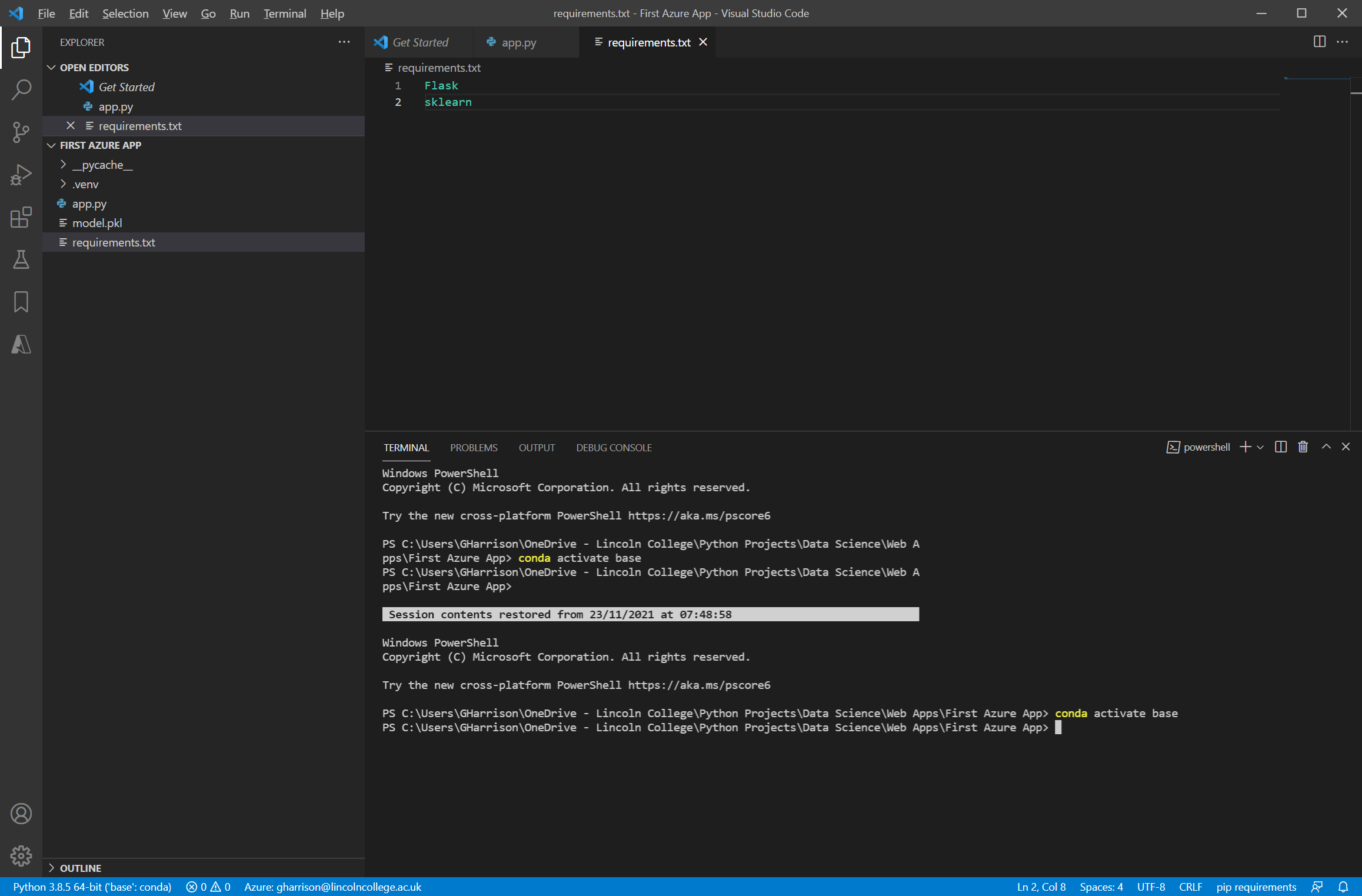
Некоторые моменты, на которые следует обратить внимание -
- Имена библиотек должны точно совпадать с теми, которые вы вводили бы, если бы устанавливали с помощью pip, например
pip install Flask. - Обратите внимание, что
Flaskимеет заглавную букву «F». Это связано с тем, что Flask необычно пишется с заглавной буквы таким образом, обычно все библиотеки пишутся в нижнем регистре. sklearnтребуется для выполнения регидратированногоmodel.pkl. Хотя sklearn иDecisionTreeClassifierявно не упоминаются в коде, они необходимы дляmodel.fit, поэтому, еслиsklearnопущено, приложение вылетит.- Ссылка на
pickleне требуется, поскольку эта библиотека является частью базовой установки Python. Если вы включитеpickle, произойдет сбой развертывания, поскольку вы не сможете выполнитьpip install pickle.
Если вы придерживаетесь этих правил, ваше развертывание будет работать, и любые сообщения об ошибках обычно достаточно информативны, чтобы можно было решить проблемы с помощью небольшого исследования в Интернете.
Шаг 4.5. Разверните приложение в Azure
Если вы следовали этим шагам до сих пор, у вас теперь есть приложение Flask внутри VS Code. Файл кода вашего приложения будет называться app.py, а имя приложения — app. Приложение Flask было протестировано на локальном веб-сервере разработки.
Вы установили расширение приложения VS Code Azure и использовали его для создания бесплатной учетной записи Microsoft Azure, а также для создания веб-приложения Azure.
Ваше приложение Flask должно быть открыто в VS Code, и у вас есть все необходимое для развертывания приложения в облаке.
Для этого достаточно щелкнуть имя веб-приложения рядом со значком синего круга, а затем щелкнуть значок облака рядом со знаком «+».
При появлении запроса выберите следующее -
- Выберите папку по умолчанию для развертывания
- Выберите подписку «Бесплатная пробная версия».
- Выберите имя веб-приложения, которое вы создали
- Если будет предложено перезаписать, выберите «Развернуть».
- Когда вас попросят «Всегда развертывать…», выберите «Пропустить сейчас».
- Когда начнется развертывание, нажмите «окно вывода».
А теперь откиньтесь на спинку кресла и приготовьте кофе, пока приложение развертывается.

Когда развертывание будет завершено, нажмите «Обзор веб-сайта», и вы перейдете на правильный URL-адрес, который запустит функцию app.route("/").
Просто добавьте те же параметры URL, которые мы использовали для тестирования локального развертывания, и вы увидите результат полностью развернутого веб-приложения! -
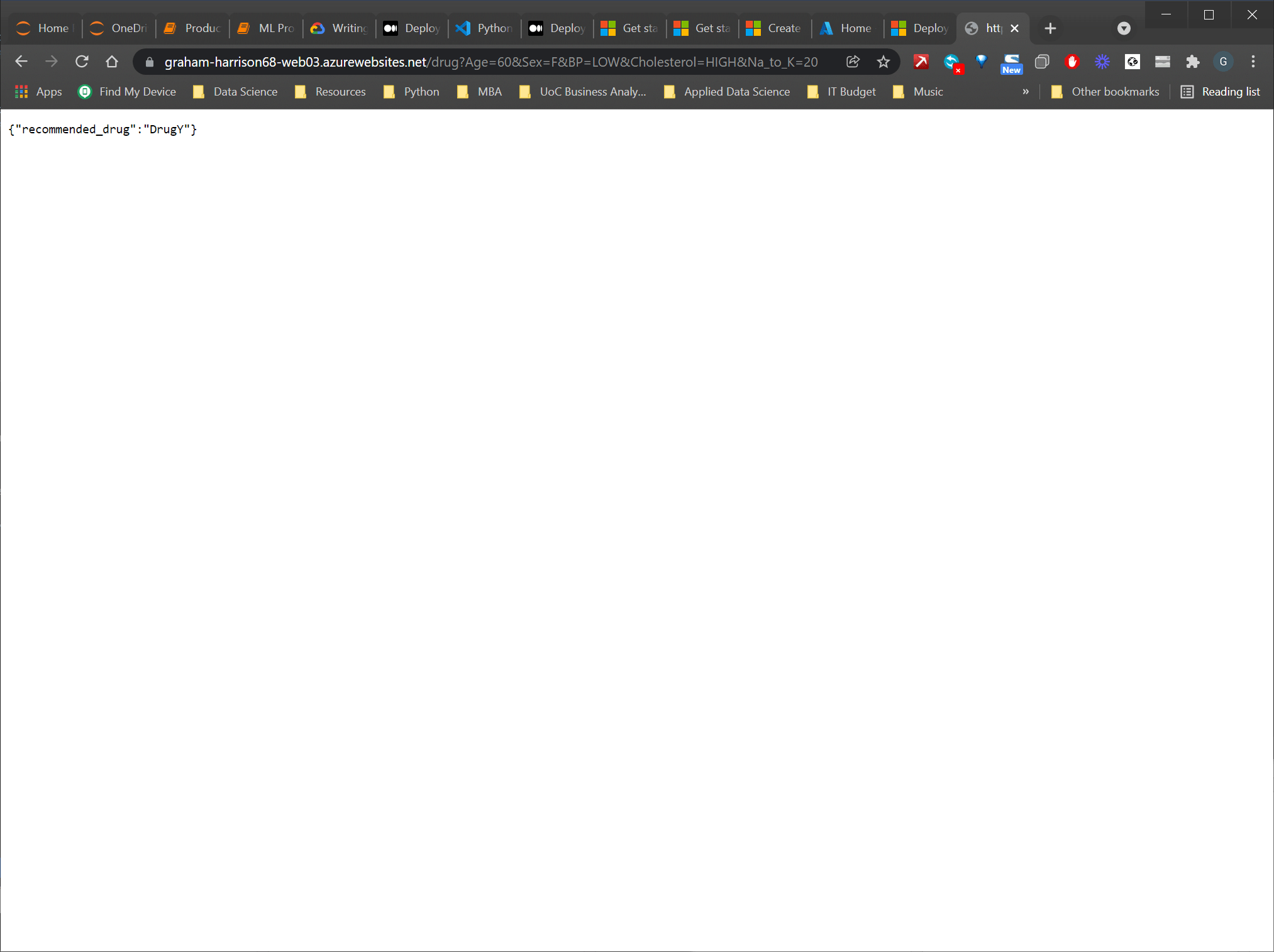
Обратите внимание: через некоторое время лазурное приложение переходит в спящий режим, и первый вызов после этого занимает очень много времени.
Если вы решите перейти на платную подписку Azure, у вас есть возможность обновлять приложение и «бодрствовать», но в бесплатной подписке нельзя избежать задержки, связанной со сном, поскольку эта подписка предназначена для целей тестирования и, как таковая, несколько ограничений.
Шаг 5. Создание клиентского приложения для использования веб-службы, развернутой в Azure.
На этом этапе любой язык программирования или среда, которые могут вызывать веб-запросы, могут вызвать развернутую веб-службу всего несколькими строками кода.
Мы начали с того, что сказали, что можно использовать среды, отличные от Python, такие как C#, JavaScript и т. д., но я закончу этот пример, написав некоторый код для вызова развернутого приложения из клиента Python, используя ipywidgets -
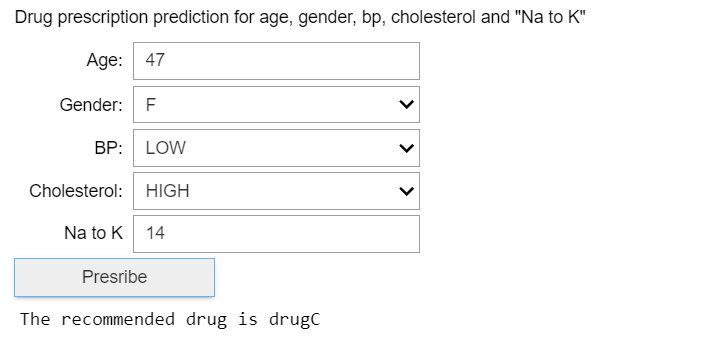
Если вы нажмете «Предписать» со значениями по умолчанию, рекомендация должна быть для «drugC».
Измените Age на 60 и Na на K на 20 и пропишите «DrugY». Верните Возраст обратно на 47, Na на К на 14 и измените АД на «ВЫСОКОЕ», и следует назначить препарат А.
Эти простые тесты доказывают, что веб-служба, размещенная в Azure, использующая алгоритм прогнозирующего машинного обучения на основе дерева решений, полностью развернута в общедоступном облаке, может быть вызвана любой средой разработки, способной выполнять команду http GET, и полностью работает от начала до конца. .
Заключение
Требуется довольно много шагов, но с помощью легкодоступных библиотек и бесплатных инструментов, включая scikit-learn, pickle, flask, Microsoft Azure и ipywidgets, мы создали полностью работающее общедоступное облачное развертывание алгоритма машинного обучения и полностью функционирующего клиента. для вызова и использования веб-службы и отображения результатов.
Дальнейшее чтение
Если вы нашли это руководство интересным, я бы порекомендовал эту статью, в которой более подробно рассматриваются стратегии развертывания моделей —
Спасибо за чтение!
Если вам понравилось читать эту статью, почему бы не ознакомиться с другими моими статьями на https://grahamharrison-86487.medium.com/?
Кроме того, я хотел бы услышать от вас, что вы думаете об этой статье, любых других моих статьях или о чем-либо еще, связанном с наукой о данных и анализом данных.
Если вы хотите связаться с нами для обсуждения любой из этих тем, найдите меня в LinkedIn — https://www.linkedin.com/in/grahamharrison1 или напишите мне по электронной почте GHarrison@lincolncollege. ac.uk.
Если вы хотите поддержать автора и тысячи других людей, которые вносят свой вклад в написание статей по всему миру, подписавшись, воспользуйтесь этой ссылкой — https://grahamharrison-86487.medium.com/membership. Примечание: автор получит часть гонорара, если вы зарегистрируетесь по этой ссылке.