Пошаговая реализация с анимацией для лучшего понимания.

Вернуться к предыдущему сообщению
2.2 Что такое SGD с Momentum?
SGD с Momentum — один из наиболее часто используемых оптимизаторов в DL. И идея, и реализация просты. Хитрость заключается в том, чтобы использовать часть предыдущего обновления, и эта часть представляет собой скаляр под названием «Импульс».
Вы можете загрузить Jupyter Notebook здесь.
Примечание — Рекомендуем ознакомиться с предыдущим постом.
Этот пост разделен на 3 части
- SGD с моментумом в 1 переменной
- SGD с анимацией Momentum для 1 переменной
- SGD с Momentum в функции с несколькими переменными
SGD с Momentum в функции 1 переменной
SGD с Momentum — это вариант SGD.
В этом методе мы используем часть предыдущего обновления.
Эта часть представляет собой скаляр под названием «Импульс», значение которого обычно принимается равным 0,9.
Все аналогично тому, что мы делали в SGD, за исключением того, что здесь мы должны сначала инициализировать update = 0 и при вычислении обновления мы добавляем часть предыдущего обновления, т. е. импульс * обновление
Итак, SGD с алгоритмом Momentum на очень простом языке выглядит следующим образом:
Step 1 - Set starting point and learning rate
Step 2 - Initialize update = 0 and momentum = 0.9
Step 3 - Initiate loop
Step 3.1 Calculate update = -learning_rate * gradient +
momentum * update
Step 3.2 add update to point
Во-первых, давайте определим функцию и ее производную, и мы начнем с x = -1
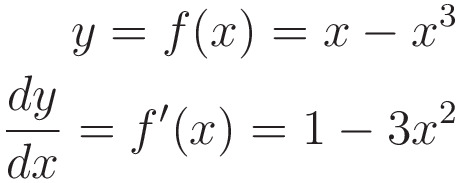
import numpy as np
np.random.seed(42)
def f(x): # function definition
return x - x**3
def fdash(x): # function derivative definition
return 1 - 3*(x**2)

А теперь SGD с Momentum
point = -1 # step 1
learning_rate = 0.01
momentum = 0.9 # step 2
update = 0
for i in range(1000): # step 3
update = - learning_rate * fdash(point) + momentum * update
# step 3.1
point += update # step 3.2
point # Minima

Посмотрите, как легко реализовать SGD с Momentum в Python.
SGD с Momentum Animation для лучшего понимания
Все то же самое, что мы делали ранее для анимации SGD. Мы создадим список для хранения начальной точки и обновленных точек в нем и будем использовать значение индекса iᵗʰ для iᵗʰ кадра анимации.
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from matplotlib.animation import PillowWriter
point_sgd_momentum = [-1] # initiating list with
# starting point in it
point = -1 # step 1
learning_rate = 0.01
momentum = 0.9 # step 2
update = 0
for i in range(1000): # step 3
update = momentum * update - learning_rate * fdash(point)
# step 3.1
point += update # step 3.2
point_sgd_momentum.append(point) # adding updated point
# to the list
point # Minima

Мы сделаем некоторые настройки для нашего графика для анимации. Вы можете изменить их, если хотите что-то другое.
plt.rcParams.update({'font.size': 22})
fig = plt.figure(dpi = 100)
fig.set_figheight(10.80)
fig.set_figwidth(19.20)
x_ = np.linspace(-5, 5, 10000)
y_ = f(x_)
ax = plt.axes()
ax.plot(x_, y_)
ax.grid(alpha = 0.5)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax.set_xlabel('x')
ax.set_ylabel('y', rotation = 0)
ax.scatter(-1, f(-1), color = 'red')
ax.hlines(f(-0.5773502691896256), -5, 5, linestyles = 'dashed', alpha = 0.5)
ax.set_title('SGD with Momentum, learning_rate = 0.01')


Теперь мы анимируем SGD с помощью оптимизатора Momentum.
def animate(i):
ax.clear()
ax.plot(x_, y_)
ax.grid(alpha = 0.5)
ax.set_xlim(-5, 5)
ax.set_ylim(-5, 5)
ax.set_xlabel('x')
ax.set_ylabel('y', rotation = 0)
ax.hlines(f(-0.5773502691896256), -5, 5, linestyles = 'dashed', alpha = 0.5)
ax.set_title('SGD with Momentum, learning_rate = 0.01')
ax.scatter(point_sgd_momentum[i], f(point_sgd_momentum[i]), color = 'red')
Последняя строка в приведенном выше фрагменте кода использует значение индекса iᵗʰ из списка для кадра iᵗʰ в анимации.
anim = animation.FuncAnimation(fig, animate, frames = 200, interval = 20)
anim.save('2.2 SGD with Momentum.gif')
Мы создаем анимацию, которая имеет только 200 кадров, а gif имеет частоту 50 кадров в секунду или интервал между кадрами составляет 20 мс.
Следует отметить, что менее чем за 200 итераций мы достигли минимума.

SGD с Momentum в функции с несколькими переменными (сейчас 2 переменные)
Все то же самое, нам нужно только инициализировать точку (1, 0) и обновить = 0, но с формой (2, 1) и заменить fdash (точка) на градиент (точка).
Но сначала определим функцию, ее частные производные и массив градиентов
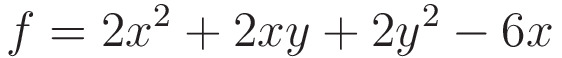
Мы знаем, что минимум для этой функции равен (2, -1)
, и мы начнем с (1, 0)
Частные производные
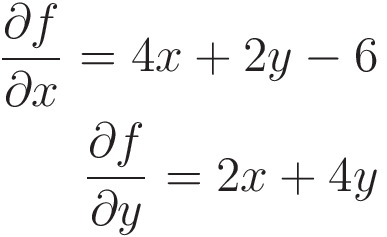
def f(x, y): # function
return 2*(x**2) + 2*x*y + 2*(y**2) - 6*x # definition
def fdash_x(x, y): # partial derivative
return 4*x + 2*y - 6 # w.r.t x
def fdash_y(x, y): # partial derivative
return 2*x + 4*y # w.r.t y
def gradient(point):
return np.array([[ fdash_x(point[0][0], point[1][0]) ],
[ fdash_y(point[0][0], point[1][0]) ]], dtype = np.float64) # gradients

Теперь шаги для SGD с Momentum в 2 переменных
point = np.array([[ 1 ], # step 1
[ 0 ]], dtype = np.float64)
learning_rate = 0.01
momentum = 0.9 # step 2
update = np.array([[ 0 ],
[ 0 ]], dtype = np.float64)
for i in range(1000): # step 3
update = - learning_rate * gradient(point) + momentum * update
# step 3.1
point += update # step 3.2
point # Minima

Надеюсь, теперь вы понимаете SGD с Momentum.
Теперь в качестве бонуса давайте посмотрим, чем SGD с Momentum лучше, чем SGD.
У нас есть функция
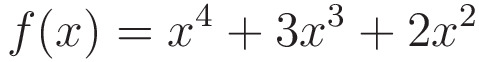
а это график функции
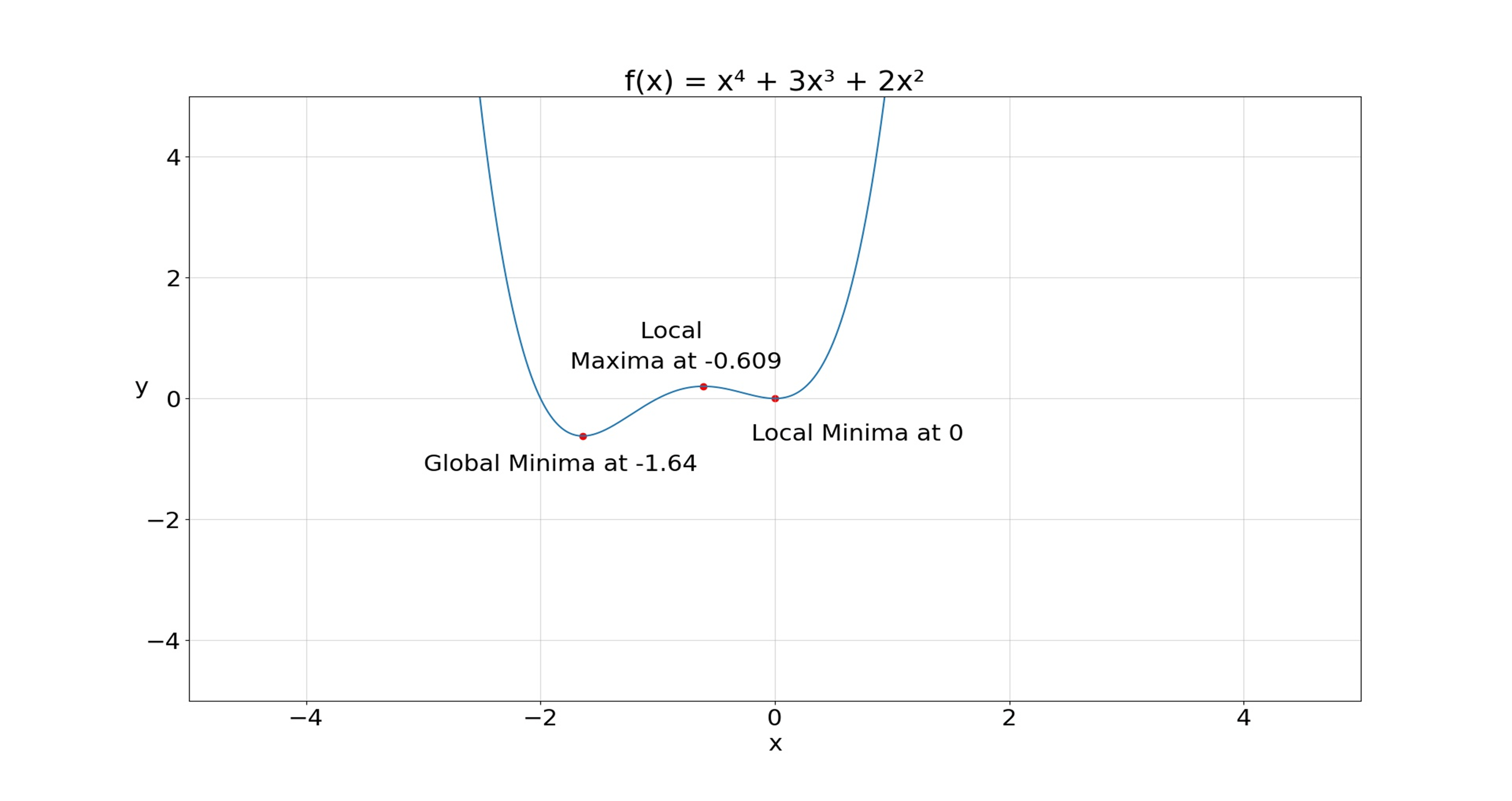
Теперь, если мы начнем с x = 0,75 со скоростью обучения = 0,01 и используем оптимизатор SGD, то мы достигнем локальных минимумов при x = 0.

Но если мы начнем с x = 0,75 со скоростью обучения = 0,01 и используем SGD с оптимизаторами Momentum с импульсом = 0,9, то мы достигнем глобальных минимумов при x = -1,64.

Вам нужно только изменить f(x), fdash(x) и начальную точку с несколькими настройками графика.
Смотрите видео на youtube и подписывайтесь на канал, чтобы получать такие видео и посты.
Каждый слайд длится 3 секунды и без звука. Вы можете поставить видео на паузу, когда захотите.
Вы также можете включить музыку, если хотите.
В видео в принципе все что есть в посте только в слайдах.
Большое спасибо за вашу поддержку и отзывы.
Если вам понравился этот курс, вы можете поддержать меня на


Это много значило бы для меня.
Перейти к следующему сообщению — 2,3 SGD с ускорением Нестерова.