Я нахожусь в той фазе, когда собеседование по программированию меня немного пугает. Это этап процесса найма, которого боится большинство из нас. Требуется много энергии и усилий, чтобы преодолеть это. Вот почему последние пару недель я практиковался в написании кода на собеседованиях. Я просто готовлюсь к собеседованию по программированию, так как в последнее время подаю заявку на вакансию. И одна из самых распространенных тем для разговора на собеседовании по кодированию — это нотация Big-O.
Всякий раз, когда мы пишем и выполняем наш код, он должен потреблять наши ресурсы (в данном случае это время и пространство). Время относится к тому, как долго код будет выполняться, а пространство — к тому, насколько большой код займет нашу память. И вот тут-то и появляется Big-O. Он используется для измерения временной и пространственной сложности нашего кода. Если бы мы могли определить сложность нашего кода, мы смогли бы улучшить его производительность.
Биг Ос
Существует веб-сайт под названием Big-O Cheat Sheet, где мы можем найти список различных нотаций Big-O. Он ранжируется от худшего к лучшему, вы можете обратиться к цвету области, на которую падает обозначение.
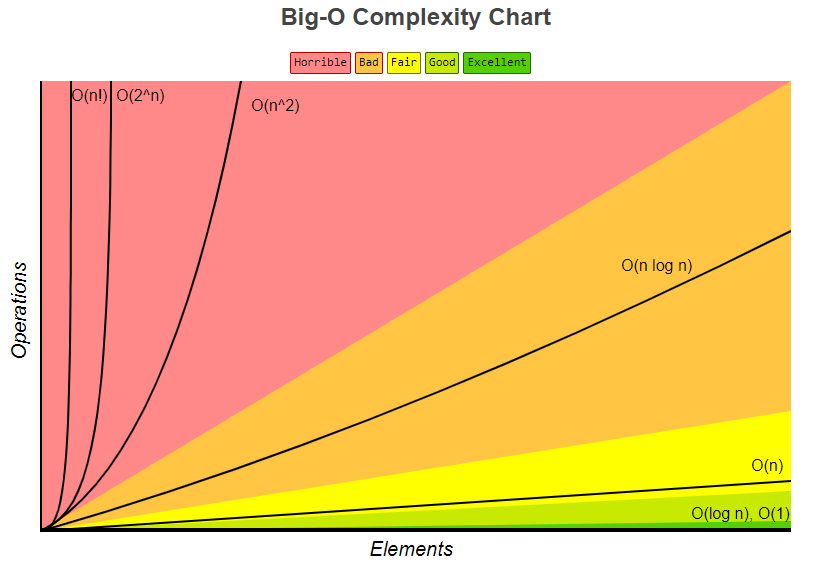
Из этих обозначений выше мы могли бы использовать их для повышения производительности при выполнении нашего кода. Например, когда мы создали функцию со сложностью O(n²), мы могли бы подумать о том, как заставить нашу функцию работать с большей сложностью (те, которые помечены как «Удовлетворительно», «Хорошо» или «Отлично»). Как мы можем улучшить наш код? Вот когда на помощь приходят структуры данных и алгоритм. Мы могли бы использовать другой способ хранения наших данных, или мы могли бы также использовать другой подход для написания решения.
Но сначала нам нужно уметь определять сложность нашего кода.
Существует правило, на которое мы могли бы ссылаться, когда хотели бы определить сложность нашего кода. Это простой способ вычислить наш Big-O, вместо того, чтобы идти построчно в нашем коде.
1. Всегда наихудший случай
Вы можете догадаться, что означает это первое правило. Это правило гласило, что нам всегда нужно думать о наихудшем возможном случае всякий раз, когда мы выполняем наш код.

Например, когда мы обращаемся к члену массива с помощью цикла, мы попадаем в нотацию O(n). Но когда мы хотим найти только определенный элемент, и этот элемент является первым элементом массива, это означает, что мы запускаем эту итерацию только один раз (если мы ставим break всякий раз, когда итерация успешно находит конкретный элемент).
Но нам нужно подумать о наихудшем сценарии этого цикла. Элемент может быть последним членом массива, а это значит, что нам нужно перебирать каждый элемент, пока мы не найдем нужный элемент.
2. Удалить константы
Поскольку мы заботимся только о масштабируемости нашего кода, мы могли бы легко просто удалить константы в нашем Big-O. Позволь мне привести пример.

В приведенном выше фрагменте у нас есть функция, которая печатает элемент из массива. Затем он будет перебирать каждый элемент массива, а также выполнять еще один цикл 100 раз. Если мы вычислим Big-O построчно, мы получим O(1 + n + 1000).
Проблема с константами в том, что они не меняются при изменении ввода или размера массива. Если мы передаем массив из 10 элементов, то n будет состоять из 10. Но если мы передаем массив из миллиона, то n также будет иметь значение миллиона. Но константа останется прежней.
3. Разные входные данные должны иметь разные переменные
Третье правило довольно простое: нам нужно использовать разные переменные для разных входных данных в нашем коде. Итак, если у вас есть метод, который принимает 2 входа, например, input1 и input2. Затем метод будет перебирать элемент input1 один за другим, а также делать то же самое с элементом input2. Что было бы большим O для этого случая?
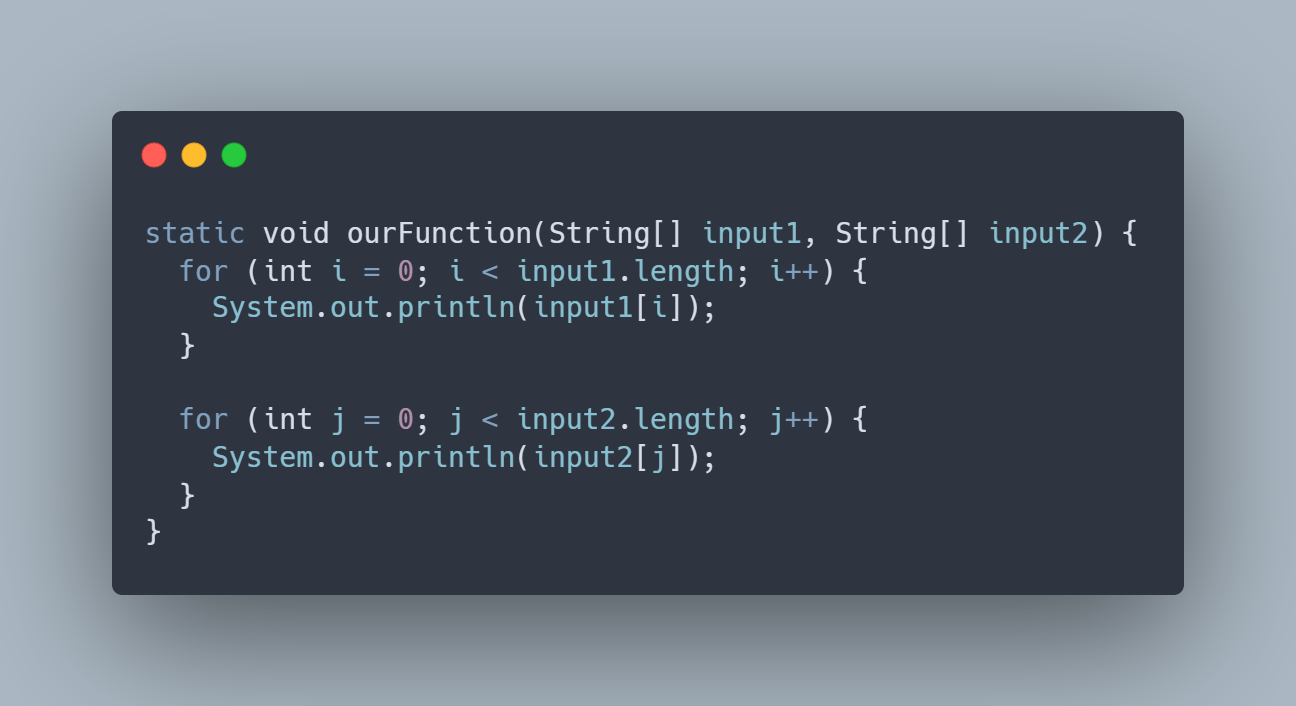
Хорошо, если вы следуете нашему правилу, то вы могли догадаться, что в нашем Big-O будет 2 разные переменные. Это будет O(a + b). В основном то же самое с O(n), но O(n) подразумевает, что у нас есть один вход. В этом случае у нас есть 2 входа, которые могут иметь разное количество членов, поэтому нам нужно указать его в 2 разных переменных для Big-O.
4. Отбросьте недоминирующие термины
Наконец, мы подошли к последнему правилу. Давайте взглянем на наш пример ниже, поскольку его будет легче понять, если мы посмотрим на пример.

Фрагмент выше имеет сложность O(n + n²). А поскольку в правиле указано отбрасывать недоминирующие термины, это означает, что нам нужно отбросить n и оставить только n². Итак, это будет O(n²). Почему? Потому что с Big-O мы заботимся о масштабируемости нашего кода. И n² будет стоить гораздо больше ресурсов, как только наш вклад будет становиться все больше и больше в будущем. Мы хотели бы сосредоточиться на худшей части, поэтому мы выбираем только доминирующий термин для нашего большого-O.
И это все! Мы рассмотрели причину, по которой нам нужно понимать временную сложность, различные обозначения Big-O, а также правила определения Big-O. Это резюме моего недавнего онлайн-курса Master the Coding Interview: Data Structures + Algorithms от Андрея Негойе (рекомендую вам купить и посмотреть курс, Андрей объясняет эту концепцию лучше меня). Курс также объясняет немного больше этой концепции, которую я еще не рассмотрел в этой статье.
Я знаю, что в этой статье рассматриваются только основы Big-O, я планирую создать еще одну статью, в которой эта концепция будет рассмотрена немного глубже. Может быть, я объясню каждый из больших O, которые мы видели на графике выше.