Как и большинство разработчиков программного обеспечения, когда я начинал свое обучение, я игнорировал изучение регулярных выражений, потому что это выглядело как что-то странное, трудное для изучения и не очень полезное.
Я думал «даже если это полезно, его легко заменить обычным кодом, так что учить его не стоит», и мое мышление не изменилось… пока мне не пришлось начать с этим работать.
Первые минуты изучения регулярных выражений с абсолютных основ были немного трудными, но после написания регулярных выражений только для некоторых примеров я получил знания, которые сделали меня более продуктивным в работе с текстами… со всеми текстами, не только с парсингом данных, не только с поиском вещей по веб-сайты, а не только в работе с кодом. Это очень удобно при работе со всеми видами текстов.
Почему это так полезно?
Regex — это просто шаблон для текста, но очень минималистичный, поэтому вы можете написать много инструкций с небольшим количеством букв.
Чтобы показать некоторые примеры, я должен объяснить некоторые элементы регулярного выражения, например
- \d означает цифру, число от 0 до 9
- \s означает пустое место, может быть пробел или табуляция
- . означает любой знак
- \w означает любую букву
- любая буква или цифра означает именно эту букву или цифру, например, е означает е, а означает а, 2 означает 2 и т. д.
- \ означает именно то, что после него, например, точка — это специальный символ, поэтому, если вы хотите найти точку, вам нужно написать «точно точка» (\.), чтобы написать «точно \», будет (\\) и т. д.
Вы можете описать количество элементов
- ? означает 0 или 1 (или просто необязательный элемент)
- {0, 10} означает от до, в данном случае от 0 до 10 элементов, {2, 5} означает от 2 до 5 элементов.
- * означает от 0 до бесконечности, поэтому это необязательно, но если элементы после сопоставления, то эти элементы будут сопоставлены
- + означает *, но не обязательно (от 1 до бесконечности)
А также есть группы, которые могут быть названы или не названы.
- если вы хотите безымянную группу, вы должны поставить регулярное выражение в скобки (регулярное выражение)
- если вам нужна именованная группа, вам нужно использовать конструкцию (?‹groupname›regex)
(группы полезны, если вы хотите использовать логику для извлечения данных из совпадающего текста, многие редакторы имеют возможность изменять текст, и это на основе именованной группы)
Вы можете определить начало и конец текста
- ^ начало текста
- $ конец текста
Выглядит не так страшно, как если бы вы смотрели примеры из интернета, верно?
(регулярное выражение для действительного адреса очень страшно… https://emailregex.com/)
Понятно, что это лишь небольшая часть элементов в регулярных выражениях, но этих знаний достаточно, чтобы работать с большинством примеров в реальной жизни. В большинстве случаев вам не нужно разбирать очень сложные тексты, вам нужно найти простые вещи, например, найти все , которые написаны после пробела.
Для этого нужно написать очень сложное регулярное выражение «\s», или более безопасное «\s\,».
Пример из жизни
В этом примере я рекомендую использовать механизм регулярных выражений, чтобы проверить, что и когда соответствует, мой любимый https://regex101.com/
У нас есть текст
Адам имеет 2 года опыта и зарабатывает 2000 в месяц
Стив имеет 2 месяца опыта и зарабатывает 20000 в год
Питер имеет 1 год опыта и зарабатывает 25000 в год
Мы хотим получить
- имя
- опыт
- зарплата
но эти значения измеряются в разных единицах, поэтому вы хотите получить название единицы.
Во-первых, вы знаете, что первым словом всегда является имя, поэтому вы можете начать свое регулярное выражение с
"^(?‹имя›\w+)"
- ^ начать со строки
- (?‹имя›\w+) поместить результаты из \w+ в группу под названием «имя»
- \w+ означает все буквы, будет совпадать до тех пор, пока не будет что-то кроме буквы, например пробел или цифра, в нашем случае будет пробел

После имени мы видим пробел (одиночный, но для предотвращения исключений в тексте лучше использовать «единицу или бесконечность»), а после этого количество + единицу. После статичного текста и та же ситуация с зарплатой.
"^(?‹name›\w+)\s*has\s*(?‹timeAmount›\d+)\s*(?‹timeUnit›(годы?)|(месяцы?))”
- \s* означает все пробелы
- имеет означает слово имеет
- \d+ означает цифры, + означает хотя бы одну, но если их больше, получить больше
- годы? означает годы слова, но буква «s» не является обязательной (? означает необязательное значение или количество от 0 до 1)
- | значит "или", значит есть безымянная группа лет? или неназванные групповые месяцы?

Если кто-то ничего не знает о регулярных выражениях, это может выглядеть пугающе… но, как видите, очень легко понять, что это регулярное выражение делает (или что ищет)
Точно так же я могу написать регулярное выражение для остального текста
“^(?‹имя›\w+)\s*has\s*(?‹timeAmount›\d+)\s*(?‹timeUnit›(годы?)|(месяцы?))\s*of \s*опыт\s*и\s*заработок\s*(?‹salaryAmount›\d+)\s*per\s*(?‹salaryUnit›(месяц)|(год))”

И в правой части веб-сайта regex101 вы можете увидеть, какой текст находится в какой группе.
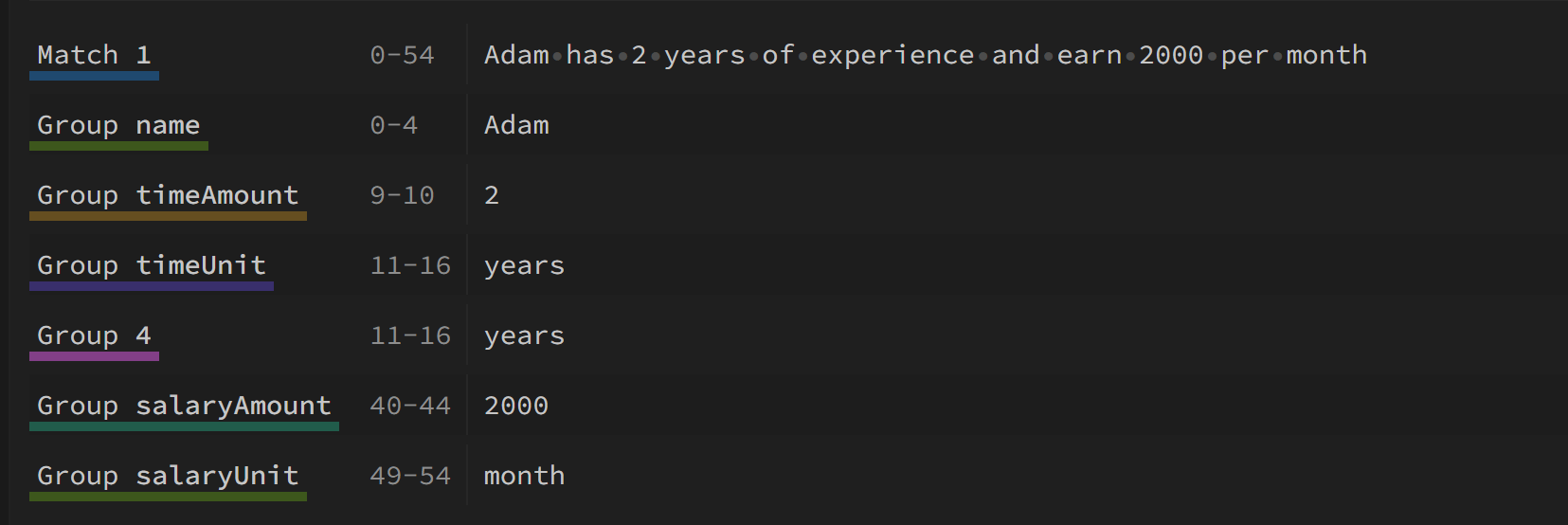

Если вы пишете код, вы можете легко получить результаты, просто получив текст от группы. Если у вас есть текстовый редактор, такой как notepad++ или код Visual Studio, вы можете использовать группы для замены текста, например, с помощью шаблона, где $ + цифра — это номер группы
“$1 | $2 | $2”
(Эти редакторы не видят названия групп, поэтому первая группа будет называться $1, вторая $2 и т. д.)

Как видите, код Visual Studio правильно нашел наши тексты, поэтому, когда я поставил шаблон замены для замены поля

Текст будет изменен на
