"Машинное обучение"
3 ключевых варианта линейной регрессии
Первая прогностическая модель, построенная в любом проекте, обычно является регрессионной. Мать всех «моделей белого ящика», линейная регрессия обеспечивает простую реализацию и интерпретацию. Нам ясно видеть, какие переменные оказывают большое влияние на нашу цель, и мы также можем использовать статистические тесты для проверки значимости этих коэффициентов. Следуя принципу Бритвы Оккама, согласно которому «сущности не следует умножать без необходимости»[1], имеет логический смысл усложнять наши модели.
Есть 3 метода линейной регрессии, которые важно иметь в нашем наборе инструментов для анализа. Эта статья призвана подробно рассмотреть их все, от их методологии и дизайна до того, насколько они уникальны и эффективны.
Обычный метод наименьших квадратов (OLS)
Модель обычных наименьших квадратов или OLS является фундаментальным методом линейной регрессии и обычно описывается или упоминается, когда в документе или проекте упоминается проведение регрессии. Функция sklearn LinearRegression() по умолчанию вызывает модель OLS, как и функция R lm().
Модель OLS направлена на поиск линейной оценки, которая минимизирует сумму квадратов остатков, вычисленных как евклидово расстояние между точкой данных и оценкой. Это показано на графике в двухмерном режиме ниже.
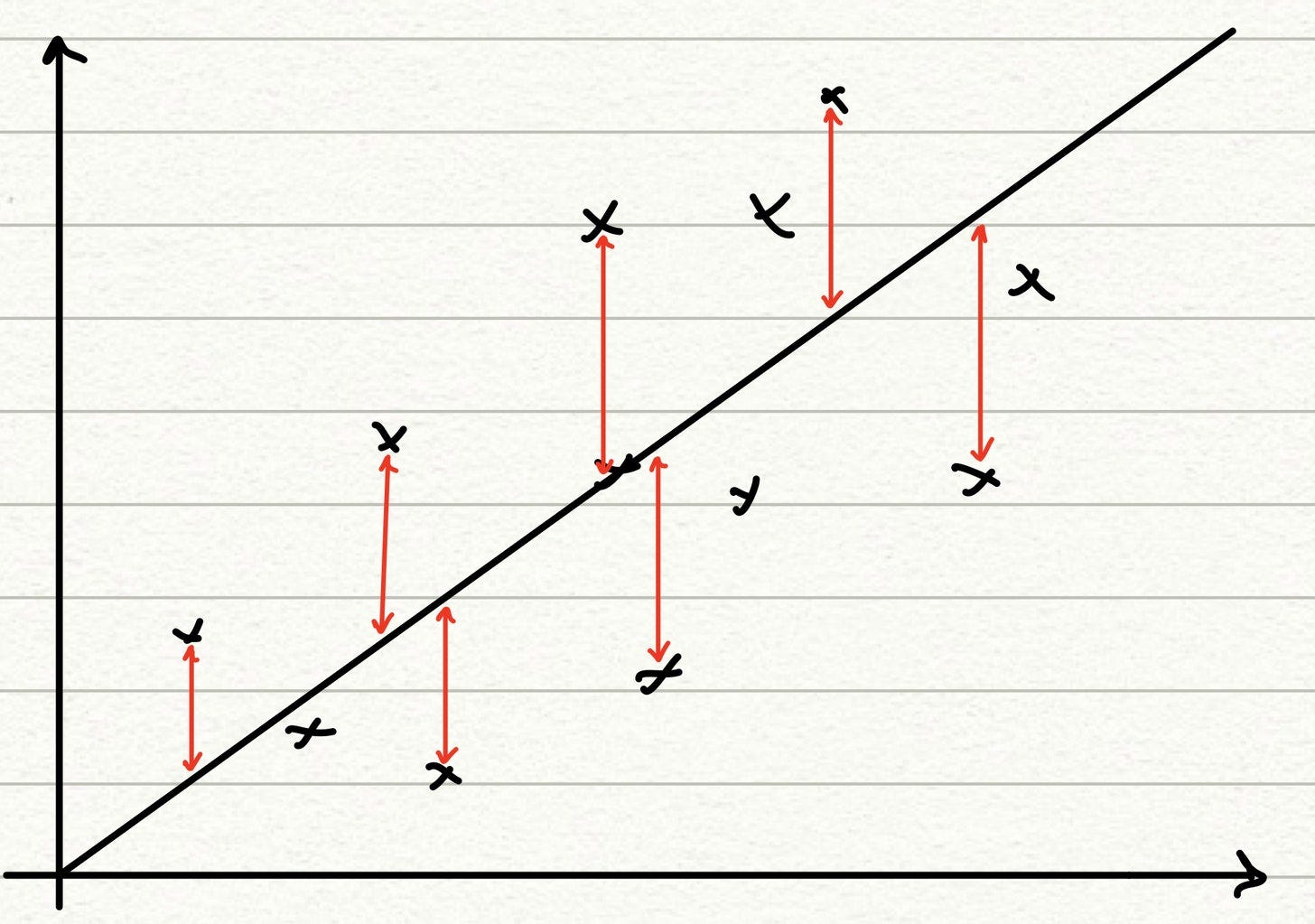
В более многомерной настройке эта линия преобразуется в гиперплоскость с размерностью = D-1, где D — размерность точек данных (количество независимых переменных).
Математически метод OLS рассчитывается как следующая функция, которая представляет собой формулу суммы квадратов остатков.
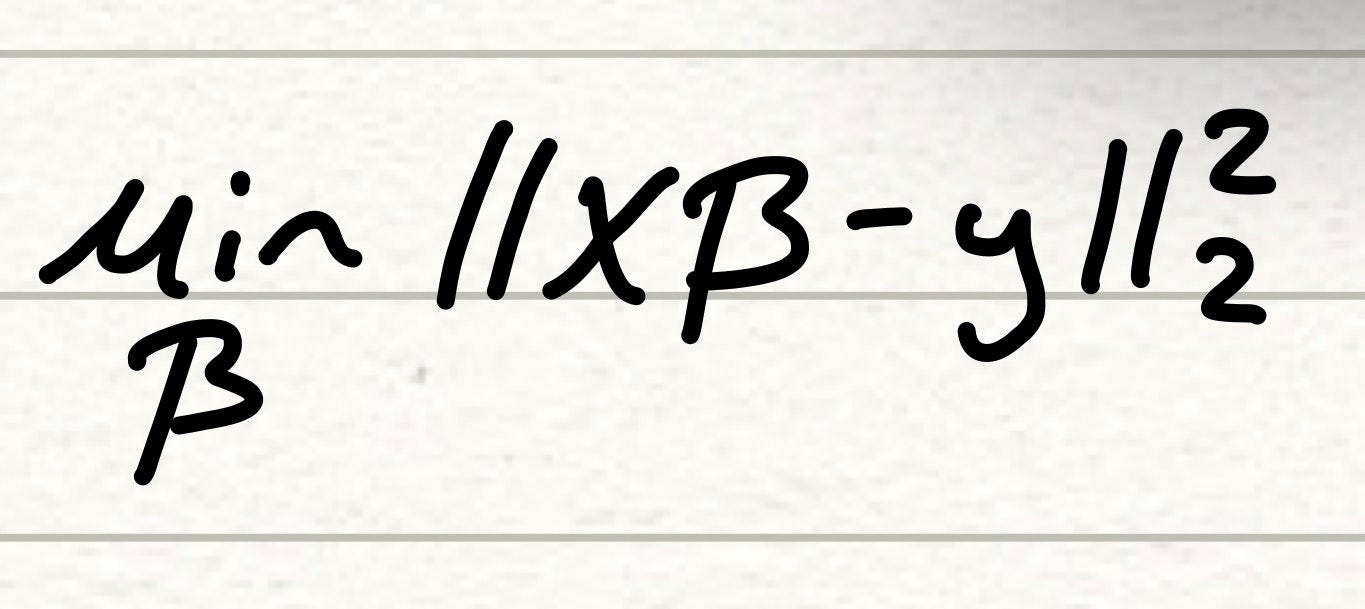
Решение для метода OLS можно рассчитать в близкой форме, и это делается путем расширения приведенной выше формулы, дифференцирования и вычисления бета после установки дифференциала равным 0, поскольку мы знаем, что сумма квадрата функции остатков является выпуклой.
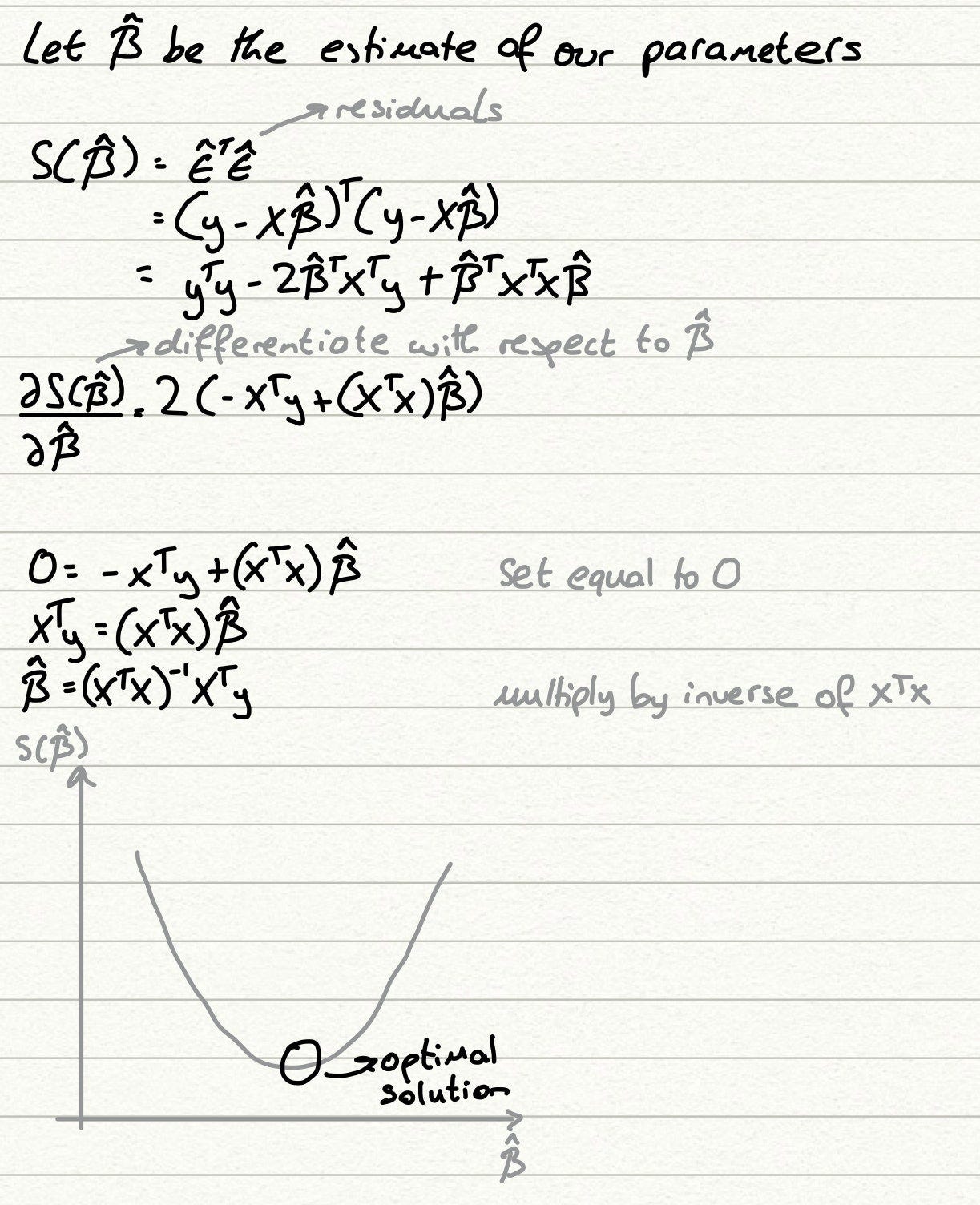
Так как же все это перевести в применимый сценарий? Что ж, тот факт, что наше решение имеет закрытую форму (по сути, это означает, что оно может быть точно рассчитано, и нам не требуются какие-либо численные методы для оценки решения), означает, что производительность, как правило, довольно быстрая и интерпретируемая. Регрессии называются «моделями белого ящика» из-за того, что мы можем видеть все расчеты, которые они делают, чтобы прийти к решению, и приведенное выше доказательство показывает это. Эта прозрачность вычислений также отражается в выходных данных, где обычно, в дополнение к нашей стандартной величине ошибки, регрессия предоставляет нам значения коэффициентов (значения beta_hat) и p-значения для проверки значимости этих значений. Это помогает нам легко определить переменные, которые являются ключевыми предикторами нашей цели, и сразу же предложить новое исследование, которое мы можем провести, чтобы понять, почему одни переменные очень влиятельны, а другие нет.
Ридж-регрессия
Ридж-регрессия — это первый из двух методов сокращения, которые мы рассматриваем в этой статье, и он назван так потому, что цель этой модели — уменьшить оценки наших коэффициентов до нуля. Преимущество метода это то, что мы создаем более простые и разреженные модели (с меньшим количеством параметров), и это полезно, потому что помогает нам действительно изолировать важные переменные и отбрасывать те, которые не помогают в наших исследованиях.
Способ, которым эти два метода сокращения достигают этого, заключается в добавлении дополнительного штрафного члена к расчету функции потерь. Поиск наименьшего убытка теперь представляет собой баланс между близостью оценки к целевому значению и размером каждого соответствующего коэффициента. Коэффициенты, которые не вносят пропорционального вклада в уменьшение потерь МНК по сравнению с их размером, начинают уменьшаться до 0, поскольку их размер не может быть оправдан моделью. Это поведение можно резюмировать в новой функции потерь ниже.

Дополнительным преимуществом этой «изоляции» ключевых переменных является то, что методы усадки, как правило, работают немного лучше, чем стандартная модель OLS. Их точность на обучающих данных обычно ниже из-за добавления параметра штрафа, но приоритетом для нас при оценке любых моделей, которые мы построили, является их способность обобщать, и как гребень, так и лассо, как правило, делают это довольно хорошо. В более простых моделях легче избежать переобучения, и это помогает обобщать невидимые данные.
Вы также заметите, что в нашем штрафном сроке есть лямбда-переменная. Это называется параметром настройки и, по сути, определяет, как распределяется этот баланс между потерей и штрафом. Когда лямбда = 0, наша модель будет вести себя точно так же, как предыдущий метод МНК, и слишком маленькое значение лямбда приведет к слишком сложной модели, которая может перекрыть наши данные. Слишком высокое значение лямбда, и наша модель будет сосредоточена исключительно на штрафном члене, а все переменные сократятся до 0, что повлияет как на производительность модели, так и на нашу интерпретацию предсказуемости объясняющих переменных. Поэтому выбор хорошего значения лямбда имеет решающее значение.
Лассо-регрессия
Лассо — это не столько строгая регрессия, сколько инструмент выбора признаков, который можно применять к различным методам регрессии, включая МНК и логистическую регрессию. Формально модель лассо очень похожа на модель хребта, но с одним ключевым отличием — › вместо вычисления квадрата значения наших параметров в штрафном члене лассо использует абсолютное значение коэффициентов.
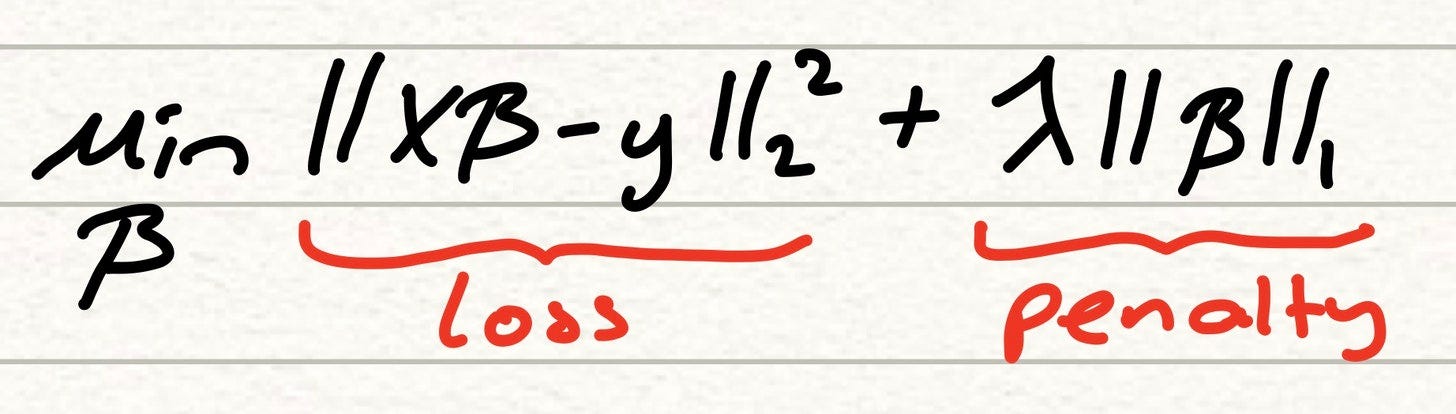
Разница в поведении между регрессией лассо и регрессией гребня заключается в том, что, хотя коэффициенты гребня имеют тенденцию уменьшаться к 0, в лассо эти коэффициенты становятся точно равными 0. Мы подробно расскажем, как это происходит, в следующей статье, но главное преимущество этого заключается в том, что мы теперь можно использовать лассо как форму точного выбора функций. Переменные, коэффициенты которых точно равны 0, могут быть немедленно исключены из модели, поскольку они не обеспечивают никакой предсказательной способности в отношении цели. Это помогает нам очистить нашу модель и сосредоточиться на переменных, которые имеют четкую связь.