Увеличьте скорость вашей системы

Заметили, что ваше приложение замедляется, когда вы получаете больше данных в своей системе? Ты не один. Хотя мы все слышали предупреждения о преждевременной оптимизации, в какой-то момент вам нужно будет потратить некоторое время на разработку того, как улучшить производительность вашей системы.
Недавно мы столкнулись с такой ситуацией в Sky Ledge. Простой запрос на получение данных временного ряда занял 30 секунд в нашей промежуточной среде. Это были простые запросы с индексами по интересующим столбцам. Мы ожидаем, что запросы будут выполняться за ‹1 секунду, а не за 30 секунд.
Мы гордимся хорошим пользовательским опытом. Ожидание рендеринга графика в течение 30 секунд приводит к очень плохому UX, поэтому настало время для поиска и оптимизации базы данных.
Проблема
Контекст
Sky Ledge — это платформа, которая помогает пользователям быстро создавать опыт диспетчерской, чтобы получить представление о своих операциях.
Одной из основополагающих частей Sky Ledge является наш Asset API, который позволяет очень легко отслеживать и визуализировать данные об объектах в реальном мире. Активы — это объекты в Sky Ledge, которые представляют собой объекты реального мира (например, транспортное средство). Метрики — это потоки данных, связанные с активом. Примерами метрик являются скорость, высота над уровнем моря, температура и т. д. Каждая метрика отслеживает отдельное значение объекта с соответствующей отметкой времени.
Наша база данных метрик выглядит следующим образом (мы используем AWS RDS, работающий с Postgres):
create table asset_metric ( asset_id. uuid not null, metric_name text, timestamp timestamptz, value double precision );
У нас также есть индекс в таблице asset_metric:
create index on asset_metric (timestamp, asset_id, name);
Проблема
Проблема возникла, когда я создавал демонстрацию для клиента в нашей тестовой среде. В рамках демонстрации я отобразил данные о температуре из актива на платформе Sky Ledge.
Чтобы получить данные о температуре, мы делаем следующий запрос к базе данных:
select * from asset_metric where asset_id = 'abc123' and metric_name = 'speed' order by timestamp desc limit 1000;
Этот запрос постоянно выполнялся более 30 секунд. Это простой запрос, и я знал, что у нас есть индекс для этой таблицы. Причина не сразу обнаружилась.
Расследование
Подключение к базе данных
Первым шагом было подключение к базе данных. Мы очень серьезно относимся к безопасности, поэтому наши промежуточные и рабочие базы данных заблокированы в частном облаке VPC на AWS без доступа к общедоступному Интернету.
Я настроил окно перехода SSH для подключения к промежуточной базе данных. Подробнее см. здесь о том, как это сделать (я бы не рекомендовал этот подход для производственной БД).
Как выглядят наши данные?
Затем я хотел выяснить, может ли распространение данных способствовать возникновению проблемы. У нас были другие демо на стадии подготовки, которые работали без проблем, поэтому замедление было ограничено определенными активами.
В базе данных asset_metrics 7 000 000 строк. Хотя он и не крошечный, я ожидаю лучшей производительности, чем то, что мы видим. 7 миллионов строк распределены между 106 различными активами. Также имеется 710 пар актив/метрика (скорость, температура, высота над уровнем моря и т. д.).
Rows: 7,050,951 Unique assets: 106 Asset / metric pairs: 710
Затем я выполнил пару запросов, чтобы понять распределение данных. 84% данных связаны всего с десятью активами в нашей промежуточной среде. Набор данных очень сильно искажен.


Тестирование различных пар активов/метрик
Вместо того, чтобы тестировать запрос на одной паре актив/метрика, я составил список из 9 пар актив/метрика. Это дало бы хорошее представление о производительности по всем направлениям. Это:
+-------+-------------+--------+ | Asset | Metric | Rows | +-------+-------------+--------+ | 1 | speed | 169000 | | 2 | speed | 100000 | | 3 | speed | 75000 | | 4 | speed | 20000 | | 5 | speed | 10000 | | 6 | speed | 5000 | | 7 | speed | 2000 | | 8 | temperature | 700 | | 9 | speed | 400 | +-------+-------------+--------+
У нас есть хороший разброс от метрик, которые обновляются очень часто, до тех, которые обновляются очень редко. Это поможет сообщить, возникает ли проблема повсеместно или только в определенных обстоятельствах.
Как я измерял производительность запросов
Поскольку я подключаюсь к базе данных через окно перехода, сетевые задержки могут повлиять на время выполнения запроса туда и обратно. Вместо этого я использовал explain analyse для измерения времени, которое потребовалось БД для выполнения запроса. Это позволило мне измерять производительность непосредственно в базе данных, не беспокоясь о изменчивости сети.
Полученные результаты
Текущий запрос
Я выполнил запросы по каждой из девяти пар актив/метрика, чтобы получить базовый уровень.

Результаты меня удивили. В 8 из 9 случаев планировщик запросов использовал обратное сканирование индекса. Я предполагал, что это будет последовательное сканирование из-за потраченного времени. Интуиция — это здорово, но стоит подтвердить свою интуицию. Вместо того, чтобы тратить время на то, чтобы разобраться, почему индекс не использовался, теперь я знал, что проблема заключалась в производительности индекса.
Единственный раз, когда он использовал последовательное сканирование, был для метрики температуры. Показатели скорости на порядки больше, чем показатели температуры, так что, вероятно, причина в этом.
Он уже использует сканирование индекса, а сканирование индекса является быстрым™, так почему же медленные результаты для всех метрик, кроме наиболее частых?
Отмена реверсирования индекса
Первое наблюдение состоит в том, что база данных выполняла сканирование индекса в обратном направлении. Обратное сканирование может быть медленнее, чем стандартное сканирование индекса для многоколоночных индексов (что у нас и есть).
Учитывая, что мы почти всегда запрашиваем последние данные (с order by timestamp desc ), кажется логичным упорядочить наш индекс с отметкой времени по убыванию. Итак, я создал новый индекс:
create index on asset_metric(timestamp desc, asset_id, metric_name)и повторил запросы.

Никаких изменений для показателя температуры (все еще последовательное сканирование), но прогресс во всем остальном! Мы существенно улучшили производительность запросов для других медленных пар актив/метрика, перейдя на прямое сканирование индекса…
…но все равно ужасно. Четыре секунды лучше, чем 25 секунд, но все же слишком медленно для наших нужд. Мы все стремимся создавать отличные впечатления для наших клиентов, и необходимость ждать секунды, пока загрузится простой график, не такова.
Упрощение индекса
Может быть, индекс слишком сложен и вызывает проблемы для планировщика запросов? Я проверил это предположение, создав новый индекс, используя только имя метрики и идентификатор актива:
create index on asset_metric (metric_name, asset_id)Я подумал, что это упростит поиск соответствующих данных для каждой пары актив/метрика.

И действительно, результаты выглядели великолепно! Мы сократили время с 4 секунд до менее десяти миллисекунд, улучшение в 400 раз!
За исключением одной пары актив/метрика, которой по-прежнему требовалось 11 секунд для возврата запроса. Я запускал запрос несколько раз, чтобы убедиться, что это не странная причуда, но он постоянно занимал более 10 секунд.
Планировщик запросов по-прежнему использовал исходный индекс для более частых пар актив/метрика (к этому моменту я удалил нереверсированный индекс, чтобы тестировать только одну переменную за раз).
Это не относится к менее частым парам. Здесь он использовал сканирование растрового индекса и объединил как исходный индекс, так и новый индекс.
Есть ли способ устранить этот раздражающий пограничный случай и добиться отличной производительности по всем направлениям?
Улучшенный индекс — изменение порядка столбцов
Предыдущий индекс дал важную подсказку — было выгодно искать по идентификатору актива и названию метрики для менее частых пар.
Имеет ли значение порядок столбцов для многостолбцовых индексов? Оно делает.
Каноническим примером является телефонная книга. Так же, как телефонная книга сортируется сначала по фамилии, а затем по имени. Многоколоночные индексы сортируются по первому столбцу, второму столбцу, третьему столбцу и т. д.
Точно так же, как вы не можете искать кого-либо только по имени в телефонной книге, вы также не можете использовать многоколоночный индекс для поиска строки по второму или третьему столбцу.
Мы всегда ищем данные метрик, учитывая идентификатор актива и имя метрики; кажется логичным, что это должны быть первые столбцы в индексе. Я создал следующий индекс:
create index on asset_metric (metric_name, asset_id, timestamp desc)Здесь мы оба меняем порядок столбцов, чтобы обеспечить сортировку индекса по metric_name и asset_id. Мы также меняем timestamp на убывание, как и в наших предыдущих результатах. Давайте посмотрим, как это работает:
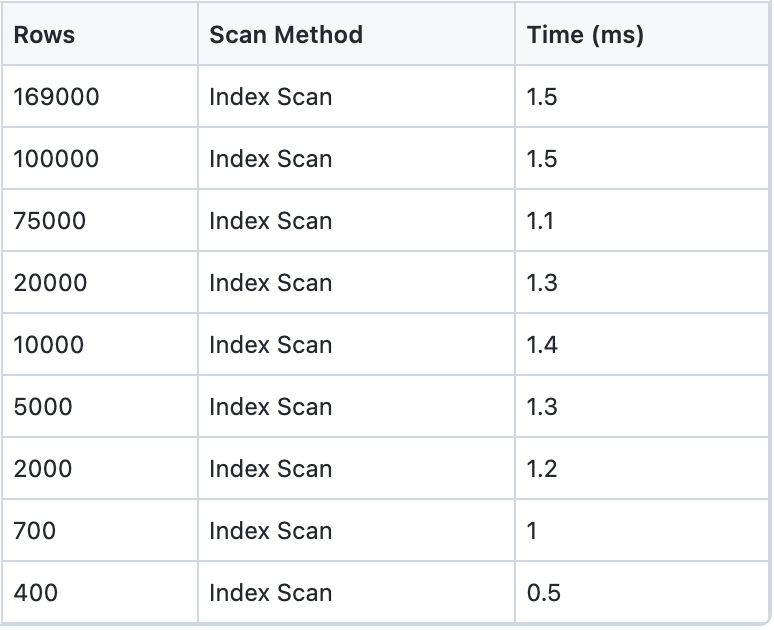
Хороший! Отличная производительность по всем направлениям. Все запросы выполнялись последовательно менее чем за две миллисекунды.
Заключение
Нам удалось улучшить наши запросы в 15 000 раз в худшем случае! В шагах, которые мы предприняли выше, нет ничего революционного. Это типичный пример оптимизации БД, которую вы должны выполнять в реальном мире. Современные базы данных могут обрабатывать невероятные объемы данных.
Базовое понимание того, как работают базы данных, может изменить мир. Вместо того, чтобы задыхаться от 7 миллионов строк, наша таблица теперь должна иметь возможность масштабироваться до сотен миллионов строк для этого варианта использования. На то, чтобы найти узкое место и устранить его, у меня ушло не более 2 часов. Все, что потребовалось, это простая настройка нашего индекса.