МНЕНИЕ
Не используйте умножение списка Python ([n] * N)
Это ловушка

Независимо от того, являетесь ли вы новичком или опытным программистом на Python, скорее всего, вы либо использовали умножение списков, либо читали об этом в статьях в стиле «классные функции Python».
Это потому, что это, несомненно, одна из тех замечательных функций, разработанных для облегчения вашей жизни с Python.
Преимущество умножения списка в том, что оно абстрагирует процесс инициализации списка.
Вместо использования итеративного подхода или понимания списка:
# Iterative approach
my_list = []
for _ in range(N):
my_list.append(n)
# List comprehension
my_list = [n for _in range(N)]
вы можете получить тот же результат с помощью:
my_list = [n] * N
Видите ли, я изучал языки программирования в следующем порядке:
C -> C++ -> MATLAB -> R -> Python.
Ни один другой язык программирования, с которым я работал до Python, не мог даже отдаленно обеспечить такую лаконичность и интуитивность.
Однако по мере того, как я начинал писать все более и более сложный код, умножение списков начало действовать мне на нервы.
Я помню, как однажды я потратил целый день на отладку кода только для того, чтобы выяснить, что проблема возникла из-за неправильного создания списка с использованием оператора *.
В результате я считаю необходимым обсудить этот вопрос, поскольку я точно знаю, что некоторые разработчики до сих пор не обращают внимания на компромиссы, связанные со звездным оператором, когда дело доходит до создания списка.
Что не так с умножением списка
Рассмотрим следующий код:
>>> my_list = [0] * 3 >>> my_list[0] = 1 >>> my_list [1, 0, 0]
Это то, что вы ожидаете. Все идет нормально.
Теперь давайте попробуем создать 2D-массив, используя тот же подход:
>>> my_list = [[0] * 3] * 5 >>> my_list[0][0] = 1 >>> my_list [[1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0]]
Хм! Это, вероятно, не то, что вы хотели бы.
Как насчет того, чтобы продвинуть его дальше, инициализировав 3D-массив:
>>> my_list = [[[0] * 3] * 5] * 2 >>> my_list[0][0][0] = 1 >>> my_list [[[1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0]], [[1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0], [1, 0, 0]]]
Ожидаемым результатом будет обновление первого значения подсписка [0, 0, 0]. Однако похоже, что обновление было реплицировано во всех подсписках.
Итак, почему это произошло?
Как работает умножение списков?
Чтобы понять предыдущее поведение, стоит вернуться к FAQ Python, в котором говорится:
«Причина в том, что репликация списка с помощью
*не создает копии, а создает только ссылки на существующие объекты».
Давайте переведем это в код, чтобы еще лучше понять, как Python работает под капотом:
- Умножение списка:
my_list = [[0] * 5] * 5
for i in range(5):
print(id(my_list[i]))
Выход:
2743091947456 2743091947456 2743091947456 2743091947456 2743091947456
- Использование циклов for
my_list = []
for _ in range(5):
my_list.append([0] * 5)
for i in range(5):
print(id(my_list[i]))
print(my_list)
Выход:
2743091947456 2743095534208 2743095532416 2743095534336 2743095532288
- Интерпретация
В отличие от цикла for, все списки, скопированные через оператор *, указывают на один и тот же адрес памяти. Это означает, что любое изменение, влияющее на один вложенный список, влияет на все остальные, что явно противоречит нашему первоначальному замыслу.
Теперь возникает вопрос:
- Почему первый пример
([n] * N)работает просто отлично, хотя все элементы списка ссылаются на один и тот же объект?
Оказывается, причина такого поведения (как указано в викибуке Python) заключается в том, что списки — изменяемые элементы, а int, str и им подобные — неизменяемые. Проверьте это:
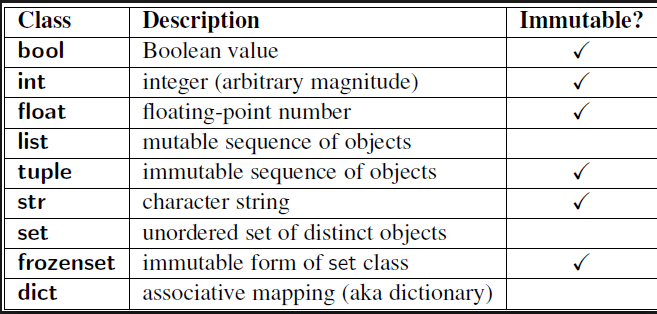
А поскольку неизменяемые объекты нельзя изменить, Python создает новую (другую) ссылку на объект при обновлении элемента в списке.
>>> my_list = [0] * 3 >>> id(my_list[0]) 1271862264016 >>> my_list[0] = 1 >>> id(my_list[0]) 1271862264048
Обходной путь
Быстрое и простое решение этой проблемы — использование понимания списка. Это, конечно, помимо стандартного цикла for.
>>> my_list = [[0] * 3 for _ in range(5)] >>> my_list[0][0] = 1 >>> my_list [[1, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
Кроме того, мы видим, что каждому списку был выделен свой адрес памяти.
>>> my_list = [[0] * 3 for _ in range(5)] >>> [id(l) for l in my_list] [1271867906112, 1271864321536, 1271864322048, 1271864326912, 1271864322560]
Что еще более важно, этот подход отлично работает во всех сценариях.
Итак, почему бы вам не придерживаться этого и не рисковать, вместо того, чтобы дважды подумать, прежде чем использовать умножение списка?
Заключение
Я не большой фанат синтаксического сахара Pythonic.
Да, я согласен, что это делает код компактным и лаконичным.
Однако когда conciseness == readability работал в индустрии программного обеспечения?
На самом деле, чем больше я программирую на Python, тем больше я склоняюсь к использованию стандартного синтаксиса Python и отказу от сокращений.
В конце концов, важны производительность, удобство сопровождения и удобочитаемость. Не то, сколько строк кода у вас есть.
И если вы не можете обойтись без сокращений, по крайней мере, прочитайте, что хорошего, что плохого, что уродливого в синтаксическом сахаре, который вы используете. В этом случае может потребоваться умеренное понимание концепций разработки программного обеспечения (например, структур данных, распределения памяти и т. д.).
Удачного кодирования!
Если вы сочтете это полезным, подумайте о том, чтобы стать премиум-участником. Если вы воспользуетесь этой ссылкой, я получу небольшую долю.