Мы изучаем различные методы машинного обучения для достижения цели классификации патологического голоса и предлагаем использовать модель глубокого обучения под названием RawNet. Это был проект Gabriel Ng во время его стажировки в Digital Hub; курирует Джакс.

С тех пор, как началась пандемия COVID-19, значение классификации патологического голоса резко возросло, и многие страны и больницы изо всех сил пытаются найти эффективные средства тестирования своих людей. Учитывая потребность в специализированном оборудовании и квалифицированном персонале для надлежащего проведения теста на мазок на COVID-19, неудивительно, что организации ищут другие средства тестирования. Потенциально более эффективным методом может быть использование машинного обучения для классификации патологических голосов из голосовых записей. При таком тестировании можно будет диагностировать людей в режиме реального времени, экономя на рабочей силе. Даже если такое тестирование само по себе не может служить в качестве диагноза, его можно использовать для снижения частоты ложноположительных и отрицательных результатов истинного теста. В этом проекте исследуются различные методы машинного обучения для достижения цели классификации патологического голоса и предлагается использование модели глубокого обучения под названием RawNet.
Этот пост будет охватывать следующее содержание:
- Обзор литературы по текущим исследованиям
- Доступны наборы патологических голосовых данных
- Базовая модель для сравнительного анализа
- Модель глубокого обучения RawNet
- Будущая работа
- Приложение
Ссылки на текущие исследования, наборы данных и данные, используемые в этом проекте, будут включены в приложение.
Литературный обзор
Хотя машинное обучение в аудио менее развито, чем такие области, как компьютерное зрение в области патологии, все еще существует множество исследований патологической классификации голоса, из которых можно извлечь уроки. Это исследование можно разделить на две основные части; классификация с ручными функциями и классификация с глубоко изученными функциями.
Особенности ручной работы
Элементы ручной работы можно разделить на две категории; акустические характеристики и спектральные характеристики. Акустические характеристики представляют собой характеристики системы человеческого слуха и системы воспроизведения речи, а спектральные характеристики представляют собой характеристики записи голоса в звуковом спектре. Чтобы проиллюстрировать эту разницу, сравниваются акустическая и спектральная характеристики. Примером акустической характеристики являются кепстральные коэффициенты Mel-частоты (MFCC), которые представляют собой краткосрочный спектр мощности звука на нелинейной шкале мел-аудио. Поскольку звуковая шкала мела аппроксимирует слуховую реакцию человека на звук, MFCC представляют собой представление того, как люди будут воспринимать звук. С другой стороны, спектральная энергия — это представление того, как энергия звука распределяется на разных частотах, истинное представление характеристик звука. Другими примерами ручной работы являются:
- Отношение гармоник к шуму
- Джиттер и мерцание
- Спектральная энтропия
- Энергия
- Основная частота
Некоторые из этих функций используются при создании базовой модели и будут объяснены более подробно позже.
Глубоко изученные функции
Глубоко изученные функции — это функции, извлеченные из аудиозаписей с помощью глубокой нейронной сети (ГНС). Недавнее исследование экспериментировало с этим подходом, поскольку глубоко изученные функции могут быть лучшим представлением голоса человека по сравнению с функциями, созданными вручную. Нет никакой гарантии, что созданная вручную функция является хорошим различителем патологических голосов, в то время как глубоко изученные функции специально извлекаются DNN для различения различных голосовых нарушений. Помимо RawNet, существуют и другие модели глубокого обучения с открытым исходным кодом для извлечения глубоко изученных функций. Это X-векторные DNN и предварительно обученные аудионейронные сети (PANN).
Наборы данных
Существует ряд доступных наборов данных о патологическом голосе с открытым исходным кодом. Эти наборы данных представляют собой базу данных голосов Saarbruecken (SVD), базу данных VOICED и базу данных SLI. Другие базы данных, такие как база данных Massachusetts Eye and Ear Infirmary Database и базы данных патологии TalkBank, к сожалению, не имеют открытого исходного кода. В этом проекте используемые данные получены из SVD, поскольку данные поступают в файлах .wav, что упрощает начало экспериментов с данными. В целом, для этого проекта были загружены и использованы все образцы с 6 различных ярлыков заболеваний. В рамках этих 6 расстройств данные были разделены на разные демографические группы, разделенные по полу и возрастной группе. Есть два пола, мужской и женский. Есть три возрастные группы: от 1 до 40, от 41 до 65 и от 66 лет и старше. Примером демографии является дисфония_женщина_1_40.
Эти данные можно скачать здесь: https://drive.google.com/file/d/1P6Pip3ZWzKfG74p0EuWwSguIsOyAUFD_/view?usp=sharing
- Дисфония
- Функциональная дисфония
- Гиперфункциональная дисфония
- Ларингит
- Рецидивирующий паралич
- Здоровый
Всего в наборе данных 17521 файл. Тем не менее, большинство этих файлов исходят от здоровых голосов (~ 8200 файлов), а некоторые демографические расстройства имеют менее 100 файлов. Таким образом, набор данных был обработан двумя разными способами. В обоих методах использовалось разделение 60–20–20 поездов-клапанов.
Во-первых, все файлы по одному и тому же голосовому расстройству (например, дисфонии) были сгруппированы вместе, независимо от возраста или пола. Это создало набор данных из ~ 5400 файлов с ~ 900 файлами для каждого нарушения голоса. Для разделения 60–20–20 это привело к обучающему набору из ~ 3240 файлов и 540 файлов для каждого нарушения голоса. Набор для проверки и оценки содержал примерно по 1080 файлов, по 180 файлов на каждое расстройство голоса.
Во-вторых, были выбраны 5 демографических данных с высоким уровнем данных с не менее чем 1000 высказываний (например,health_male_41_65) для просмотра эффектов, которые дополнительные данные могут иметь при моделировании. При разделении 60–20–20 получается обучающий набор из 3000 файлов и 600 файлов для каждой демографической группы. Набор для проверки и оценки состоял из 1000 файлов и 200 файлов для каждого нарушения голоса. Количество данных для каждой из этих 5 демографических групп ненамного превышает количество данных для каждого расстройства в первом распределении. Однако в относительном отношении по каждой демографической группе имеется гораздо большее количество данных, поскольку каждое расстройство в первом распределении содержало 6 различных демографических характеристик.
Базовая модель
Прежде чем экспериментировать с RawNet, была создана базовая модель, чтобы определить, насколько сложно будет классифицировать патологические голоса с ручными функциями. Прежде чем извлекать эти созданные вручную функции из голосовых записей, Auditok использовался для извлечения отдельных высказываний из общих записей набора данных SVD. Примером одного высказывания является «ооо» или «ааа», и они были извлечены в свои собственные файлы .wav, поскольку каждая исходная запись голоса содержала несколько высказываний с паузами между ними, что могло повлиять на значения извлеченных признаков.
Затем openSMILE использовался для извлечения из каждого высказывания созданных вручную функций, приведенных ниже.
- MFCC (объяснено ранее)
- Спектральная энергия (объяснено ранее)
- Джиттер и Шиммер. Эти две особенности представляют нестабильность частоты и нестабильность амплитуды звука соответственно.
- Отношение гармоник к шуму — это отношение энергии периодического сигнала звука к энергии шума звука.
Исходные результаты
Затем созданные вручную признаки использовались для предсказания того, к какому ярлыку расстройства принадлежало высказывание.
- Мультиклассовая классификация (6 классов нарушений): ~0,22 балла F1
- Многоклассовая классификация (5 демографических данных с высоким уровнем данных): ~ 0,31 балла F1.
- 1 vs 1 классификация классов расстройств: ~0,55 балла F1
5 демографических данных с высоким уровнем данных в этом результате — это 5 демографических групп, которые имели наибольшее количество отдельных высказываний после обработки данных около 1000 высказываний. Например,health_male_41_65 — это демографическая группа с таким количеством высказываний, что позволяет получить больше обучающих данных.
Исходные результаты показывают, что модель работает немногим лучше, чем случайное угадывание, какой ярлык расстройства следует присвоить неизвестному высказыванию. Это согласуется с несколькими моделями, такими как случайные леса, машины опорных векторов и XGBoost. Однако гиперпараметры моделей не настраивались, поэтому это может улучшить базовые результаты.
Глубоко изученные функции с RawNet
Чтобы улучшить базовые результаты, используется модель глубокого обучения под названием RawNet. Первоначальная цель RawNet заключалась в проверке динамиков с использованием необработанных аудиосигналов в качестве входных данных. Чтобы достичь своей цели проверки говорящего, исследователи использовали классификатор косинусного сходства в качестве последнего уровня RawNet. Этот классификатор указывал, насколько похожи друг на друга два вложения из разных записей. На рисунке ниже показаны входные и выходные данные модели, а также ее архитектура.
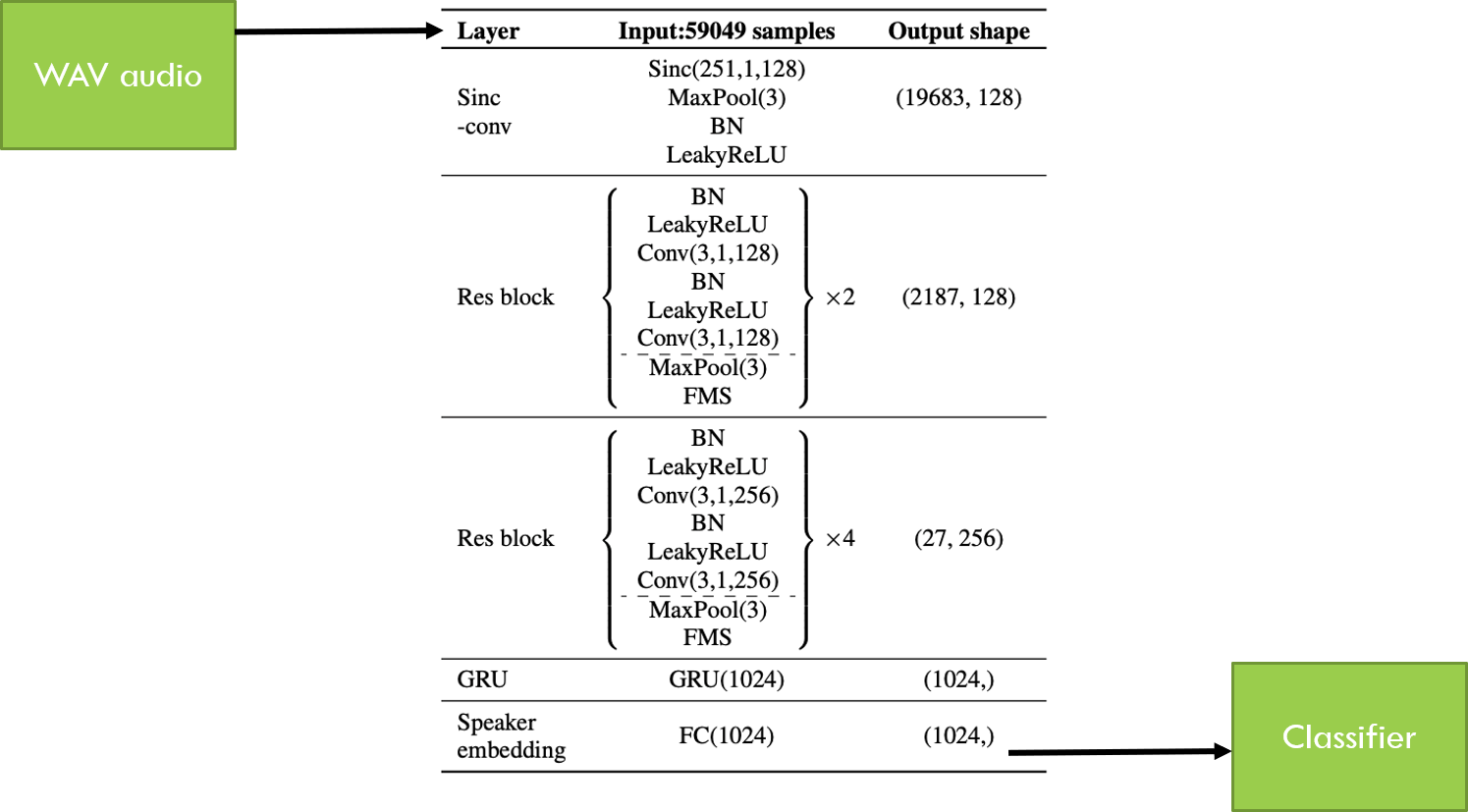
Этот проект адаптировал его для классификации патологического голоса, рассматривая каждую демографическую группу (например, мужчин, страдающих дисфонией, 41–65 лет) в качестве говорящих. Причина этого заключалась в том, что, согласно текущим исследованиям, разные демографические данные должны иметь отличные друг от друга характеристики, которые позволили бы RawNet различать разные демографические данные. Например, у мужчин тон ниже, чем у женщин, а у людей с нарушением голоса дрожание и мерцание выше, чем у здоровых людей.
Проверка производительности RawNet
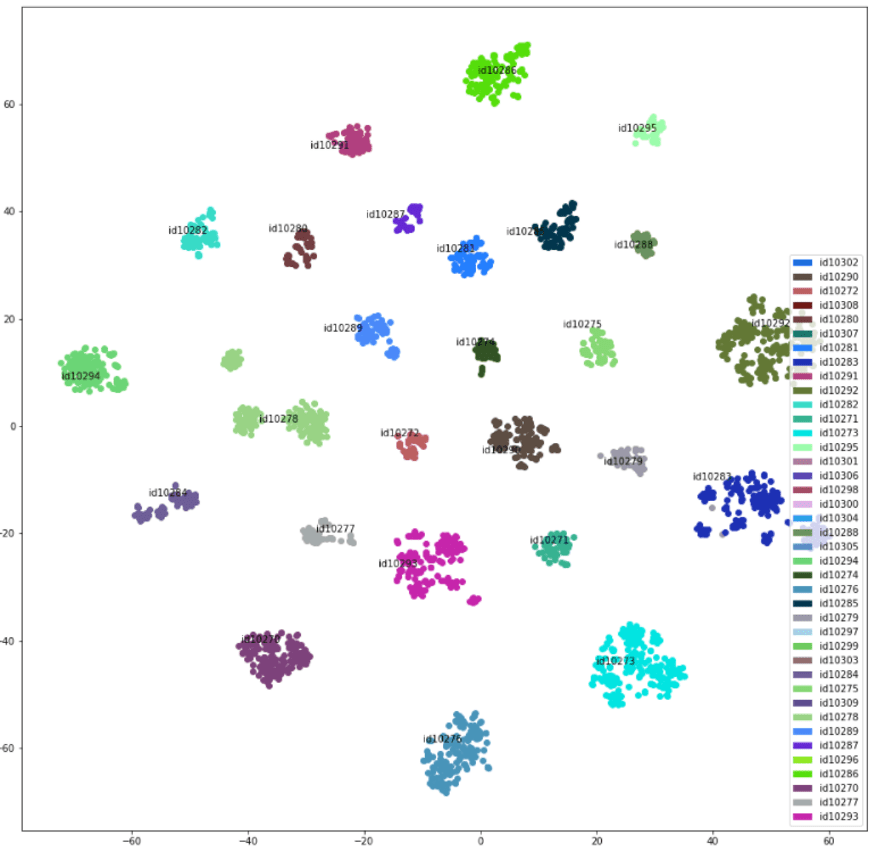
Прежде чем адаптировать RawNet для классификации патологических голосов, исходное исследование было проверено путем повторения исследования. Это было сделано путем обучения модели RawNet на voxCeleb, наборе данных записей выступлений знаменитостей. Из визуализации вложений, созданных из оценочных записей (невидимых моделью во время обучения) с помощью RawNet после обучения, видно, что все говорящие находятся в своих отдельных кластерах. Таким образом, можно сделать вывод, что первоначальное исследование действительно достигло своей цели.
Окончательные результаты
Классификация с помощью модели RawNet проводилась с использованием тех же сценариев, что и базовый уровень, в котором использовался набор данных SVD, упомянутый в разделе «Наборы данных».
- Мультиклассовая классификация (6 классов расстройств): ~0,26 балла F1.
- Мультиклассовая классификация (5 демографических данных с высоким уровнем данных): ~ 0,46 балла F1.
- 1 vs 1 классификация классов расстройств: ~ 0,55–0,80 балла F1
Вторая ситуация с несколькими классами указывает на то, что, хотя производительность модели не подходит для развертывания в данный момент, при наличии достаточного количества данных модель потенциально может обнаружить хорошие дискриминаторы различных расстройств.
Кроме того, в рамках сценария классификации 1 на 1 наблюдалось несоответствие между F1-баллами классификаций здоровых и расстройств и расстройств и расстройств. Из этого можно сделать вывод, что характеристики здорового голоса, вероятно, более отличны от голосов с нарушением. Однако различение различных расстройств, вероятно, будет более сложной задачей, поскольку различные расстройства могут по-разному влиять на голос человека.
Визуализация вложений
Чтобы более подробно понять окончательные результаты, было создано несколько визуализаций вложений, полученных из данных оценки.
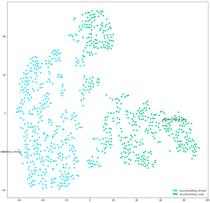
Визуализация расстройства
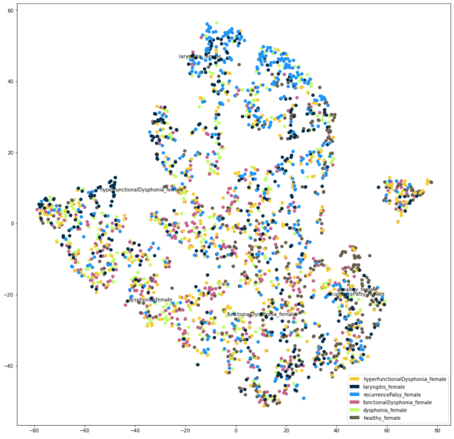
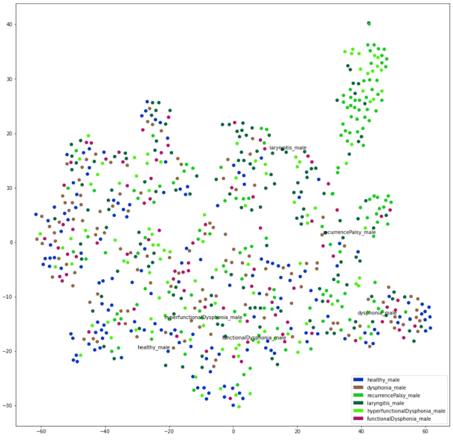
Два приведенных ниже графика TSNE показывают женское население (слева) и мужское население (справа), причем разные цвета точек указывают на разные расстройства. Ясно, что ни в одной из популяций не образуются отчетливые кластеры, что указывает на отсутствие различий между встраиваниями и нарушениями. Это подтверждает более раннюю гипотезу о том, что сложно найти хороший различитель между различными расстройствами.
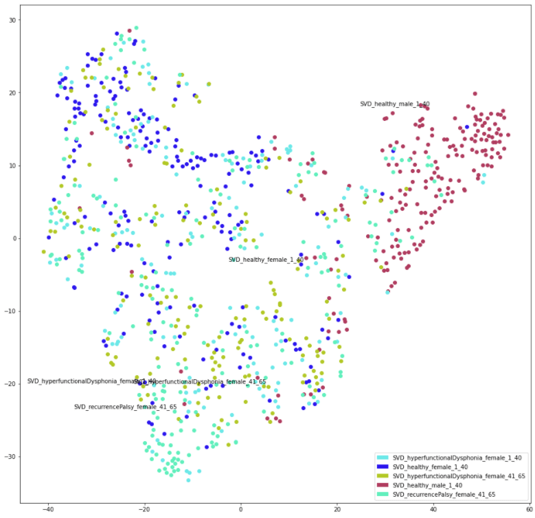
Демографические визуализации с большим объемом данных
Кроме того, приведенный ниже график TSNE, визуализирующий 5 демографических данных с высоким уровнем данных, показывает, что начинает происходить небольшая степень кластеризации, с большинством синих точек в левом верхнем углу, большинством красных в верхнем правом и несколькими светло-голубыми. внизу. Это также показывает, что при наличии достаточного количества данных RawNet может различать разные демографические данные, на которых он обучается.
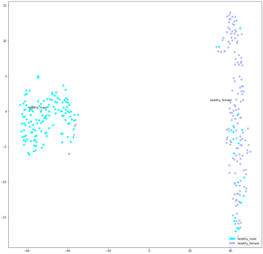
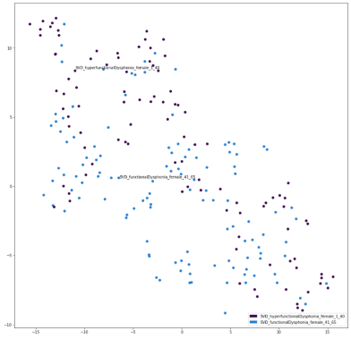
Гендерные визуализации
Кроме того, красные точки, представляющие здоровую мужскую демографическую группу, четко отделены от большинства других точек, относящихся к записям женского голоса, что указывает на то, что модель, возможно, может различать пол. Дальнейший анализ с несколькими визуализациями мужчин и женщин для каждого расстройства подтвердил эту гипотезу. Примеры этих визуализаций приведены ниже, где мужчины и женщины для здоровых людей показаны слева, а мужчины и женщины для людей с рецидивирующим параличом - справа.
Здоровое против расстройства, расстройство против расстройства визуализации
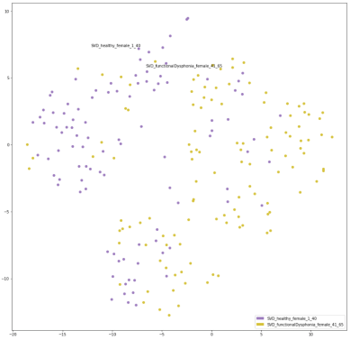
Наконец, визуализации вложений для сценариев «здоровье против расстройства» и «расстройство против расстройства» также подтверждают более ранние гипотезы о производительности модели RawNet. В приведенных ниже визуализациях TSNE на каждом рисунке показаны вложения из сценария здорового и расстройства, в частности, здорового и рецидивирующего паралича для мужчин и здорового и функциональной дисфонии для женщин. Различные расстройства отмечены разными цветами.
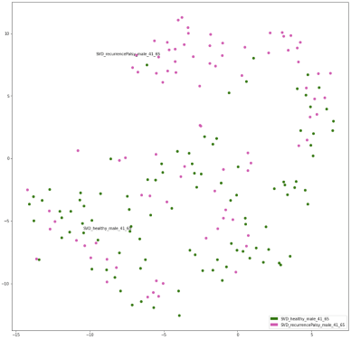
Вложения TSNE ниже показывают вложения из сценариев расстройства и расстройства, рецидивирующего паралича и ларингита для мужчин и функциональной дисфонии против гиперфункциональной дисфонии для женщин.
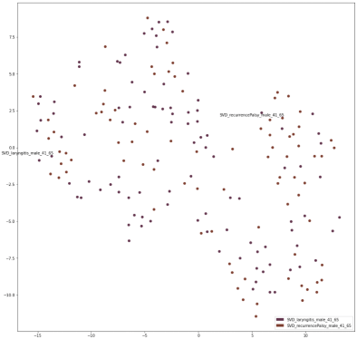
Из этих 4 визуализаций видно, что, хотя в сценариях «здоровые люди и расстройства» нет четких кластеров, точки все же более разделены, чем в сценарии расстройства и расстройства. В последнем точки распределены равномерно, что указывает на то, что RawNet не нашел эффективного дискриминатора для различения расстройств.
Краткое содержание
Таким образом, хотя модель SVD RawNet в ее текущем состоянии не может различать множественные расстройства, тем не менее, она способна различать определенные характеристики голоса. Например, он может легко отличить мужские голоса от женских, а также относительно хорошо отличает здоровые голоса от нездоровых. Чтобы продолжать улучшать его эффективность в распознавании расстройств, вероятно, потребуется больше данных.
Модель RawNet также показала лучшие результаты, чем базовая модель, что указывает на то, что глубоко изученные функции могут быть более эффективными дискриминаторами того, что представляет собой конкретное расстройство голоса, чем функции, созданные вручную. В таблице ниже указана разница в производительности.

Будущая работа
Работы еще много, несмотря на то, что этот проект завершен. Ниже перечислены некоторые дополнительные шаги, которые можно предпринять для продвижения этого проекта.
- Как упоминалось ранее, сбор дополнительных патологических голосовых данных для расширения текущего набора данных SVD, вероятно, значительно повысит производительность RawNet.
- Также следует провести эксперименты с другими классификаторами, такими как скрытые марковские модели и гауссовские смешанные модели, чтобы продолжать улучшать производительность обнаружения патологического голоса с помощью функций, созданных вручную.
- RawNet также следует сравнивать с другими моделями, которые создают функции глубокого изучения звука, такие как X-векторы и PANN.
Приложение
Ссылки на исследования
Исследование внутри и между базами данных для баз данных на арабском, английском и немецком языках: выявляют ли особенности обычной речи голосовую патологию https://www.sciencedirect.com/science/article/pii/S0892199716301837
Внешний факторный анализ для проверки выступающих; https://ieeexplore.ieee.org/document/5545402
Выявление отличительных акустических и спектральных особенностей при болезни Паркинсона; https://www.researchgate.net/publication/335829678_Identifying_Distinctive_Acoustic_and_Spectral_Features_in_Parkinson’s_Disease
Выявление нарушений голосовых связок с помощью методов распознавания образов; https://ieeexplore.ieee.org/document/4353023
Вложения глубокой нейронной сети для независимой от текста проверки говорящего; https://danielpovey.com/files/2017_interspeech_embeddings.pdf
X-Vectors: надежные вложения DNN для распознавания говорящих; https://www.danielpovey.com/files/2018_icassp_xvectors.pdf
Обнаружение патологической речи с использованием X-Vector Embeddings; https://www.researchgate.net/publication/339641784_Pathological_speech_detection_using_x-vector_embeddings
RawNet: расширенная сквозная глубокая нейронная сеть, использующая необработанные сигналы для независимой от текста проверки говорящего; https://www.researchgate.net/publication/335829649_RawNet_Advanced_End-to-End_Deep_Neural_Network_Using_Raw_Waveforms_for_Text-Independent_Speaker_Verification
openSMILE — универсальное и быстрое средство извлечения аудио с открытым исходным кодом в Мюнхене; https://www.researchgate.net/publication/224929655openSMILE–_The_Munich_Versatile_and_Fast_Open-Source_Audio_Feature_Extractor
Ссылки на наборы данных
- База данных голоса Саарбрюкена: http://stimmdb.coli.uni-saarland.de/index.php4#target
- База данных VOICED: https://physionet.org/content/voiced/1.0.0/
- SLI-база данных: https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-1597