«Настроения клиентов, зафиксированные в электронном виде — выражения, выходящие за рамки фактов, передающие настроение, мнение и эмоции, — имеют огромную ценность для бизнеса. Мы говорим о голосе клиента и потенциального клиента, пациента, избирателя и лидера мнений».
– Сет Граймс

Введение
TripAdvisor, крупнейший в мире сайт о путешествиях, является популярным веб-сайтом для поиска отелей, ресторанов, транспорта и мест для посещения. Всякий раз, когда кто-то планирует поездку в страну или город, он, скорее всего, зайдет на TripAdvisor, чтобы найти лучшие места для проживания и посещения. TripAdvisor содержит более 702 миллионов отзывов о ведущих отелях мира, перечисляет более 8 миллионов местоположений (гостиницы, рестораны, туристические достопримечательности) и занимает первое место в категории «Путешествия и туризм» в США.
Когда мы планируем отпуск или отпуск, мы хотим убедиться, что выбрали место и место для проживания по разумной цене, которое соответствует или превосходит наши потребности и ожидания. Один из способов, которым мы можем принять правильное решение о месте для проживания, — это посмотреть отзывы других людей, которые уже останавливались там. Если отзывы в целом положительные, мы можем быть уверены, что это, вероятно, хорошее место для отдыха. Когда отзывы смешаны с некоторыми положительными и многими отрицательными, мы, вероятно, не должны оставаться в этом месте.
Я подумал, что было бы интересно проанализировать настроения, связанные с конкретным отелем, и выяснить, какие мысли и/или эмоции людей были связаны с отелем. Анализ настроений — это распространенное применение обработки естественного языка (NLP), целью которого является анализ содержания текста и прогнозирование настроений, таких как отрицательное, нейтральное или положительное. Таким образом, анализ настроений можно рассматривать как метод количественной оценки качественных данных с некоторой оценкой настроений. В то время как настроения в значительной степени субъективны, количественная оценка настроений получила множество полезных применений, включая получение предприятиями понимания реакции потребителей на продукт или обнаружение ненавистнических высказываний в онлайн-разговорах.
Дорожная карта
В этой статье я представлю скрипт, который собирает отзывы об отеле с веб-страниц TripAdvisor, извлекает некоторые элементы данных и создает набор данных. Затем я проведу анализ настроений по отзывам. Отель, отзывы о котором мы анализируем, — Sheraton Maui Resort & Spa на Гавайях. Следующие шаги будут выполняться с использованием Python, Selenium и обработки естественного языка (NLP).
1. Импортируйте библиотеки.
2. Установите веб-драйвер.
3. Найдите и извлеките элементы данных.
4. Создайте фрейм данных.
5. Преобразуйте кадр данных в файл CSV.
6. Примените анализ настроений.
7. Визуализируйте чувства.
8. Выводы.
Программа
Для этого проекта я не буду подробно изучать обзоры отелей с веб-страниц TripAdvisor. Это было рассмотрено в одной из моих предыдущих статей под названием Скрапинг отелей TripAdvisor с помощью Python и Beautiful Soup. Вы можете просмотреть эту статью, нажав на эту ссылку.
Для начала вам необходимо установить пакеты Selenium.
Установите пакеты Selenium
!pip install selenium
Импортировать библиотеки
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import pandas as pd import time import csv
Определите URL-адрес TripAdvisor.
url = "https://www.tripadvisor.com/Hotel_Review-g60634-d114075-Reviews-or80-Sheraton_Maui_Resort_Spa-Lahaina_Maui_Hawaii.html"
Установите веб-драйвер
# Install the chrome web driver from selenium.
!apt-get update
!apt install chromium-chromedriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
Веб-драйвер является ключевым компонентом селена. Веб-драйвер — это платформа автоматизации браузера, которая работает с API с открытым исходным кодом. Платформа работает, принимая команды, отправляя эти команды в браузер и взаимодействуя с приложениями.
Selenium поддерживает несколько веб-браузеров и предлагает веб-драйверы для каждого браузера. Я импортировал веб-драйвер Chrome из селена для этого проекта. Кроме того, вы можете загрузить веб-драйвер для своего конкретного браузера и сохранить его в легкодоступном месте (C:\users\webdriver\chromedriver.exe). На этом сайте вы можете скачать веб-драйвер для вашего браузера.
Найти и извлечь элементы данных
Команда get запускает браузер и открывает указанный URL-адрес в вашем веб-драйвере.
driver.get(url)
Для каждого из элементов данных, которые мы хотим извлечь, мы найдем все строки HTML, которые находятся в пределах определенного тега и класса. Затем мы извлечем элементы данных и сохраним данные в списке. Для этого проекта мы будем очищать 10 последовательных веб-страниц.
name_list = []
titles_list = []
reviews_list = []
for i in range(0, 10):
# Extract reviewer names.
names = driver.find_elements(By.XPATH, "(//a[@class='ui_header_link uyyBf'])")
for name in range(len(names)):
name_list.append(names[name].text)
# Extract review title.
review_names = driver.find_elements(By.XPATH, "(//a[@class='Qwuub']/span)")
for review in range(len(review_names)):
titles_list.append(review_names[review].text)
# Extract reviews.
reviews = driver.find_elements(By.XPATH, "(//q[@class='QewHA H4 _a']/span)")
for review in range(len(reviews)):
reviews_list.append(reviews[review].text)
driver.find_element(By.XPATH, "//a[@class='ui_button nav next primary ']").click()
time.sleep(2)
driver.quit()
Создайте кадр данных
Нам нужно убедиться, что списки имеют одинаковое количество записей до создания фрейма данных.
# Print the lengths of each list. print(len(name_list), len(titles_list), len(reviews_list)) 100 100 100
Объедините списки.
data =list( zip(name_list, titles_list, reviews_list))
Создайте фрейм данных.
reviews = pd.DataFrame(data,columns=['Reviewer', 'Review Title', 'Review']) reviews.head(5)

Преобразовать фрейм данных в файл CSV
reviews.to_csv('hotel_reviews.csv', index=False, header=True)

Создайте переменную, содержащую только отзывы об отелях.
only_reviews = reviews.iloc[:, 2].values
Создайте новый фрейм данных, содержащий отзывы.
hotel_reviews = pd.DataFrame({'reviews': only_reviews})
hotel_reviews.head(5)

Применить анализ тональности
Анализ тональности — это метод анализа текста, который выявляет полярность (положительное или отрицательное мнение) в тексте. Мы будем использовать подмодуль VADER NLTK (Natural Language Toolkit) для анализа тональности текста.
VADER (Valence Aware Dictionary for Sentiment Reasoning) — это модуль, используемый для анализа тональности текста, который чувствителен как к полярности (положительные/отрицательные), так и к интенсивности (силе) эмоций. Он применяется непосредственно к немаркированным текстовым данным и специально разработан для настроений, выраженных в социальных сетях.
SentimentIntensityAnalyzer() VADER принимает строку и возвращает словарь оценок в каждой из следующих категорий:
- отрицательный
- нейтральный
- положительный
- составной (сумма положительных, отрицательных и нейтральных оценок, которая затем нормализуется между -1 (сильно отрицательный) и +1 (сильно положительный).
Например, следующий текст вернет эти выходные оценки:
'Это был лучший, самый потрясающий фильм, КОГДА-ЛИБО СДЕЛАННЫЙ!!!'
ВЫВОД-{'отрицательный': 0,0, 'ней': 0,425, «поз»: 0,575, «составной»: 0,8877}
Оценки колеблются от -1 до 1, где -1 — сильно отрицательное значение, а +1 — сильно положительное значение. Мы будем использовать составной балл, чтобы определить, являются ли отзывы об отеле положительными или отрицательными.
Теперь мы инициализируем анализатор интенсивности настроений и создадим лямбда-функцию, которая принимает текстовую строку, применяет к ней функцию vader.polarity_scores(), чтобы получить результаты, а затем возвращает составные оценки. Используя функцию применения в Pandas, мы можем создать новый составной столбец во фрейме данных со всеми составными оценками для каждого отзыва.
# Initialize the SentimentIntensityAnalyzer.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
import nltk
nltk.download('vader_lexicon')
vader = SentimentIntensityAnalyzer()
# Apply lambda function to get compound scores.
function = lambda title: vader.polarity_scores(title)['compound']
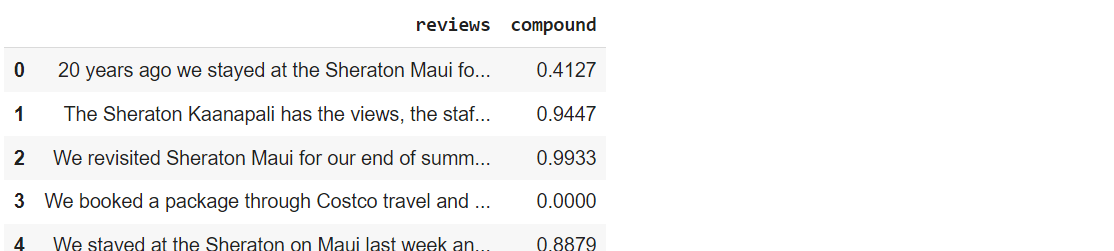
hotel_reviews['compound'] = hotel_reviews['reviews'].apply(function)
hotel_reviews.head(5)
Визуализируйте чувства
Посмотрим, как распределятся чувства. Мы можем лучше понять общеупотребительные слова, нарисовав облака слов. Облако слов (также известное как текстовые облака) — это визуализация, при которой чем больше определенного слова появляется в тексте, тем крупнее и жирнее оно появляется в облаке слов.
Давайте визуализируем все слова в данных, используя график облака слов.
# Word cloud visualization.
from wordcloud import WordCloud
import seaborn as sns
import matplotlib.pyplot as plt
allWords = ' '.join([twts for twts in hotel_reviews['reviews']])
wordCloud = WordCloud(width=500, height=300, random_state=21, max_font_size=110).generate(allWords)
plt.imshow(wordCloud, interpolation="bilinear")
plt.axis('off')
plt.show()

Комната, отель и пляж — общие слова, которые выделяются.
Теперь мы создадим функцию для вычисления отрицательных (-1), нейтральных (0) и положительных (+1) настроений и добавим новый столбец с именем настроений в наш фрейм данных.
def getAnalysis(score):
if score < 0:
return 'Negative'
elif score == 0:
return 'Neutral'
else:
return 'Positive'
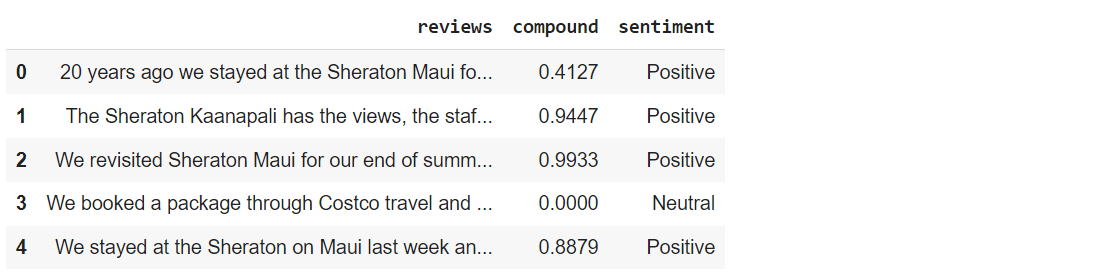
hotel_reviews['sentiment'] = hotel_reviews['compound'].apply(getAnalysis)
hotel_reviews.head(5)
Давайте посмотрим на счетчики для каждого типа настроений.
hotel_reviews['sentiment'].value_counts()

Всего 100 отзывов. Мы видим, что 84 отзыва положительные, 15 отрицательные и 1 нейтральный.
Визуализируйте количество для каждого типа настроений.
plt.title('Sentiment Analysis')
plt.xlabel('Sentiment')
plt.ylabel('Counts')
hotel_reviews['sentiment'].value_counts().plot(kind = 'bar')
plt.show()

Визуализируйте распределение мнений по всем отзывам.
hotel_reviews.sentiment.value_counts().plot(kind='pie', autopct='%1.0f%%', fontsize=12, figsize=(9,6), colors=["blue", "red", "yellow"])
plt.ylabel("Hotel Reviews Sentiment", size=14)

Визуализируйте распределение настроений на основе сложных оценок.
plt.figure(figsize=(8, 5))
sns.histplot(hotel_reviews, x='compound', color="darkblue", bins=10, binrange=(-1, 1))
plt.title("Hotel Reviews Sentiment Distribution")
plt.xlabel("Compound Scores")
plt.ylabel("")
plt.tight_layout()

Выводы
Всего было 100 отзывов. Подавляющее большинство отзывов положительно относятся к этому отелю. 84% настроений положительные, 15% отрицательные и 1% нейтральные. Основываясь на этих результатах, я думаю, что Sheraton Maui Resort & Spa будет очень хорошим местом для отдыха.
Большое спасибо за прочтение моей статьи! Если у вас есть какие-либо комментарии или отзывы, пожалуйста, добавьте их ниже.
Если вам нравится читать такие истории и вы хотите поддержать меня как писателя, подумайте о том, чтобы зарегистрироваться и стать участником Medium. Членство дает вам неограниченный доступ ко всем историям на Medium. Зарегистрироваться можно по этой ссылке https://medium.com/@dniggl/membership
Дополнительные материалы на PlainEnglish.io. Подпишитесь на нашу бесплатную еженедельную рассылку новостей. Подпишитесь на нас в Twitter и LinkedIn. Посетите наш Community Discord и присоединитесь к нашему Коллективу талантов.