В настоящее время сверточные нейронные сети (CNN) используются для решения многочисленных задач компьютерного зрения, таких как автономное вождение, вплоть до медицинских приложений. Для таких критичных с точки зрения безопасности доменов наличие «надежной» модели имеет решающее значение. Подождите, что означает «надежный» в этом контексте?🤨 Мы обсудим это через мгновение. А пока рассмотрим надежную модель, модель, способную давать хорошие прогнозы на нечистых данных, которые она могла не увидеть во время обучения.
В этой статье представлен обзор исследовательских работ по надежности CNN. Мы рассмотрим:
- Что означает «надежность» модели и какие показатели мы можем использовать для ее измерения?
- Какие наборы данных доступны для сравнительного анализа надежности?
- Насколько надежны архитектуры CNN, такие как ResNet50?
- Какие методы могут повысить «надежность» модели CNN?
Часть 1. Что такое надежность и какие показатели мы можем использовать для ее измерения?
Предположим, у нас есть классификатор CNN, который классифицирует, содержит ли изображение птицу или нет. На чистом изображении работает наш классификатор. Но что, если изображение размыто, при съемке был туман или яркость высокая? Будет ли наша модель по-прежнему делать правильный прогноз? Ниже мы находим так называемые «синтетические искажения» от ImageNet-C [1]

Для нашего человеческого мозга 🧠 очевидно, что все вышеперечисленные изображения соответствуют птице. Спойлер 🎥: для CNN это совсем не очевидно! 🤯🤯
Одной из распространенных метрик, представленных в [1], является метрика Corruption Error (CE). Он определяется для классификации изображений как
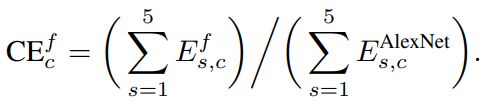
где c относится к типу повреждения, например. туман, f относится к модели, а s относится к уровню серьезности повреждения от 1 до 5. Затем мы просто суммируем каждую ошибку уровня повреждения. Более того, ошибка нормализована с использованием ошибки AlexNet[8], чтобы сделать коэффициенты ошибок более сопоставимыми. Обычно ошибка E относится либо к первой, либо к пятой частоте ошибок при классификации. Чтобы вычислить среднюю ошибку искажения (mCE), нужно просто вычислить среднее значение ошибок искажения для каждого типа повреждения.
Предположим, что у нас есть две модели A и B. Модель A достигает 30% частоты ошибок в чистом наборе данных, а модель B достигает 40%. Таким образом, модель А работает лучше. В версии с поврежденным набором данных частота ошибок top1 для модели A достигает 50 %, а для модели B — 55 %. Опять же, модель А дает лучшую производительность. Однако обратите внимание, что падение производительности при переходе от Clean → Corrupted больше в модели A, где у нас падение производительности на 20%, а в модели B — на 15%. Чтобы измерить это, авторы в [1] ввели показатель Relative Corruption Error (Relative CE).

Аналогично CE, мы суммируем по каждому уровню серьезности и нормализуем с относительными ошибками коррупции AlexNet. Наконец, относительный mCE вычисляется путем усреднения относительного CE для различных типов повреждений.
Часть 2: Виды коррупции
Существуют различные виды коррупции:
- Синтетические искажения, как показано на рис. 1: здесь авторы [1] пытаются искусственно смоделировать туман, снег и т. д. Мы увидим, что это преобладающий тип искажения в наборы данных надежности
👍: Нет необходимости в новых метках (наземные истины), мы можем повредить, например, изображения ImageNet и продолжать использовать те же метки.
👎: Синтетические искажения не всегда могут представлять искажения реального мира. Мы увидим, что [3] пытается пролить свет на вопрос, являются ли синтетические искажения репрезентативными для реальных искажений.
- Коррупция в реальном мире: изображения, сделанные, например. в реальном сценарии тумана. Здесь доступны только несколько наборов данных.
👍: Представитель коррупции в реальном мире.
👎: Нужно пометить новый набор данных, что, вероятно, дорого 💰
- Adversarial Perturbations: здесь авторы [6] вносят изменения в изображение на уровне пикселей. Такая коррупция может быть даже не видна людям. Тем не менее, [6] показывает, что многие CNN не работают с такими поврежденными изображениями. Хорошее введение в это можно найти на MLGS Videos — Data Analytics and Machine Learning (tum.de). Я прошел этот курс профессора Гюннемана в Мюнхенском техническом университете в 2021 году, и лекции очень интересные🙂. Кроме того, этот пост на Medium Дружелюбное введение в состязательные атаки также дает хороший обзор! Некоторые состязательные примеры можно увидеть ниже.
👍: Четкая математическая основа для «производства» этих искажений.
👎: Они не являются представителями коррупции в реальном мире. В некоторых работах, таких как [2], утверждается, что обучение модели таким искажениям не помогает повысить устойчивость к более реалистичным искажениям. Однако в недавней статье [6] утверждается, что это возможно и достигается современная производительность на ImageNet-C при выполнении состязательного обучения вместе с ViT [7], архитектурой преобразователя зрения.

Часть 3. Наборы данных для оценки надежности
Многие наборы данных для оценки надежности используют синтетические искажения [1, 2]. Насколько мне известно, следующие из них кажутся наиболее «популярными» для оценки надежности.
ImageNet-C (поврежденный), представленный в [1]
Представлено в 2019 году Хендриком и соавт. [1], изображения ImageNet повреждены 15 типами повреждений [см. рис. 1] с s = от 1 до 5 уровней серьезности каждого. Эти искажения можно разделить на 4 группы: Шум, размытие, погода и цифровые данные. Ниже мы видим пример для каждого уровня серьезности.

ImageNet-R (Renditions), представленный в [2]
Представлено в 2021 году Хендриксом и соавт. [2], ImageNet-Renditions содержат художественные исполнения из исходного набора данных ImageNet. Он был введен для дальнейшего анализа гипотезы текстурного смещения, сформулированной в [3]. Мы еще обсудим эту текстурную гипотезу в части 5. Ниже мы находим пример ImageNet-R.

ImageNet-стилизованный представлен в [3]
Представленный в 2019 году Хендриксом и др. [3], ImageNet-Stylized служит той же цели, что и ImageNet-R, для проверки гипотезы смещения текстуры [3]. Эта гипотеза сформулирована теми же авторами в [3]. Новые изображения создаются путем «удаления исходной текстуры каждого отдельного изображения и замены его стилем случайно выбранной картины посредством переноса стиля AdaIN (Huang & Belongie, 2017)». Пример показан ниже.

Набор данных Real Blurry Images
Представлено в 2021 году Хендриксом и соавт. [2], набор данных Real Blurry Images содержит 1000 реальных размытых изображений, каждое из которых принадлежит к одному из 100 классов ImageNet. Цель этого набора данных — ответить на вопрос, являются ли модели, которые «устойчивы» к синтетическим искажениям, также устойчивы к «реальным» искажениям. Ниже приведен пример этого набора данных.

Давайте обсудим некоторые документы !!🧐📰
Часть 4: «Сравнительный анализ устойчивости нейронной сети к распространенным повреждениям и возмущениям», автор Hendryck et al. ICLR 2019
Как упоминалось выше, в этом документе представлен набор данных ImageNet-C (Corrupted) с 15 синтетическими искажениями, а также представлены показатели искажения: ошибка искажения CE, средняя ошибка искажения mCE, относительная ошибка искажения и относительный mCE.
Авторы обнаруживают, что с годами при использовании более новых архитектур mCE постепенно уменьшался. Однако авторы отмечают, что относительный mCE остается ок. постоянный, т. е. падение производительности от чистых → поврежденных данных не улучшилось. Мы можем видеть это на следующем рисунке слева.


Еще один интересный факт, на который указывают авторы, заключается в том, что более крупные модели кажутся более надежными, как показано на рисунке выше. Другие статьи, такие как [2], также делают то же наблюдение. Кажется, мы уже нашли способ повысить надежность!🎉🎉
Часть 5: «CNN, обученные ImageNet, ориентированы на текстуру; Увеличение смещения формы повышает точность» Geirhos et al. ICLR 2019
В этой статье формулируется гипотеза смещения текстуры, заключающаяся в том, что CNN в своих прогнозах полагаются в основном на текстуру изображений, а не на форму людей. Следующий рисунок иллюстрирует концепцию: «Кошка с текстурой слона — это слон для CNN, и все еще кошка для людей». Авторы утверждают, что изучения текстур изображений недостаточно для достижения хорошей производительности в ImageNet.

Чтобы проверить гипотезу смещения текстуры, авторы вводят набор данных ImageNet-Stylized, в котором, как объяснялось в части 3, текстуры заменяются новыми текстурами, как это видно на изображении кошки выше с текстурой слона. Итак, как модель, обученная в ImageNet, ведет себя в стилизованной ImageNet?
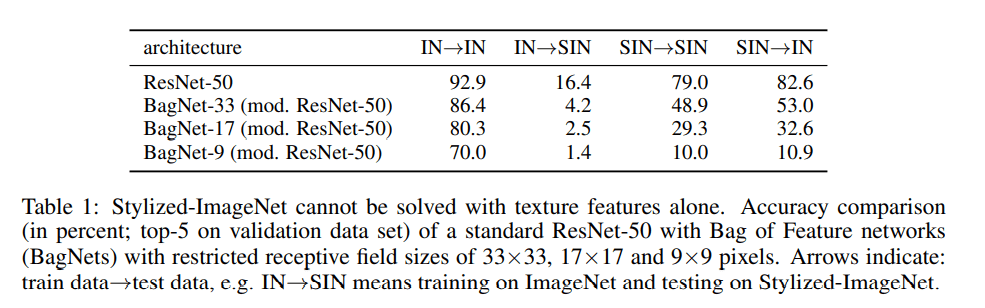
При обучении ResNet-50 в ImageNet и оценке в ImageNet-S производительность действительно низкая: точность топ-5 составляет всего 16,4 %. С другой стороны, обучение на ImageNet-S и оценка на ImageNet дают 82,6 % точности в пятерке лучших. Авторы утверждают, что этот факт указывает на то, что модель, обученная на ImageNet-S, имеет более сильное смещение формы и, следовательно, обобщает лучше, чем модель, обученная на ImageNet, которая имеет сильное смещение текстуры.
Авторы дополнительно проверяют свою гипотезу смещения текстуры с помощью так называемых BagNets, которые имеют ограниченное рецептивное поле. Чем меньше рецептивное поле, тем меньше способность модели «видеть» или «учить» формы. Следовательно, модель будет ориентироваться на локальные текстуры. В частности, мы видим, что BagNet-9 (самое маленькое рецептивное поле) не может должным образом «обучаться» на ImageNet-S, обеспечивая 10% точность в пятерке лучших.
Затем авторы показывают в экспериментах как с людьми, так и с CNN, что действительно CNN, обученные предсказаниям ImageNet, предвзято относятся к текстуре изображения, в то время как люди больше всего полагаются на форму, как показано на следующем рисунке.
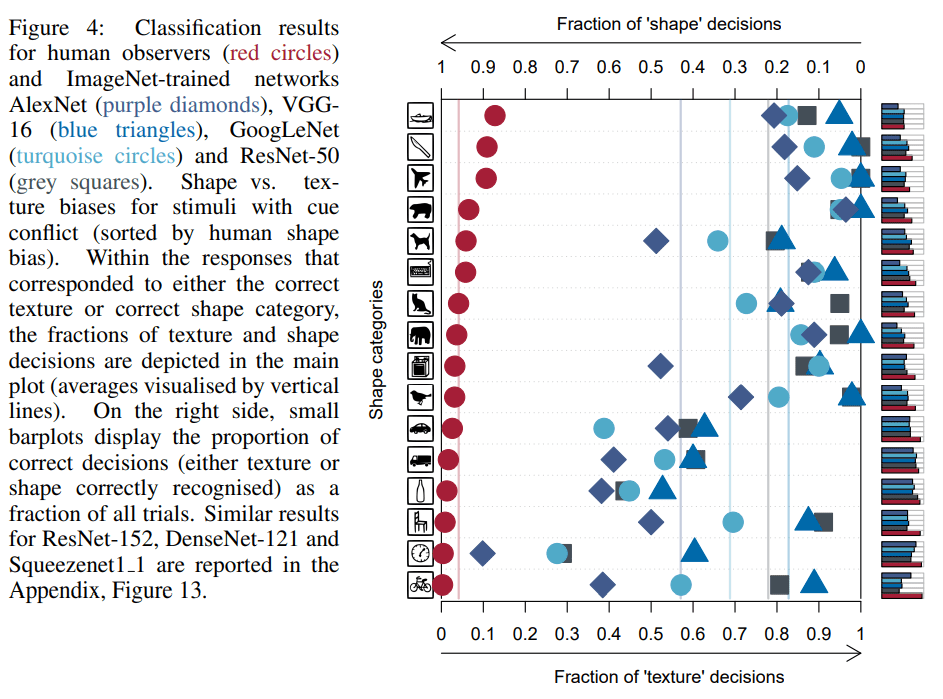
Точные эксперименты по вычислению долей решений «текстура» и «форма» можно найти в статье [3]. Здесь мы сосредоточимся на результатах.
Более того, кажется, что обучение CNN на ImageNet-S дает более сильное смещение формы в прогнозах, ближе к людям. Это показано на следующем рисунке.

Многие, если не большинство предварительно обученных магистральных сетей, которые мы находим в современных архитектурах, все еще предварительно обучены в ImageNet. Взглянув, например, на MMSegmentation, становится ясно, что большинство архитектур предварительно обучены в ImageNet. Являются ли эти модели также сильно смещенными в сторону текстуры, т.е. передается ли это смещение текстуры при точной настройке других наборов данных?
Часть 6: «Многоликая надежность: критический анализ обобщения вне распределения» Хендрикса и др. МККТ 2021
В этом документе представлены 4 новых набора данных для оценки надежности: ImageNet-Renditions с изображениями, такими как картины, StreetView Store Fronts (SVSF) с изображениями витрин магазинов, DeepFashion Remixed (DFR) и Real Blurry Images. Ниже мы видим несколько примеров изображений этих наборов данных.

Статья направлена на анализ этих наборов данных, какие методы повышения надежности могут работать лучше всего. Можно повысить надежность за счет:
- Большие модели, как мы уже видели в части 4 [1]
- Слои самоконтроля
- Методы увеличения данных, такие как AugMix [9] или DeepAugment, которые представлены в этой статье. Здесь основная идея состоит в том, чтобы дополнить чистое изображение, чтобы модель научилась более разнообразным «представлениям».
- Предварительное обучение на более крупных и разнообразных наборах данных, например. предварительная подготовка на ImageNet 1k против ImageNet 21k
- Состязательное обучение, здесь мы обучаем модель, чтобы она была устойчивой к состязательным возмущениям.
Авторы также представляют новую технику увеличения под названием DeepAugment, основная идея которой заключается в «искажении изображений путем нарушения внутренних представлений глубоких сетей», а искажение относится к «обнулению, отрицанию, свертыванию, транспонированию…». Ниже мы находим визуальное представление

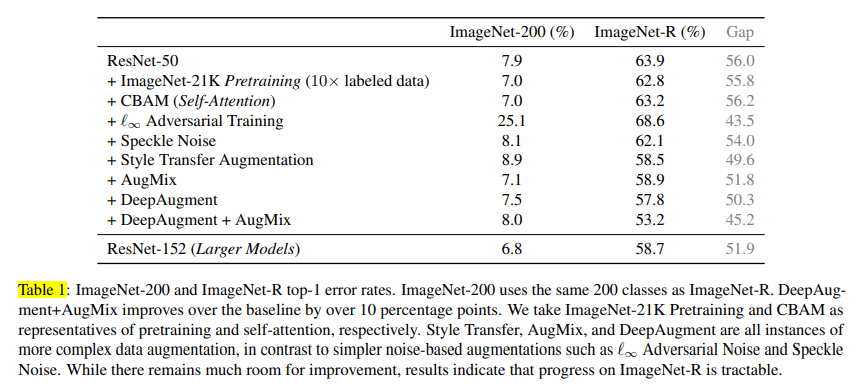
В приведенной выше таблице показана первая ошибка, оцененная как для ImageNet-200, так и для ImageNet-R. Базовая модель ResNet-50 обучена на ImageNet-21k. Мы можем наблюдать некоторые интересные факты здесь
- В то время как базовая модель хорошо работает на ImageNet-200, ее производительность резко падает с 7,9 % частоты появления первых ошибок до 63,9 % на ImageNet-R. Для всех методов «улучшения надежности» ошибка Top1 ImageNet-R превышает 50%.
- Самая низкая частота ошибок в топ-1 на ImageNet-R, 53,2%, достигается при обучении с использованием комбинированных методов аугментации AugMix+DeepAugment.
- В целом, методы аугментации повышают надежность
- Использование более крупной модели ResNet-152 также снижает количество ошибок в ImageNet-R.
- Противоборствующее обучение, по-видимому, вызывает снижение производительности. Однакообратите внимание, что вопрос о том, помогает ли состязательное обучение или нет, остается открытым в исследовательском сообществе. В этой статье, а также в [10] утверждается, что состязательное обучение не помогает повысить надежность или точность. В статье Состязательные примеры улучшают распознавание изображений [11] отмечается, что использование различных пакетных нормализации для чистых и состязательных изображений позволяет повысить точность модели. [6] следует этому направлению исследований и показывает, что сочетание противоборствующего обучения и преобразователей зрения дает очень многообещающие результаты на ImageNet-R с частотой ошибок 42,16% в топ-1. Подробнее об этом в другом посте 😜

Авторы также рассматривают вопрос о том, приводит ли повышение надежности синтетических наборов данных, поскольку ImageNet-C, к повышению устойчивости к «реальным» повреждениям. В частности, они проверяют, коррелирует ли более высокая частота ошибок Top1 в ImageNet-C Blur с лучшей частотой ошибок Top1 в наборе данных Real Blurry Images. Из приведенной выше таблицы видно, что эта корреляция существует, и методы, которые улучшают частоту ошибок top1 в Imagenet-C Blur, также улучшают количество ошибок top1 в реальных размытых изображениях.
Авторы утверждают, что это «проверка использования синтетических тестов для измерения надежности модели». С моей точки зрения, это может быть довольно сильным утверждением, поскольку синтетические искажения — это не только размытые искажения, но и погодные искажения, такие как снег, туман, мороз и т. д. Остается проверить, соответствует ли корреляция, которую мы видим в приведенная выше таблица также применима к другим типам коррупции в реальном мире. Было бы интересно провести исследование в этом направлении 🙄🙄
Часть 7. Анализ контрольных показателей на 2022 г.
Статьи как [1, 2] были опубликованы в 2019 году. Давайте кратко рассмотрим текущее состояние дел в ImageNet-C.

Для ImageNet-C показатель mCE снизился с 76,7 (ResNet50) до 33,8. Мы видим интересную тенденцию:
- Архитектура Pure ResNet50 достигает 76,7 mCE
- Обучение на Stylized ImageNet улучшилось до 69,3 mCE
- Методы увеличения, такие как AugMix [9] и DeepAugment [2], улучшаются до 65,3 mCE и 60,4 mCE соответственно.
- Архитектура «обновленной CNN» ConvNeXt [12] достигает 38,8 mCE
- Архитектуры Vision Transformer, такие как FAN [14], ViT+ Adversarial Training [6] или MAE [13], доминируют в таблице лидеров, а MAE 33,8 mCE занимает первое место.
Тест на ImageNet-R показывает аналогичные тенденции. Посмотреть его можно здесь.
Заключение
Итак, в целом мы увидели, что традиционные CNN могут быть не так близки к человеческому видению, как мы думали. С другой стороны, эталонный график (рис. 18) также показывает значительное улучшение за последние пару лет благодаря новым методам расширения или архитектурам, обеспечивающим более высокую надежность. В частности, преобразователи зрения кажутся очень многообещающими. Подробнее об этом в последующем посте о трансформерах машинного зрения и их надежности.
Не стесняйтесь поделиться своими мыслями по этому поводу ниже 🙂! Буду рад обсудить любые идеи!

Вы идентифицируете себя как латиноамериканец и работаете в области искусственного интеллекта или знаете кого-то, кто является латиноамериканцем и работает в области искусственного интеллекта?
- Зарегистрируйтесь в нашем каталоге и станьте участником форума наших участников: https://lxai.app/
- Станьте автором публикации LatinX в AI: http://bit.ly/LXAI-Volunteer
- Узнайте больше на нашем сайте: http://www.latinxinai.org/
Не забудьте нажать 👏 ниже, чтобы поддержать наше сообщество — это очень много значит! Спасибо :)
Ссылки
[1]Hendryck et al. «Сравнительный анализ устойчивости нейронной сети к обычным искажениям и возмущениям» ICLR 2019
[2] Хендрикс и соавт. «Многоликая надежность: критический анализ обобщения вне распределения» ICCV 2021
[3] Geirhos et al. «CNN, обученные Image-Net, ориентированы на текстуру: увеличение смещения формы повышает точность и надежность» ICLR 2019
[4] Ямада и Отани «Переносит ли надежность ImageNet на последующие задачи», CVPR 2022
[5] Goodfellow et al. «Состязательные примеры в физическом мире» ICLR 2017
[6] Herrmann et al. «Пирамидное состязательное обучение повышает эффективность ViT» CVPR 2022
[7] Досовицкий и соавт. «Изображение стоит 16x16 слов: преобразователи для распознавания изображений в масштабе» ICLR 2021
[8]Крижевский и др. «Классификация ImageNet с глубокими свёрточными нейронными сетями» NIPS 2012
[9]Hendrycks et al. AugMix: простой метод обработки данных для повышения надежности и неопределенности ICLR 2020
[10]Tsipras et al. «Надежность может противоречить точности» ICLR 2019
[11] Xie et al. «Состязательные примеры улучшают распознавание изображений» CVPR 2020
[12]Liu et al. «Конвнет для 2020-х» CVPR 2022
[13] He et al. Маскированные автоэнкодеры — масштабируемые обучающиеся зрительного восприятия CVPR 2022
[14]Zhou et al. «Понимание надежности преобразователей зрения» ICML 2022