Различные пакеты Python для специалистов по данным

Данные — это обширная область с большим сообществом, поддерживающим развитие технологий. Кроме того, у Python есть ярый сторонник, который помогает миру данных стать более доступным и повышает ценность рабочего процесса данных.
Различные пакеты Python были разработаны, чтобы помочь людям, работающим с данными, в их работе. По моему опыту, многие полезные пакеты данных Python не получили признания или их популярность все еще растет.
Вот почему в этой статье я хочу познакомить вас с несколькими уникальными пакетами Python, которые во многом помогут вашему рабочему процессу с данными. Давайте погрузимся в это!
1. Тук-тук
Knockknock — это простой пакет Python, который уведомляет вас о завершении или сбое обучения модели машинного обучения. Мы могли получать уведомления по многим каналам, таким как электронная почта, Slack, Microsoft Teams и т. д.
Для установки пакета мы используем следующий код.
pip install knockknock
Например, мы могли бы использовать следующий код, чтобы уведомить о вашем статусе обучения моделированию машинного обучения на ваш адрес электронной почты Gmail.
from knockknock import email_sender from sklearn.linear_model import LinearRegression import numpy as np @email_sender(recipient_emails=["<[email protected]>", "<[email protected]>"], sender_email="<[email protected]>") def train_linear_model(your_nicest_parameters): x = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) y = np.dot(x, np.array([1, 2])) + 3 regression = LinearRegression().fit(x, y) return regression.score(x, y)
Вы получите уведомление от любой функции, к которой возвращаетесь.
2. ткдм
Вам нужен индикатор выполнения, отображаемый, когда вы выполняете итерацию или циклический процесс? Тогда tqdm — ваш ответ. Этот пакет будет предлагать простой измеритель прогресса в вашем ноутбуке или командной строке.
Начнем с установки пакета.
pip install tqdm
Затем мы могли бы попытаться использовать следующий код, чтобы показать индикатор выполнения в процессе зацикливания.
from tqdm import tqdm
q = 0
for i in tqdm(range(10000000)):
q = i +1
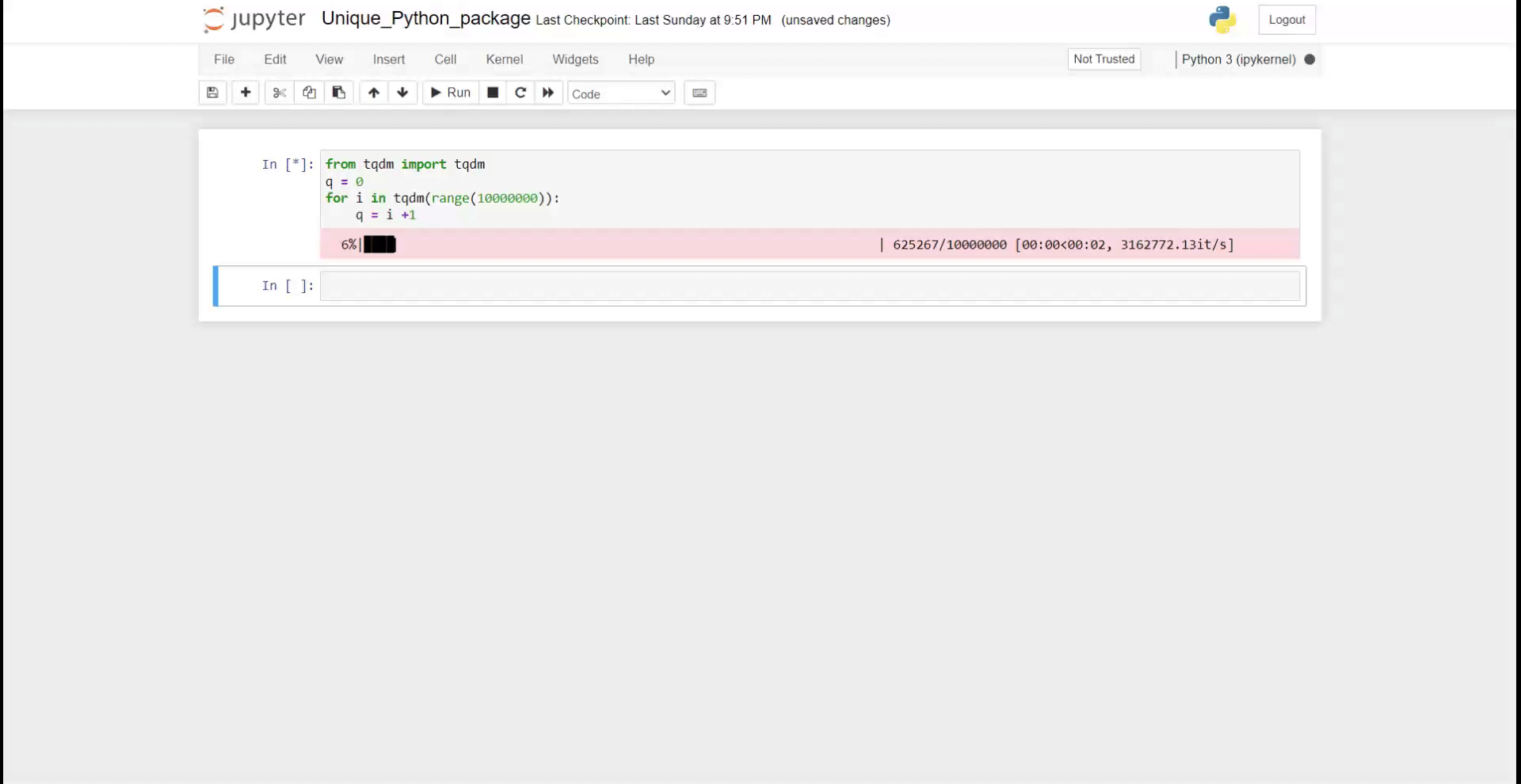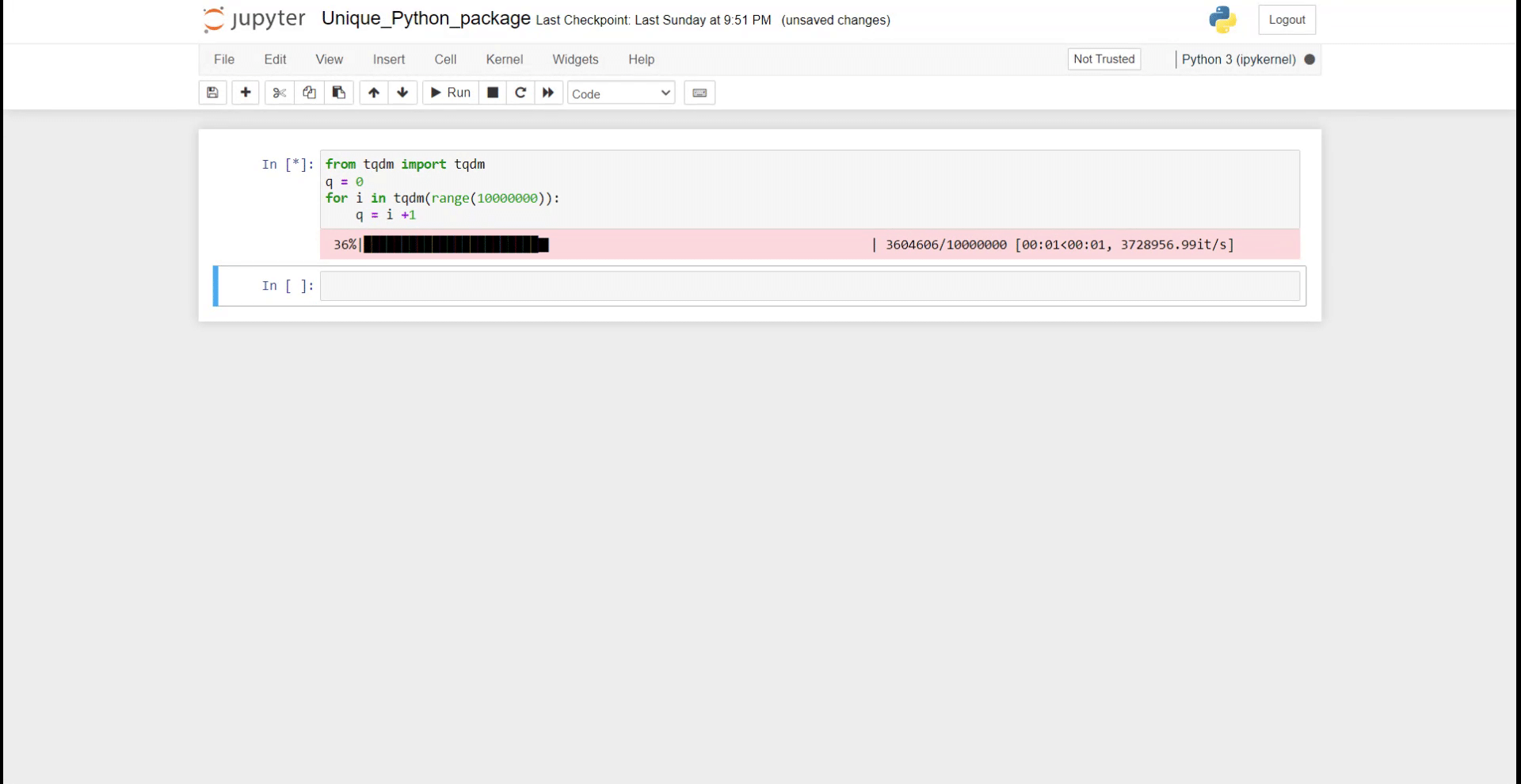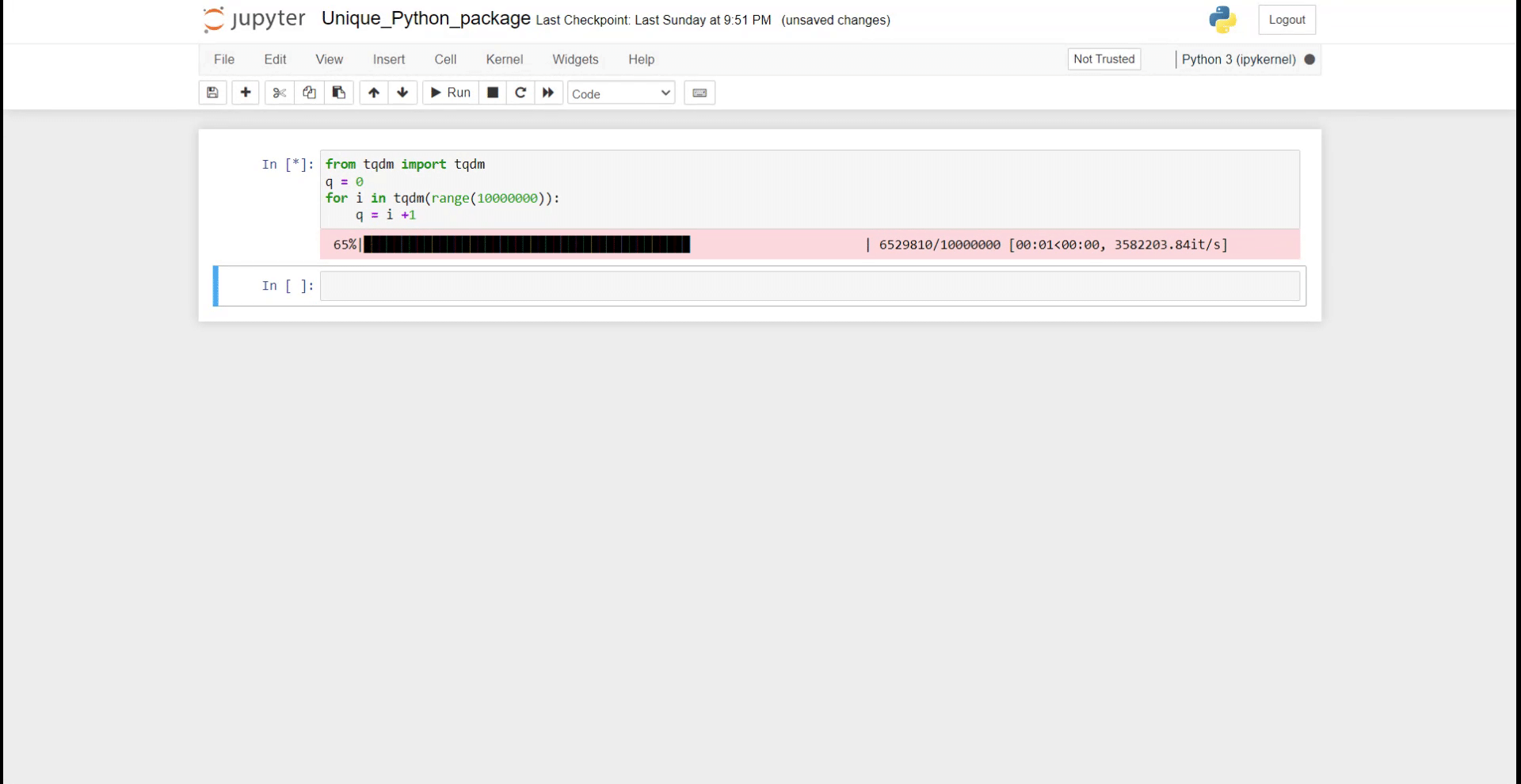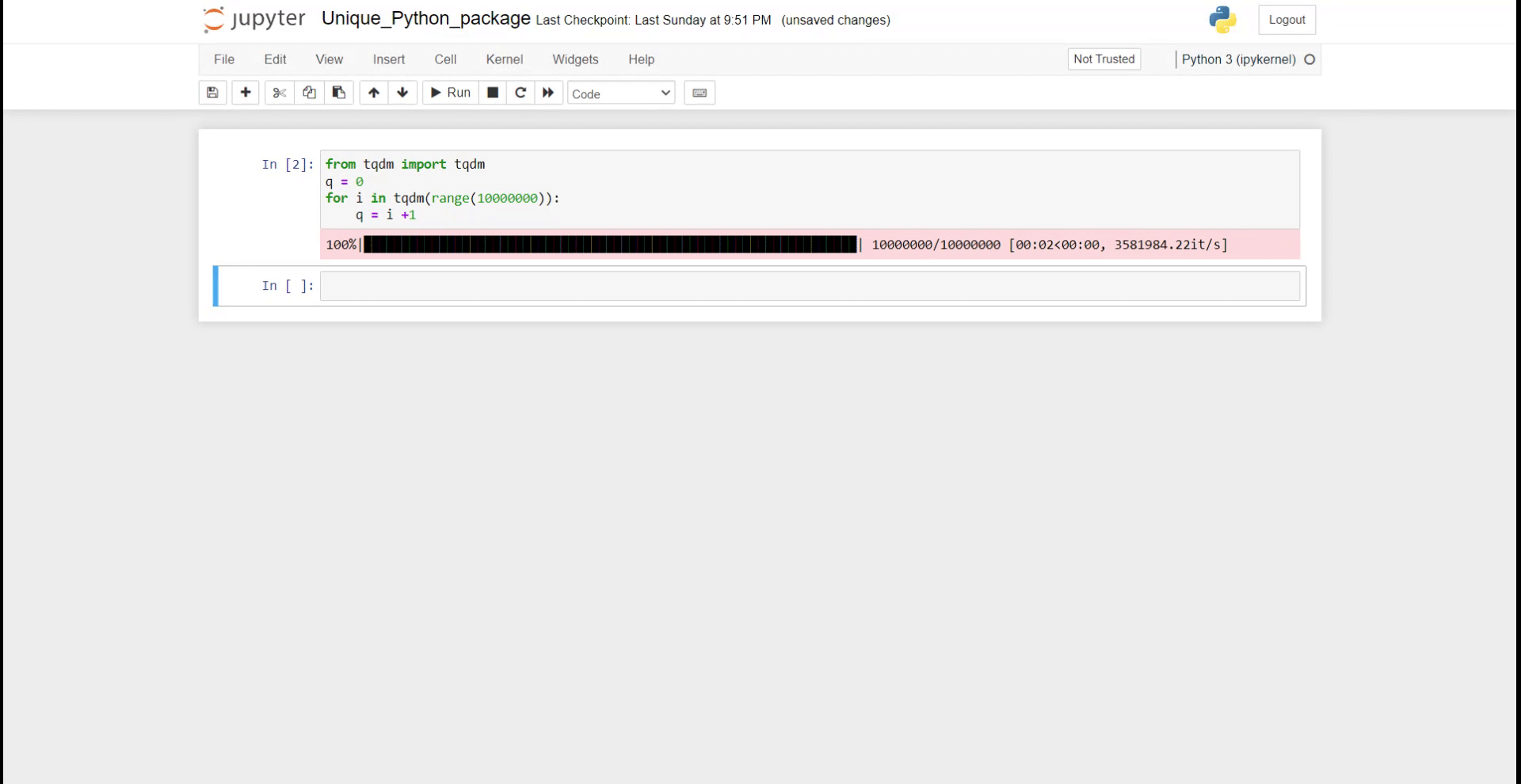
Как вы можете видеть на GIF выше, в вашей записной книжке отображается хороший индикатор выполнения. Это гораздо полезнее, когда у вас сложная итерация и вы хотите отслеживать прогресс.
3. Панды-журнал
Pandas-log — это пакет Python, который обеспечивает обратную связь по основным операциям Panda, таким как .query, .drop, .merge и другим. Он основан на R Tidyverse, где вы можете понять все этапы анализа данных.
Попробуем установить пакет.
pip install pandas-log
После установки пакета давайте создадим образец фрейма данных, используя следующий код.
import pandas as pd
import numpy as np
import pandas_log
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]})
Затем давайте попробуем выполнить простое выполнение pandas со следующим кодом.
with pandas_log.enable():
res = (df.drop("born", axis = 1)
.groupby('name')
)

С Pandas-log мы могли получить всю информацию о выполнении.
4. Эмодзи
Как следует из названия, Emoji — это пакет Python, который поддерживает анализ текстовых данных эмодзи. Обычно у нас возникают трудности с чтением смайликов с помощью Python, но пакет Emoji помогает нам с этим.
Установка пакета Emoji со следующим кодом.
pip install emoji
Давайте попробуем простой смайлик с пакетом.
import emoji
print(emoji.emojize('Python is :thumbs_up:'))
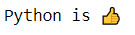
С пакетом мы можем получить вывод эмодзи, потому что эмодзи были декодированы, чтобы быть приемлемыми в Python.
5. Пух
TheFuzz — это пакет Python, который сопоставляет текст с использованием расстояния Левенштейна для вычисления сходства.
Чтобы использовать пакет, нам нужно сначала установить его.
pip install thefuzz
Давайте попробуем пакет, чтобы увидеть, как мы можем использовать пакет TheFuzz для сопоставления текста по сходству.
from thefuzz import fuzz, process
#Testing the score between two sentences
fuzz.ratio("Test the word", "test the Word!")

TheFuzz также работает для одновременного извлечения оценок сходства из многих слов.
choices = ["Atlanta Falcons", "New York Jets", "New York Giants", "Dallas Cowboys"]
process.extract("new york jets", choices, limit=2)

TheFuzz хорош для любой деятельности по сходству текстовых данных. Это должен быть один из пакетов, существующих в вашем арсенале.
6. Нумератор
Numerizer — это пакет Python, который преобразует записанный числовой текст в его целочисленный аналог или аналог с плавающей запятой. Давайте попробуем пакет, чтобы узнать о нем больше.
Сначала мы устанавливаем пакет, используя следующий код.
pip install numerizer
Тогда мы могли бы протестировать пакет. Попробуем преобразовать несколько слов.
from numerizer import numerize
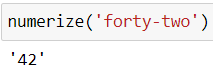
numerize('forty two')

Как видите, слова были преобразованы в целочисленные эквиваленты. Это также работает, если вы используете другой стиль письма, например, как показано ниже.
numerize('forty-two')
Это также работает для слов, которые выражают числовой текст с плавающей запятой.
numerize('nine and three quarters')

И если слова не являются числовым выражением, они останутся такими, какие они есть.
numerize('maybe around nine and three quarters')

Пакет простой, но будет полезен во многих случаях.
7. PyAutoGUI
PyAutoGUI — это простой пакет Python, который автоматически управляет мышью и клавиатурой. Он работает, передавая код в вашу IDE и позволяя ему работать на вас. Начнем с установки пакета.
pip install pyautogui
Затем мы могли бы протестировать движение, используя следующий код.
import pyautogui
pyautogui.moveTo(10, 15)
pyautogui.click()
pyautogui.doubleClick()
pyautogui.press('enter')
Приведенный выше код перемещает мышь в определенное положение и щелкает мышью. Минуя функцию нажатия, вы также могли нажать определенную кнопку клавиатуры.
Этот пакет очень полезен, когда вам нужны повторяющиеся действия, такие как загрузка файлов или сбор данных.
8. Взвешенные расчеты
Weightedcalcs — это пакет Python для упрощения расчета взвешенной статистики на основе нашего фрейма данных. Использование варьируется от простой статистики, такой как средневзвешенное значение, медиана и стандартная вариация, до взвешенного количества и распределения.
Чтобы использовать пакет, нам нужно установить его, используя следующий код.
pip install weightedcalcs
Попробуем рассчитать взвешенное распределение по имеющимся данным.
import seaborn as sns
df = sns.load_dataset('mpg')
Я бы использовал набор данных MPG из пакета seaborn. Чтобы вычислить взвешенную статистику, нам нужно сначала объявить класс с весовой переменной.
import weightedcalcs as wc
calc = wc.Calculator("mpg")
Затем мы будем использовать класс для взвешенного расчета, передав набор данных и вычислив предполагаемую переменную.
calc.distribution(df, "origin")

9. scikit-postocs
scikit-posthocs — это пакет Python для постфактум-анализа тестов, который часто используется для попарного сравнения в статистическом анализе. Пакет предоставляет простой API-интерфейс scikit-learn для проведения анализа. Давайте начнем с установки пакета, чтобы попробовать его.
pip install scikit-posthocs
Затем давайте начнем с простого набора данных и проведем тест ANOVA, прежде чем опробовать пакет.
import statsmodels.api as sa
import statsmodels.formula.api as sfa
import scikit_posthocs as sp
df = sa.datasets.get_rdataset('iris').data
df.columns = df.columns.str.replace('.', '')
lm = sfa.ols('SepalWidth ~ C(Species)', data=df).fit()
anova = sa.stats.anova_lm(lm)
print(anova)

Мы получили результат теста ANOVA, но не были уверены, какой класс переменных повлиял на результат больше всего. Вот почему мы проведем апостериорный тест, используя следующий код.
sp.posthoc_ttest(df, val_col='SepalWidth', group_col='Species', p_adjust='holm')

Используя scikit-posthoc, мы упростили процесс парного анализа для апостериорного теста и получили P-значение. Если вы хотите узнать больше об апостериорных тестах, вы можете прочитать больше в другой моей статье ниже.
10. youtube_dl
youtube_dl — это простой пакет Python для загрузки видео с Youtube путем предоставления ссылки на ваш код. Давайте попробуем пакет, сначала установив пакет.
pip install youtube_dl
Затем мы используем следующий код для загрузки видео в вашу среду.
# Youtube Dl Example
import youtube_dl
ydl_opt = {}
with youtube_dl.YoutubeDL(ydl_opt) as ydl:
ydl.download(['https://www.youtube.com/watch?v=ukzFI9rgwfU'])

Начнется процесс загрузки, и видео в формате mp4 будет доступно.
11. Цербер
Cerberus — это легкий пакет Python, используемый для проверки данных. Он предназначен для проверки любых данных схемы, которые мы инициировали, и данных, основанных на ней. Начнем с установки пакета.
pip install cerberus
Основное использование Cerberus заключается в том, чтобы инициировать класс валидатора для получения схемы данных.
from cerberus import Validator
schema = {'name': {'type': 'string'}, 'gender':{'type': 'string'}, 'age':{'type':'integer'}}
v = Validator(schema)
Затем с помощью схемы, которую мы передаем в класс Validator, мы можем проверить данные, которые были переданы в код.
document = {'name': 'john doe', 'gender':'male', 'age': 15}
v.validate(document)

Если бы переданные данные были похожи на схему, класс Validator имел бы вывод True. Таким образом, мы могли гарантировать, что ввод данных всегда будет надежным для схемы.
12. общий балл
ppscore — это пакет Python для расчета силы предсказания переменных относительно целевой переменной. Пакет вычисляет оценку, которая может обнаруживать линейные или нелинейные отношения между двумя переменными. Оценка варьируется от 0 (нет предсказательной силы) до 1 (отличная предсказательная сила).
Во-первых, мы бы установили пакет, чтобы попробовать его.
pip install ppscore
Затем, используя доступные данные, мы будем использовать пакет ppscore для расчета оценки на основе цели.
import seaborn as sns
import ppscore as pps
df = sns.load_dataset('mpg')
pps.predictors(df, 'mpg')

Результатом являются переменные, отсортированные по цели с их ppscore. Чем ниже рейтинг, тем ниже предсказательная сила переменной по сравнению с целью.
13. Майя
Maya — это пакет Python для максимально простого анализа данных DateTime. Он использует простое удобочитаемое взаимодействие для получения нужных нам данных DateTime. Давайте начнем использовать пакет, сначала установив его.
pip install maya
Затем мы можем использовать следующий код для простого доступа к текущей дате.
import maya now = maya.now() print(now)
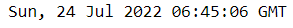
Мы также могли бы инициировать класс объектов для завтрашней даты.
tomorrow = maya.when('tomorrow')
tomorrow.datetime()

Пакет полезен для любой деятельности, связанной с временными рядами, поэтому попробуйте его.
14. Маятник
Pendulum — еще один пакет Python, который касается данных DateTime. Он используется для упрощения любого процесса анализа DateTime. Начнем с импорта пакета.
pip install pendulum
Используя простой пример, мы могли бы легко получить доступ ко времени и изменить его с помощью следующего кода.
import pendulum
now = pendulum.now("Europe/Berlin")
# Changing timezone
now.in_timezone("Asia/Tokyo")
# Default support for common datetime formats
now.to_iso8601_string()
# Day Shifting
now.add(days=2)

15. энкодеры категорий
category_encoders — это пакет Python, используемый для кодирования данных категории (преобразование в числовые данные). Пакет представляет собой набор различных методов кодирования, которые мы можем применять к различным категориальным данным в зависимости от того, что нам нужно.
Чтобы попробовать пакет, нам нужно установить пакет.
pip install category_encoders
Затем мы могли бы применить преобразование, используя следующий пример.
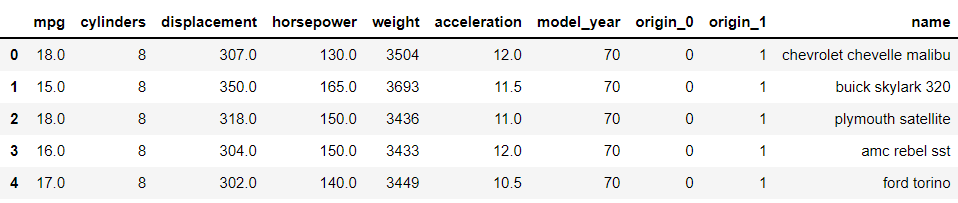
from category_encoders import BinaryEncoder import pandas as pd # use binary encoding to encode two categorical features enc = BinaryEncoder(cols=['origin']).fit(df) # transform the dataset numeric_dataset = enc.transform(df) numeric_dataset.head()
16. scikit-multilearn
scikit-multilearn — это пакет Python для моделей машинного обучения, специфичный для модели классификации с несколькими классами. Пакет предоставляет API для обучения моделей машинного обучения для прогнозирования наборов данных с более чем двумя целевыми классами.
Давайте начнем использовать пакет, сначала установив его.
pip install scikit-multilearn
Используя образец набора данных, мы могли бы использовать Multi-Label KNN для обучения классификатора и измерения показателей производительности.
from skmultilearn.dataset import load_dataset
from skmultilearn.adapt import MLkNN
import sklearn.metrics as metrics
X_train, y_train, feature_names, label_names = load_dataset('emotions', 'train')
X_test, y_test, _, _ = load_dataset('emotions', 'test')
classifier = MLkNN(k=3)
prediction = classifier.fit(X_train, y_train).predict(X_test)
metrics.hamming_loss(y_test, prediction)

17. Мультисет
Multiset — это простой пакет Python, похожий на встроенную функцию set, но допускающий несколько вхождений.
pip install multiset
Мы могли бы использовать функцию Multiset, используя следующий код.
from multiset import Multiset
set1 = Multiset('aab')
set1
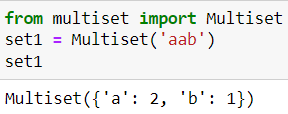
Существуют также различные функции для сравнения и изменения данных, которые вы можете протестировать.
18. Джаззит
Jazzit — симпатичный, но интересный пакет Python для воспроизведения музыки во время ошибок в нашем коде или во время ожидания выполнения кода. Начнем с установки пакета.
pip install jazzit
Затем мы могли бы опробовать образец музыки в ситуации ошибки, используя следующий код.
from jazzit import error_track @error_track("curb_your_enthusiasm.mp3", wait=5) def run(): for num in reversed(range(10)): print(10/num)
Музыка будет играть во время ошибки, так что не удивляйтесь.
19. ручные вычисления
handcalcs — это пакет Python, упрощающий математический латексный процесс ноутбука для рендеринга. Он превращает любую математическую функцию в форму уравнения.
Чтобы установить пакет, мы могли бы использовать следующий код.
pip install handcalcs
Во-первых, нам нужно импортировать необходимый пакет.
import handcalcs.render from math import sqrt
Затем мы попытаемся использовать следующий код для тестирования пакета handcalcs. Используйте волшебную команду %%render для рендеринга расчета латекса.
%%render a = 4 b = 6 c = sqrt(3*a + b/7)

20. Аккуратный текст
NeatText — это простой пакет Python, упрощающий очистку текста и предварительную обработку текстовых данных. Это полезно для любого проекта NLP и данных проекта текстового машинного обучения. Начнем с установки пакета.
pip install neattext
Используя следующий код, мы могли бы опробовать пакет.
import neattext as nt mytext = "This is the word sample but ,our WEBSITE is https://exaempleeele.com 😊✨." docx = nt.TextFrame(text=mytext)
TextFrame используется для запуска класса NeatText, в котором мы могли бы использовать различные функции для описания данных и их очистки.
docx.describe()
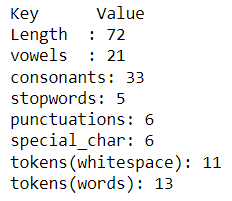
Используя функцию описания, мы могли бы понять каждую текстовую статистику, которую нам нужно знать.
Для дальнейшей очистки данных мы могли бы использовать следующий код.
docx.normalize()

Очистка данных по-прежнему проста, но есть много функций для улучшения предварительной обработки.
21. Комбо
Combo — это пакет Python для комбинации модели машинного обучения и оценки. Пакет предоставляет набор инструментов, позволяющий объединить различные модели машинного обучения в одну модель. Это считается подзадачей в модели обучения ансамбля.
Чтобы опробовать пакет, давайте сначала установим его.
pip install combo
Мы могли бы попытаться создать комбинацию машинного обучения, используя набор данных о раке молочной железы, доступный в scikit-learn, и различные модели классификации из scikit-learn.
Во-первых, давайте импортируем все важные пакеты.
from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer from combo.models.classifier_stacking import Stacking from combo.utils.data import evaluate_print
Далее давайте рассмотрим отдельный классификатор для прогнозирования цели.
# Define data file and read X and y
random_state = 42
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4,
random_state=random_state)
# initialize a group of clfs
classifiers = [DecisionTreeClassifier(random_state=random_state),
LogisticRegression(random_state=random_state),
KNeighborsClassifier(),
RandomForestClassifier(random_state=random_state),
GradientBoostingClassifier(random_state=random_state)]
clf_names = ['DT', 'LR', 'KNN', 'RF', 'GBDT']
# evaluate individual classifiers
for i, clf in enumerate(classifiers):
clf.fit(X_train, y_train)
y_test_predict = clf.predict(X_test)
evaluate_print(clf_names[i] + ' | ', y_test, y_test_predict)
print()

Далее давайте взглянем на модель Stacking с использованием пакета Combo.
# build a Stacking model and evaluate
clf = Stacking(classifiers, n_folds=4, shuffle_data=False,
keep_original=True, use_proba=False,
random_state=random_state)
clf.fit(X_train, y_train)
y_test_predict = clf.predict(X_test)
evaluate_print('Stacking | ', y_test, y_test_predict)
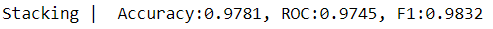
Улучшение есть, но, безусловно, есть место для другого эксперимента. Вы можете попробовать любую комбинацию, которую считаете необходимой, используя пакет.
22. ПыАзтро
Вам нужны данные гороскопа или вам просто интересно, как вам сегодня повезло? Тогда вы можете использовать PyAztro для достижения этой цели! Пакет содержит уникальную информацию, такую как счастливые числа, счастливые знаки, настроение и многое другое. Попробуем использовать пакет, установив его.
pip install pyaztro
Тогда мы могли бы попытаться получить доступ к сегодняшнему гороскопу с помощью следующего кода.
import pyaztro pyaztro.Aztro(sign='gemini').description

23. Факер
Faker — это пакет Python для упрощения генерации синтетических данных. Многие разработчики используют этот пакет для создания еще одного пакета генератора синтетических данных. Чтобы использовать пакет, давайте установим его.
pip install Faker
Чтобы использовать пакет Faker для генерации синтетических данных, нам нужно инициировать класс Faker.
from faker import Faker fake = Faker()
Например, мы могли бы создать синтетическое имя данных с инициированным классом.
fake.name()

Faker будет генерировать синтетические данные случайным образом каждый раз, когда мы запускаем атрибут .name из класса Faker. Есть еще много атрибутов, которые вы можете попробовать использовать для генерации данных.
24. Ярмарка
Fairlearn — это пакет Python для оценки и смягчения несправедливости в моделях машинного обучения. Пакет предоставил множество API, которые были необходимы для проверки смещения, чтобы мы могли его избежать. Чтобы попробовать пакет, давайте сначала начнем его установку.
pip install fairlearn
Затем мы могли бы использовать набор данных Fairlearn, чтобы увидеть, насколько предвзята модель. В учебных целях мы бы упростили предсказание модели.
from fairlearn.metrics import MetricFrame, selection_rate
from fairlearn.datasets import fetch_adult
data = fetch_adult(as_frame=True)
X = data.data
y_true = (data.target == '>50K') * 1
sex = X['sex']
selection_rates = MetricFrame(metrics=selection_rate,
y_true=y_true,
y_pred=y_true,
sensitive_features=sex)
fig = selection_rates.by_group.plot.bar(
legend=False, rot=0,
title='Fraction earning over $50,000')

В Fairlearn API есть функция selection_rate, которую мы могли бы использовать для обнаружения разницы в долях между прогнозами групповой модели, чтобы мы могли видеть, как смещение от результата.
25. тиобеиндекспи
tiobeindexpy — это простой пакет Python для получения данных индекса TIOBE. Индекс TIOBE — это данные рейтинга программирования, и за ними может быть важно следить, поскольку мы не хотим пропустить следующее событие в мире программирования.
Чтобы использовать tiobeindexpy, нам нужно сначала установить его.
pip install tiobeindexpy
Тогда мы могли бы попасть в топ-20 рейтинга языков программирования в текущем месяце, используя следующий код.
from tiobeindexpy import tiobeindexpy as tb df = tb.top_20()

26. питтренды
pytrends — это пакет Python для получения популярных ключевых слов в Google с использованием их API. Пакет полезен, когда мы хотим быть в курсе текущих веб-тенденций или тенденций, связанных с нашим ключевым словом. Чтобы использовать пакет, нам нужно сначала установить его.
pip install pytrends
Допустим, я хочу узнать текущую тенденцию, связанную с ключевым словом «Подарок», тогда я буду использовать следующий код, чтобы узнать текущую тенденцию.
from pytrends.request import TrendReq import pandas as pd pytrend = TrendReq() keywords = pytrend.suggestions(keyword='Present Gift') df = pd.DataFrame(keywords) df

Пакет вернет 5 основных тенденций, связанных с ключевым словом.
27. видения
visions — это пакет Python для семантического анализа данных. Пакет может определять типы фреймов данных и делать выводы о том, какими должны быть данные столбца. Он предназначен для автоматизации вывода данных и снижения сложности работы. Начнем с установки пакета.
pip install visions
Затем мы могли бы использовать следующий код для определения типа данных столбцов в фрейме данных с помощью видений. Я бы использовал титанический набор данных с морского рожденья.
import seaborn as sns
from visions.functional import detect_type, infer_type
from visions.typesets import CompleteSet
df = sns.load_dataset('titanic')
typeset = CompleteSet()
# Inference works well even if we monkey with the data, say by converting everything to strings
print(detect_type(df, typeset))

28. Расписание
Schedule — это пакет Python для создания функции планирования заданий для любого кода. Он предназначен для простого использования пользователями, чтобы запланировать все, что они хотят, в период повторения, который вы можете установить. Начнем с установки пакета.
pip install schedule
Например, я хочу распечатать, что я работаю каждые 10 секунд. Тогда я бы использовал следующий код для этого.
import schedule
import time
def job():
print("I'm working...")
schedule.every(10).seconds.do(job)
while True:
schedule.run_pending()
time.sleep(1)

29. автокоррекция
autocorrect — это пакет Python для исправления текстовой орфографии, доступный на многих языках. Использование простое, но очень полезное для процесса очистки данных. Начнем с установки пакета.
pip install autocorrect
Затем мы могли бы использовать пакет автозамены, аналогичный следующему коду.
from autocorrect import Speller
spell = Speller()
spell("I'm not sleaspy and tehre is no place I'm giong to.")

30. веселый
funcy — это пакет Python, полный модных практических функций для повседневного использования анализа данных. В пакете так много функций, что я не могу показать все, а для облегчения есть шпаргалка. Начнем с установки пакета.
pip install funcy
Я бы показал только пример функции для выбора четного числа из итерируемой переменной, показанной в следующем коде.
from funcy import select, even
select(even, {i for i in range (20)})

31. Мороженое
IceCream — это пакет Python, используемый для печати, но упрощающий процесс отладки. По сути, пакет обеспечивает несколько более подробный вывод в процессе печати/регистрации.
Чтобы использовать пакет, нам нужно установить его, используя следующий код.
pip install icecream
Затем мы можем использовать пакет со следующим кодом.
from icecream import ic
def some_function(i):
i = 4 + (1 * 2)/ 10
return i + 35
ic(some_function(121))

Функцию также можно использовать в качестве инспектора функций.
def foo():
ic()
if some_function(12):
ic()
else:
ic()
foo()

Уровень детализации очень хорош для любой цели анализа данных, которую мы делали.
Заключение
В этой статье мы рассмотрели 31 уникальный пакет Python, которые будут полезны в рабочем процессе данных. Большинство пакетов просты в использовании и понятны, но некоторые из них могут потребовать дополнительного чтения.
Я надеюсь, что это помогает!
Заходите ко мне в Социальные сети, чтобы обсудить более подробно или задать вопросы.
Если вы не подписаны как участник Medium, рассмотрите возможность подписки через моего реферала.