Научитесь управлять выводом модели на основе того, что важно для проблемы, используя матрицу путаницы.
Освойте основы матрицы путаницы с помощью Sklearn и создайте практическую интуицию для трех наиболее распространенных показателей, используемых в двоичной классификации: точность, полнота и оценка F1.

Введение
Классификация — важная часть машинного обучения. Его преимущества и области применения безграничны — от обнаружения новых астероидов и планет до выявления раковых клеток, и все они выполняются с использованием алгоритмов классификации.
Тип решаемых классификаций задач делится на два: неконтролируемые и контролируемые. Неконтролируемые классификаторы обычно представляют собой нейронные сети и могут обучаться на неструктурированных данных, таких как видео, аудио и изображения. Напротив, контролируемые модели работают с помеченными табличными данными и являются частью классического машинного обучения. В центре внимания этой статьи последнее; в частности, мы будем исследовать то, что общего у всех задач контролируемой классификации: матрицы путаницы.
Получите лучшие и последние статьи по машинному обучению и искусственному интеллекту, выбранные и обобщенные с помощью мощного искусственного интеллекта — альфа-сигнала:
Разработка конвейера предварительной обработки классификации
Хорошая модель нуждается в хороших данных. Таким образом, важно максимально обработать доступную информацию, чтобы добиться наилучшей производительности модели, даже до ее настройки на основе матриц путаницы.
Типичный рабочий процесс предварительной обработки включает в себя работу с отсутствующими значениями, масштабирование/нормализацию числовых признаков, кодирование категориальных переменных и выполнение всех других необходимых шагов проектирования признаков. Мы увидим пример этого в этом разделе.
Мы будем прогнозировать одобрение кредитных карт, используя Набор данных одобрения кредитных карт из репозитория машинного обучения UCI. Прежде чем банки смогут выдавать кредитные карты новым клиентам, необходимо учитывать множество факторов: уровень доходов, остатки по кредитам, индивидуальные кредитные отчеты и т. д. Часто это сложная и рутинная задача, поэтому в настоящее время банки используют алгоритмы машинного обучения. Взглянем на данные:
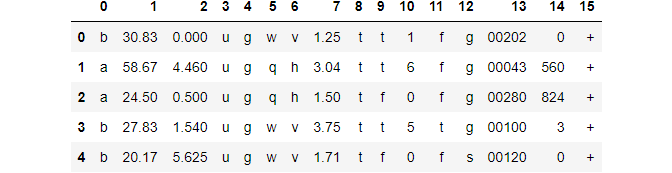
Поскольку это частные данные, имена функций остаются пустыми. Сначала исправим это:
Набор данных содержит как числовые, так и категориальные признаки. Отсутствующие значения в этом наборе данных закодированы вопросительными знаками (?). Мы заменим их на NaNs:
Функции 0, 1, 3, 4, 5, 6 и 13 содержат пропущенные значения. Изучив данные, мы можем предположить, что функция 13 содержит почтовые индексы, а значит, мы можем ее удалить. А для других, поскольку они составляют менее 5% набора данных, мы также можем удалить эти строки:
Мы не использовали методы вменения из-за небольшого количества нулей. Если вы хотите узнать о других надежных методах вменения, эта статья поможет:
Теперь сосредоточимся на числовых значениях. В частности, мы рассмотрим их распределения:
>>> df.describe().T.round(3)
Все функции имеют минимум 0, но все они находятся в разных масштабах. Это означает, что мы должны использовать некоторую нормализацию, и мы увидим, какую именно, визуально изучив эти функции:
import seaborn as sns>>> df.hist();

Функции имеют асимметричное распределение, что означает, что мы будем выполнять нелинейное преобразование, такое как PowerTransformer (под капотом используются логарифмы):
Если вы хотите узнать больше о других методах преобразования числовых признаков, я также рассказал об этом:
Для кодирования категориальных признаков мы будем использовать OneHotEncoder. Прежде чем изолировать столбцы, которые будут использоваться при кодировании, давайте разделим данные на функции и целевые массивы:
Теперь изолируйте категориальные столбцы для кодирования OH:
Наконец, мы построим конвейер предварительной обработки:
Введение в матрицу путаницы
На последнем шаге я добавил RandomForestClassifier в конвейер в качестве базовой модели. Мы хотим, чтобы модель более точно предсказывала одобренные заявки, потому что это означало бы, что у банка будет больше клиентов. Это также сделает одобренные приложения положительным в наших прогнозах. Давайте, наконец, оценим конвейер:
Оценка по умолчанию для всех классификаторов — это оценка точности, в которой наш базовый конвейер впечатляюще достиг ~87%.
Но вот проблема с точностью — насколько модель точна? Может ли он лучше предсказывать подходящие приложения или точнее обнаруживать нежелательные кандидаты? Ваши результаты должны отвечать на оба вопроса с точки зрения бизнеса, а точность этого не делает.
В качестве решения давайте, наконец, познакомимся с матрицей путаницы:
Поскольку это проблема бинарной классификации, матрица имеет форму 2x2 (два класса в цели). Диагональ матрицы показывает количество правильно классифицированных выборок, а недиагональные ячейки показывают, где модель допустила ошибку. Для понимания матрицы Sklearn предоставляет наглядную, которая намного лучше:

Эта матрица путаницы гораздо более информативна. Вот несколько вещей, на которые стоит обратить внимание:
- Строки соответствуют фактическим значениям
- Столбцы соответствуют прогнозируемым значениям
- Каждая ячейка представляет собой количество каждой комбинации истинного/прогнозируемого значения.
Обращая внимание на метки осей, первая строка представляет фактический отрицательный класс (отклоненные заявки), а вторая строка — фактический положительный класс (одобренные заявки). Точно так же первый столбец предназначен для положительного предсказания, а второй - для отрицательного предсказания.
Прежде чем мы перейдем к интерпретации этого вывода, давайте исправим формат этой матрицы. В другой литературе вы можете увидеть, что фактический положительный класс представлен в первой строке, а прогнозируемый положительный класс — в первом столбце. Я тоже привык к этому формату, и мне легче объяснить.
Мы перевернем матрицу так, чтобы первая строка и столбец были положительным классом. Мы также будем использовать функцию Sklearn ConfusionMatrixDisplay, которая строит пользовательские матрицы. Вот функция-оболочка:

Мы переворачиваем матрицу с помощью np.flip и строим ее с помощью ConfusionDisplayFunction, которая принимает только матрицу и принимает пользовательские метки классов через параметр display_labels.
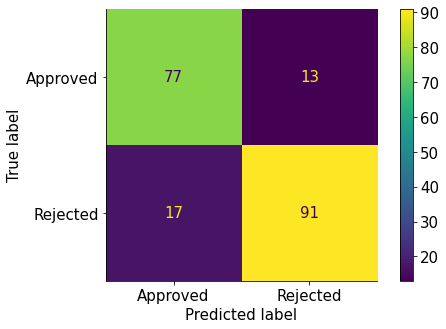
Давайте, наконец, интерпретируем эту матрицу:
- (вверху слева) — 78 заявок были фактически одобрены, и модель правильно классифицировала их как одобренные
- (внизу справа) — 95 заявок были фактически отклонены, и модель правильно классифицировала их как отклоненные
- (внизу слева) — 13 заявок были фактически отклонены, но модель неправильно классифицировала их как одобренные
- (вверху справа) — 12 заявок были фактически одобрены, но модель неправильно классифицировала их как отклоненные.
Из-за популярности матриц путаницы каждая комбинация истинных и предсказанных ячеек имеет в сообществе собственное имя:
- Истинно положительные результаты (TP) — фактические положительные результаты, прогнозируемые положительные результаты (вверху слева, 78)
- True Negatives (TN) — фактическое отрицательное значение, прогнозируемое отрицательное значение (внизу справа, 95)
- Ложноположительные результаты (FP) — фактические отрицательные, прогнозируемые положительные (внизу слева, 13)
- Ложноотрицательные результаты (FN) — фактически положительный результат, прогнозируемый отрицательный результат (вверху справа, 12)
Несмотря на то, что вы можете увидеть матрицу в другом формате, указанные выше четыре термина всегда будут там. Вот почему перед созданием модели полезно создать мысленную пометку о том, к чему относятся приведенные выше четыре термина в вашем уникальном случае.
После того, как вы подберете модель, вы можете извлечь каждое из 4 вышеперечисленных, используя метод .ravel() на матрице путаницы:
Точность, отзыв и баллы F
В этом разделе мы узнаем о метриках, которые позволяют нам дополнительно сравнивать одну матрицу путаницы с другой. Допустим, у нас есть еще один конвейер с LogisticRegression в качестве классификатора:

Глядя на графики выше, мы можем сказать, что результаты как случайных лесов, так и логистической регрессии схожи. Однако есть три общих показателя, которые мы можем получить из матрицы путаницы, что позволяет нам сравнивать их. Они называются точность, отзыв и оценка F1. Давайте разберемся с каждым подробно:
- Точность – это отношение количества правильно классифицированных положительных результатов к общему количеству предсказанных положительных классов. В нашем случае это общее количество правильно классифицированных одобренных заявок (TP = 77), деленное на общее количество прогнозируемых одобренных классификаций (все прогнозируемые положительные результаты, независимо от того, верны они или нет, ТП + ФП = 94). Используя термины матрицы, это:

Вы можете легко запомнить это с помощью правила Triple-P — точность включает в себя все положительные значения и использует термины в левой части матрицы.
Официальное определение точности, данное Склеарном, звучит так: «способность классификатора не маркировать отрицательный образец как положительный». В нашем случае это способность нашей модели не помечать отклоненные заявки как одобренные. Таким образом, если мы хотим, чтобы модель более точно отфильтровывала неподходящие приложения, мы должны оптимизировать точность. Другими словами, максимально увеличьте количество истинных срабатываний и уменьшите количество ложных срабатываний. 0 Ложные срабатывания дают точность 1.
- Отзыв: чувствительность, частота попаданий или истинная положительная частота (TPR). Это отношение правильно классифицированных положительных результатов к общему количеству фактических положительных результатов в цели. В нашем случае это количество правильно классифицированных одобренных заявок (TP = 77), деленное на общее количество действительно одобренных заявок (независимо от того, были ли они правильно предсказаны). или нет, ТП + ФН = 90). Используя термины матрицы путаницы:

Напомним, использует термины в первой строке матрицы путаницы.
Официальное определение Sklearn для отзыва: способность классификатора найти все положительные образцы. Если мы оптимизируем для отзыва, мы уменьшим количество ложноотрицательных (неправильно классифицированных, одобренных приложений) и увеличим количество истинных срабатываний. Но это может быть ценой роста ложных срабатываний — т.е. е. некорректная классификация отклоненных заявок как одобренных.
По своей природе Precision и Recall находятся в компромиссных отношениях. В зависимости от вашей бизнес-задачи вам, возможно, придется сосредоточиться на оптимизации одной за счет другой. Однако что, если вам нужна сбалансированная модель, т. е. модель, которая одинаково хорошо выявляет как положительные, так и отрицательные стороны.
В нашем случае это имело бы смысл — банк выиграл бы больше всего, если бы смог найти как можно больше клиентов, избегая при этом нежелательных кандидатов, тем самым устраняя потенциальные потери.
- Третья метрика, называемая показатель F1, пытается измерить именно это: она количественно определяет способность модели правильно прогнозировать оба класса. Он рассчитывается путем использования среднего гармонического значения точности и отзыва:

Вы спросите, почему гармоническое среднее? Из-за того, как оно рассчитывается, среднее гармоническое действительно дает сбалансированную оценку. Если либо точность, либо полнота имеют низкое значение, оценка F1 значительно страдает. Это полезное математическое свойство по сравнению с простым средним значением.
Все эти показатели можно рассчитать с помощью Sklearn, и они доступны в подмодуле metrics:
RandomForest имеет большую точность, что указывает на то, что он лучше находит одобряемые приложения при снижении ложных срабатываний, т.е. е. неправильно классифицированные нежелательные кандидаты.
RandomForests также выигрывает в отзыве. Точно так же он лучше отфильтровывает ложноотрицательные результаты, т.е. е., уменьшая количество положительных образцов, классифицированных как отрицательные. Поскольку RandomForests выиграл в обоих случаях, мы можем ожидать, что у него также будет более высокий F1:
Как и ожидалось, RF имеет более высокую F1, что делает ее более надежной моделью для нашего случая.
Вы можете распечатать все эти оценки сразу, используя функцию classification_report:
Прежде чем мы сосредоточимся на оптимизации этих показателей, давайте рассмотрим другие сценарии, чтобы углубить наше понимание.
Больше практики в интерпретации точности, отзыва и F1
Поскольку различия между этими метриками незначительны, вам потребуется некоторая практика, чтобы выработать для них сильную интуицию. В этом разделе мы сделаем именно это!
Допустим, мы пытаемся определить, являются ли парашюты, продаваемые в парашютном магазине, неисправными. Помощник проверяет все доступные парашюты, записывает их характеристики и классифицирует их. Мы хотим автоматизировать этот процесс и построить модель, которая должна исключительно хорошо обнаруживать неисправные парашюты.
Например, мы создадим набор данных синтетически:
Поскольку работающих парашютов намного больше, это проблема несбалансированной классификации. Настроим терминологию:
- Положительный класс: дефектные парашюты
- Отрицательный класс: рабочие парашюты
- Истинные положительные стороны: неисправные парашюты были предсказаны правильно
- Истинные минусы: правильно спрогнозированы рабочие парашюты
- Ложные срабатывания: неисправные парашюты спрогнозированы неправильно
- Ложноотрицательные результаты: рабочие парашюты спрогнозированы неверно
Давайте оценим модель случайного леса на этих данных:

В этой задаче мы должны попытаться максимально опустить правый верхний (False Negatives), потому что даже один неисправный парашют означает смерть парашютиста. Глядя на оценки, мы должны оптимизировать оценку отзыва:
Совершенно нормально, если количество ложных срабатываний увеличится, потому что мы спасем жизни людей, даже если потеряем немного денег.
Во втором сценарии мы попытаемся спрогнозировать отток клиентов (прекратить или продолжить пользоваться услугами нашей компании). Опять же, давайте настроим терминологию для проблемы:
- Положительный класс: продолжайте использовать
- Отрицательный класс: отток
- Истинные положительные стороны: хочет продолжать, предсказано правильно
- Истинные негативы: отток, предсказанный правильно
- Ложные срабатывания: отток, неверно предсказанный
- Ложноотрицательные результаты: хочет продолжать, неверно предсказано
Мы снова построим синтетический набор данных и оценим на нем RF:

В этом случае мы хотим сохранить как можно больше клиентов. Это означает, что мы должны снизить количество ложных срабатываний, что указывает на то, что мы должны оптимизировать точность:
В этой статье мы сосредоточились только на трех показателях. Тем не менее, вы можете получить многие другие оценки из матрицы путаницы, такие как специфичность, NPV, FNR и т. д. После прочтения этой статьи вы сможете прочитать страницу Википедии по этой теме. Если вы не уверены в метриках, прочтите и эту потрясающую статью.
Наконец, давайте посмотрим, как оптимизировать каждую из метрик, которые мы обсуждали сегодня.
Оптимизация моделей для конкретной метрики с помощью HalvingGridSearchCV
В этом разделе мы увидим, как повысить производительность модели для выбранной нами метрики. В предыдущих разделах мы использовали модели с параметрами по умолчанию. Чтобы повысить их производительность, мы должны выполнить настройку гиперпараметров. В частности, мы должны найти гиперпараметры, которые дают наивысший балл для нашей желаемой метрики.
Искать этот волшебный набор утомительно и долго. Итак, мы создадим класс HalvingRandomSearchCV, который исследует сетку возможных параметров модели и находит набор, который дает наивысший балл для функции оценки, переданной его параметру scoring.
Вы можете быть удивлены, что я не использую GridSearch. В одной из своих статей я показал, что поиск по сетке в два раза быстрее, чем обычный поиск по сетке в 11 раз. А поиск по сетке в два раза быстрее, что позволяет нам значительно расширить пространство гиперпараметров. Сравнение можно прочитать здесь:
В качестве первого шага мы построим пространство гиперпараметров:
Теперь мы будем искать в этой сетке три раза, оптимизируя каждую из метрик, которые мы обсуждали сегодня:
Мы набрали более высокие баллы по точности, но получили более низкие баллы по отзывам и F1. Это повторяющийся процесс, поэтому вы можете продолжать поиск, пока не улучшатся результаты. Или, если у вас есть время, вы можете перейти на HalvingGridSearch, который намного медленнее, чем HalvingRandomSearch, но дает гораздо лучшие результаты.
Краткое содержание
Самая сложная часть любой проблемы классификации — это понимание бизнес-задачи, которую вы пытаетесь решить, и соответствующая оптимизация метрики. После того, как вы теоретически построите соответствующую матрицу путаницы и ее элементы, останется только часть кодирования.
С точки зрения кодирования, наличие отличного конвейера предварительной обработки гарантирует, что вы получите максимально возможную оценку для выбранной вами базовой модели. Обязательно масштабируйте/нормализуйте данные на основе базовых распределений. После предварительной обработки создайте копии конвейера для нескольких классификаторов. Логистическая регрессия, случайные леса и классификатор KNN — хороший выбор.
Для оптимизации выберите Halving Grid или Halving Random Search. Было доказано, что они намного лучше, чем их предыдущие аналоги. Спасибо за прочтение!
Понравилась эта статья и, скажем прямо, ее причудливый стиль написания? Представьте себе, что у вас есть доступ к десяткам таких же, написанных блестящим, обаятельным, остроумным автором (кстати, это я :).
Всего за 4,99 $ членства вы получите доступ не только к моим историям, но и к сокровищнице знаний от лучших и самых ярких умов на Medium. А если вы воспользуетесь моей реферальной ссылкой, то получите мою сверхновую благодарность и виртуальную пятерку за поддержку моей работы.
