EvalRS: оценка рекомендательных систем во многих тестах
В этой статье описывается новый вызов данных и кода, который в настоящее время выполняется: EvalRS.
Мы решили организовать EvalRS с друзьями из Coveo, Microsoft и NVIDIA, чтобы лучше понять оценку в рекомендательных системах.
Присоединиться к вызову может любой желающий. Существуют призы за лучшие системы, лучшие идеи и лучшие студенческие работы. Также есть возможность представить системы на конференции CIKM.
Если вы заинтересованы в EvalRS и хотите присоединиться к соревнованию, вы можете перейти по этим ссылкам:
Эти сообщения в блоге охватывают общее введение, мотивацию и некоторый код Python для EvalRS.
Увертюра
Мы все любим RecSys.
Netflix, Spotify, LastFM, Amazon — всем нужны системы для улучшения пользовательского опыта и рекомендаций, чтобы эффективно предлагать товары. Действительно, если вы находитесь в сети, вы наверняка были в тесном контакте с рекомендательной системой. Кроме того, если вы читаете это сейчас, вы, вероятно, использовали систему средних рекомендаций!
Рекомендательные системы, вероятно, являются одной из самых популярных систем машинного обучения в производстве; более того, рекомендатели, вероятно, являются продуктами машинного обучения, которые имеют самый тесный контакт с реальными пользователями, поскольку они обычно используются в интерактивном режиме.
Вот почему тестирование имеет основополагающее значение в рекомендательных системах. Невыявление низкой эффективности в некоторых случаях может нанести репутационный ущерб компании.
Однако, с точки зрения разработки, тестирование рекомендателя очень сложно: онлайн или офлайн, поиск или ранжирование и так далее. Конечно, есть метрики оценки, как это принято в области машинного обучения.
Часто рекомендатели действительно оцениваются по стандартным точечным показателям, таким как HITS и MRR, которые обычно оценивают, насколько точны в среднем прогнозы на основе удерживаемых точек данных.
Вопрос в том, достаточно ли стандартных точечных метрик? Вероятно, нет.
Не поймите меня неправильно, эти показатели очень важны! Поскольку вам нужно использовать их, чтобы оценить, как ваш рекомендатель работает в среднем. Тем не менее, есть нечто большее, чем просто оценка средних показателей.
Например, некоторые рекомендации лучше других, как мы можем объяснить это? Как правило, оценка требует более детального подхода, при котором вы изучаете имеющиеся у вас данные.
В конце концов, вам нужно очень хорошо знать данные.
Округленная оценка?
«Округленная оценка»? Мой друг Джакопо рассказал об ограничениях стандартной оценки в своем блоге.
Здесь я кратко упомяну два аспекта оценки, которые важно учитывать:
- Производительность по срезам. Как только вы обучите свою модель, будет ли она одинаково хорошо работать на пользователях из Великобритании и США?
- Быть менее неправым. Когда вы предсказываете пользователю неправильный элемент, насколько вы ошибаетесь? Предлагать фильм ужасов пользователю, который хочет посмотреть беззаботный фильм, — плохая идея. Тем не менее, предложение комедии или романтического фильма может быть оценено по достоинству!
Наша задача EvalRS построена именно на этом образе мышления: оценка — это нечто большее, чем просто MRR и HITS. Поэтому мы сосредоточимся на оценке рекомендательных систем, используя более детальный подход.
У нас есть набор данных (см. следующие разделы) с множеством метаданных, которые можно изучать и анализировать с разных точек зрения.
RecList
Как мы можем быстро улучшить тестирование в рекомендательных системах? Для этого нам понадобится RecList. RecList — это новый пакет Python, который мы разработали для поддержки оценки рекомендательных систем.
RecList позволяет нам сосредоточиться на написании моделей и позволить автоматическим конвейерам выполнять оценку. Сценарии EvalRS построены поверх RecList, чтобы упростить задачу для участников.
Соревнование
Набор данных EvalRS и общая задача сосредоточены на наборе данных LastFM (Schedl, 2016), доступном для некоммерческих целей, который содержит взаимодействия между пользователями и песнями.
Эта задача сосредоточена на трех методологических столпах, которые важно описать:
Избегайте переобучения общедоступной таблицы лидеров
Если таблица лидеров является общедоступной и можно запустить несколько экспериментов, может быть легко просто найти лучшую конфигурацию, используя набор тестов в качестве руководства.
С этой целью вместо набора фиксированных тестов мы используем Bootstrapd k-fold CV. Это усложнит попадание в таблицу лидеров и позволит нам предложить лучшую методологию оценки.
Избегайте ансамблевых решений с высоким потреблением, которые невозможно развернуть
Поскольку это соревнование по коду, на последнем этапе оценки будет предоставлен фиксированный бюджет вычислений. Это позволяет нам оценивать рекомендательные системы, которые можно использовать и развертывать на практике.
Избегайте погони за одним показателем
Мы стандартизировали эталонный тест с множеством показателей, включая объективность и поведенческое тестирование. Это сделает нашу оценку более полной.
Используя эту настройку, мы надеемся обеспечить сопоставимость и справедливость результатов.
Набор данных
Набор данных LastFM содержит 37 миллионов взаимодействий и богат метаданными. Задачей будет «предлагать пользователям новые треки для прослушивания».
Для пользователей у нас есть демографическая информация, пол (бинарный), время регистрации и многие другие дополнительные функции.

Для каждой дорожки у нас есть доступ к исполнителям и альбомам, поэтому мы можем изучать шаблоны более высокого уровня (например, мы можем подсчитать, сколько альбомов есть у исполнителя, и использовать это как дополнительную функцию для нашей модели).

Наконец, самая ценная часть всего набора данных. Взаимодействие. Эта часть данных содержит взаимодействие между пользователями и дорожками с отметкой времени, когда пользователь прослушал песню. Это будет нашим основным элементом при создании нашего рекомендателя.

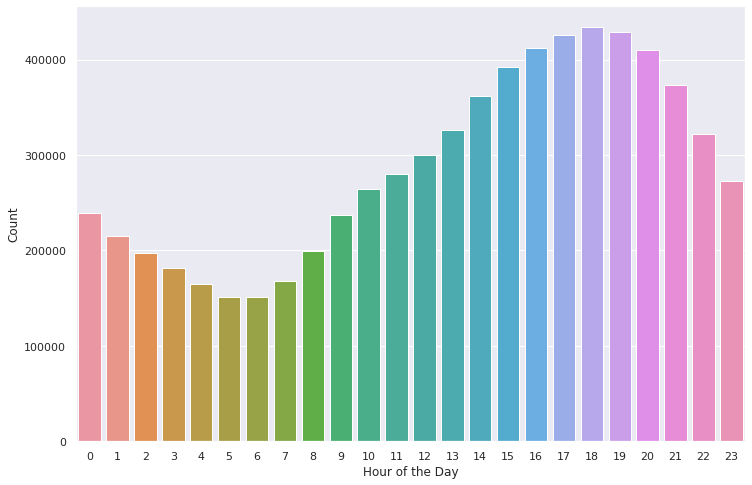
Набор данных очень интересен: объем доступной информации гарантирует, что можно многое сделать для решения задач оценки. Например, посмотрите на распределение потребления музыки по часам дня.
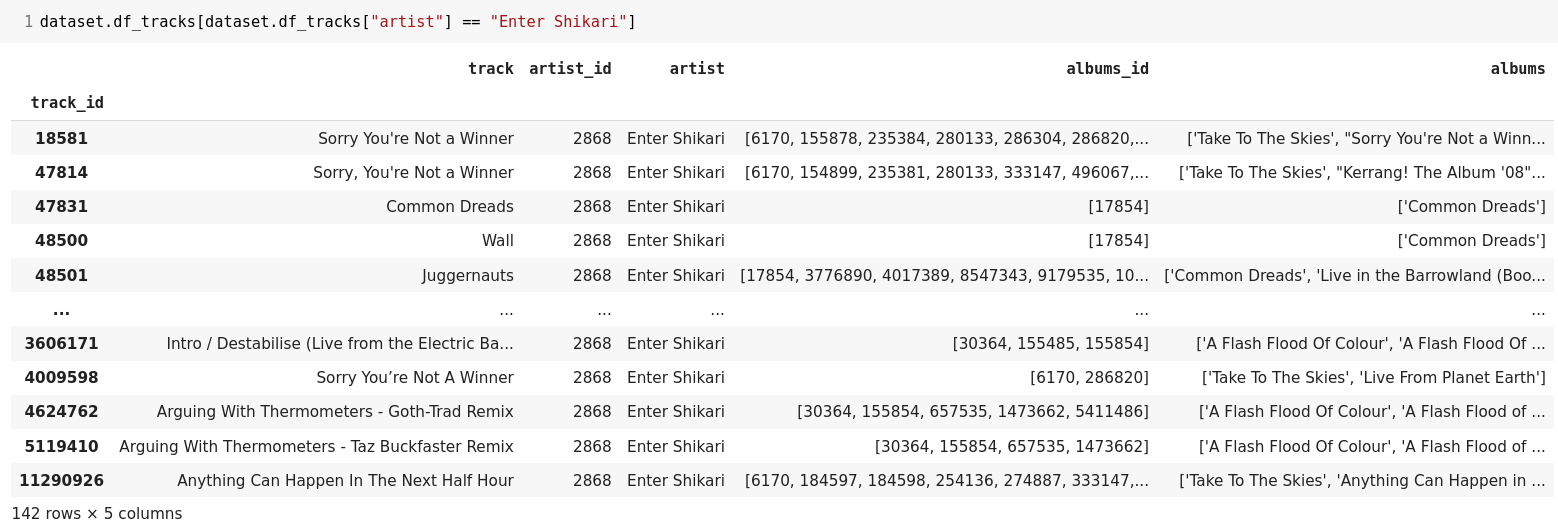
Мы также можем изучить набор данных и посмотреть, какие песни у нас есть. Мне лично нравится «Enter Shikari», и с помощью быстрого поиска панд я могу найти все песни, которые были включены в этот набор данных.
Проблемный подход
Благодаря RecList и нашим оболочкам вам не нужно писать много кода. Вам просто нужно разработать свою модель. Если ваша модель соответствует нашему API, все готово. Сценарий оценки примет вашу модель на вход и обработает все процессы за вас.

Получив модель, вы можете просто передать ее нашим высокоуровневым API. Они позаботятся об обучении и оценке для вас и дадут вам результаты. Он также позаботится о том, чтобы занести результаты в таблицу лидеров!
Наш оценщик проведет несколько тестов. От тестов на разделе до тестов на фактическое разнообразие и качество ваших рекомендаций (например, на то, что они менее ошибочны).
RecSys на основе CBOW
Попробуем решить задачу! Мы создадим очень простой базовый план на основе Word2Vec, назовем его CBOWRecSys.
Скрытое пространство
Давайте сначала начнем с нашего скрытого пространства.
Наша CBOWRecSys будет использовать алгоритм CBOW для внутреннего использования: мы, по сути, воспринимаем взаимодействие пользователей с дорожками в последовательном порядке. Затем мы запускаем Word2Vec на этом «корпусе».
Будем надеяться, что совпадение позволит нам узнать надежное векторное пространство, в котором сходные песни находятся близко друг к другу в пространстве.

Имеет ли это пространство смысл? ну, давайте посмотрим… Мы можем спросить у модели, какие песни больше всего похожи на «Sorry You’re Not a Winner» (id 18581 в наборе данных) от Enter Shikari.

Все это имеет смысл! Так как все они песни Enter Shikari.
Один момент, который можно было бы обсудить, заключается в том, что в этом пространстве мало разнообразия: что, если бы я хотел песню, похожую на Sorry You’re Not a Winner, но не на Enter Shikari? Ну, это что-то более сложное, но это то, что мы пытались смоделировать в задаче; подробнее об этом здесь.
CBOWRecSys
Наконец, мы можем обсудить наш рекомендатель. CBOWRecSys будет очень простым из-за времени вычислений. Для каждого пользователя мы:
- случайным образом выбрать набор треков из своей истории прослушивания;
- генерируют представление пользовательского вектора, используя среднее значение векторов дорожек;
- искать наиболее похожие треки на представления пользователей.

Кодирование
Хорошо, давайте быстро рассмотрим реализацию этой модели. Код комментируется и имитирует процесс, который мы только что обсуждали. Вы также можете посмотреть это прямо в Kaggle Notebook.
Вы видите, что код очень прост. Единственное, о чем нам действительно нужно позаботиться, — это оператор return в прогнозе. Нам нужно вернуть pandas DataFrame, в котором есть строка для каждого пользователя и 100 столбцов с лучшими рекомендациями для каждого пользователя.
Выполнение оценки
Когда у нас есть модель, запустить оценку очень просто. Для этого у нас есть класс-оболочка. Вы можете увидеть результаты, прокомментированные ниже.
Эта простая модель уже показывает хорошие результаты на некоторых тестах. Например, у нас есть HITS@100 0,01816 при первом сгибе. Это не так уж плохо, учитывая 1) насколько велик набор данных и 2) насколько просто реализована базовая линия.
Заявка появится в таблице лидеров.
Заключение
Весь код вы найдете на стартовом Kaggle блокноте! приходите и присоединяйтесь к вызову! Вы можете получить возможность представить свою работу на конференции высшего уровня, познакомиться с новыми людьми в сообществе RecSys, поделиться своими идеями с помощью открытого исходного кода и, конечно же, выиграть приз: мы награждаем хорошо работающие модели, а также новые идеи для тестирования. и выдающиеся студенческие работы
Модель, которую мы определили, была довольно простой. Однако наш друг Габриэль из NVIDIA предоставил реализацию системы двух башен, которую вы можете использовать, чтобы принять участие в соревновании. Это хорошая отправная точка, если вы хотите запустить GPU и внедрить рекомендацию по глубине!
Благодарности
Я хотел бы поблагодарить наших спонсоров Comet, Neptune и Gantry за дальнейшее развитие RecList.