
На каждой конференции по искусственному интеллекту (ИИ), которую я посещаю, спикер упоминает: «Люди всегда спрашивают меня, собирается ли ИИ захватить мир/наши рабочие места?»
Это подчеркивает важность понимания грамотности ИИ не только для того, чтобы уменьшить количество людей, у которых есть такие неправильные представления, но и для того, чтобы позволить людям понять ограничения ИИ, чтобы они могли задавать более правильные вопросы при работе с ИИ.
Поэтому на недавнем семинаре «Учительская конференция» я перешел от разговора о том, как компьютерное зрение может помочь в переработке, к короткому уроку по грамотности в области ИИ.
Чтобы установить контекст, участники семинара не имели предыдущего/поверхностного опыта в области искусственного интеллекта и машинного обучения (ML). На этом семинаре я представил Teachable Machine — веб-инструмент, который делает создание моделей машинного обучения быстрым, простым и доступным для всех. Вы можете нажать на ссылку ниже, чтобы изучить их веб-сайт или посмотреть видео на YouTube ниже.
Мы исследовали создание проекта изображения в Teachable Machine, чтобы мы могли выполнять классификацию изображений. Мы предоставили участникам несколько упаковочных коробок Hello Panda разных цветов и предоставили несколько пластиковых бутылок для обучения их моделей.
На следующих изображениях показан процесс обучения модели. Он обучается в браузере, поэтому простого подключения к Интернету и браузера на ноутбуке/ПК будет достаточно. Никаких специальных приложений не требуется.
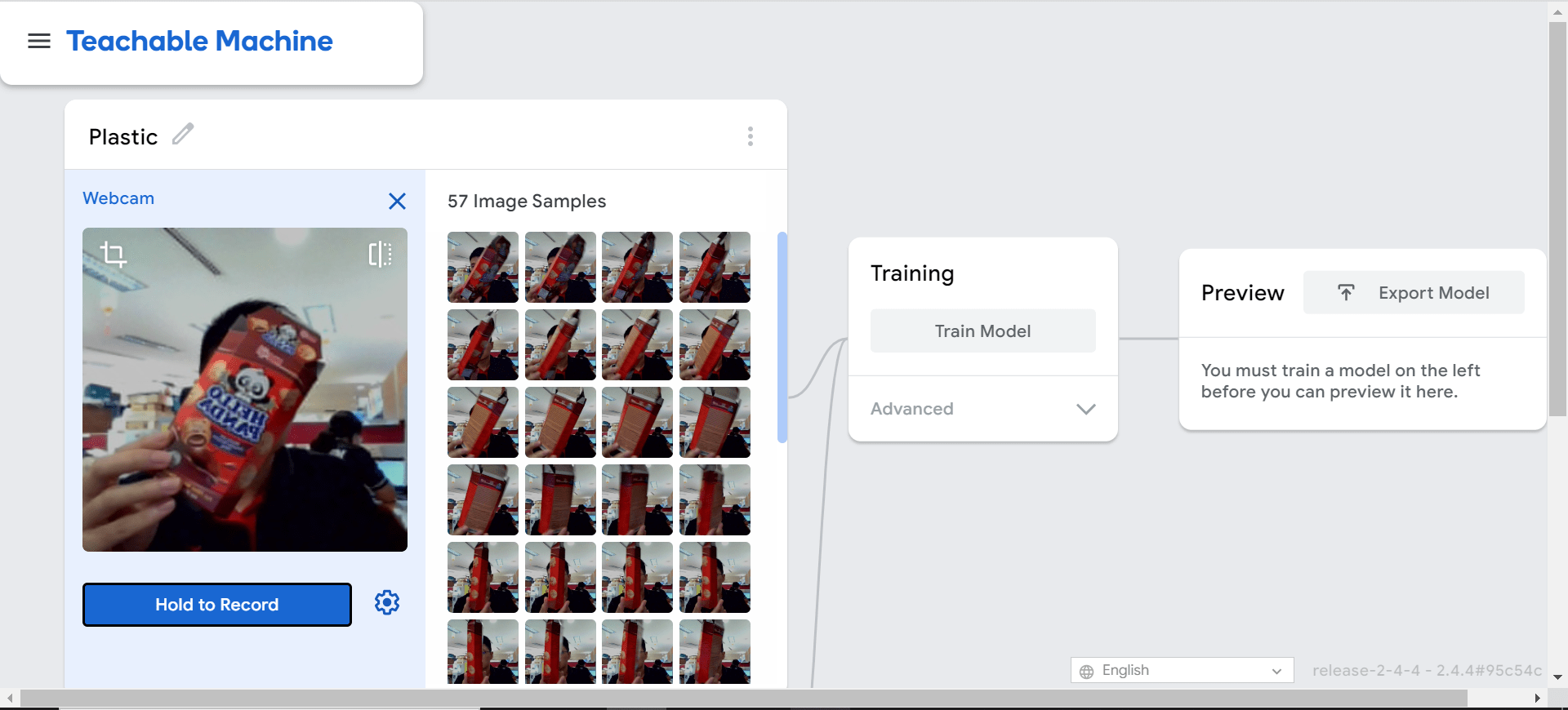
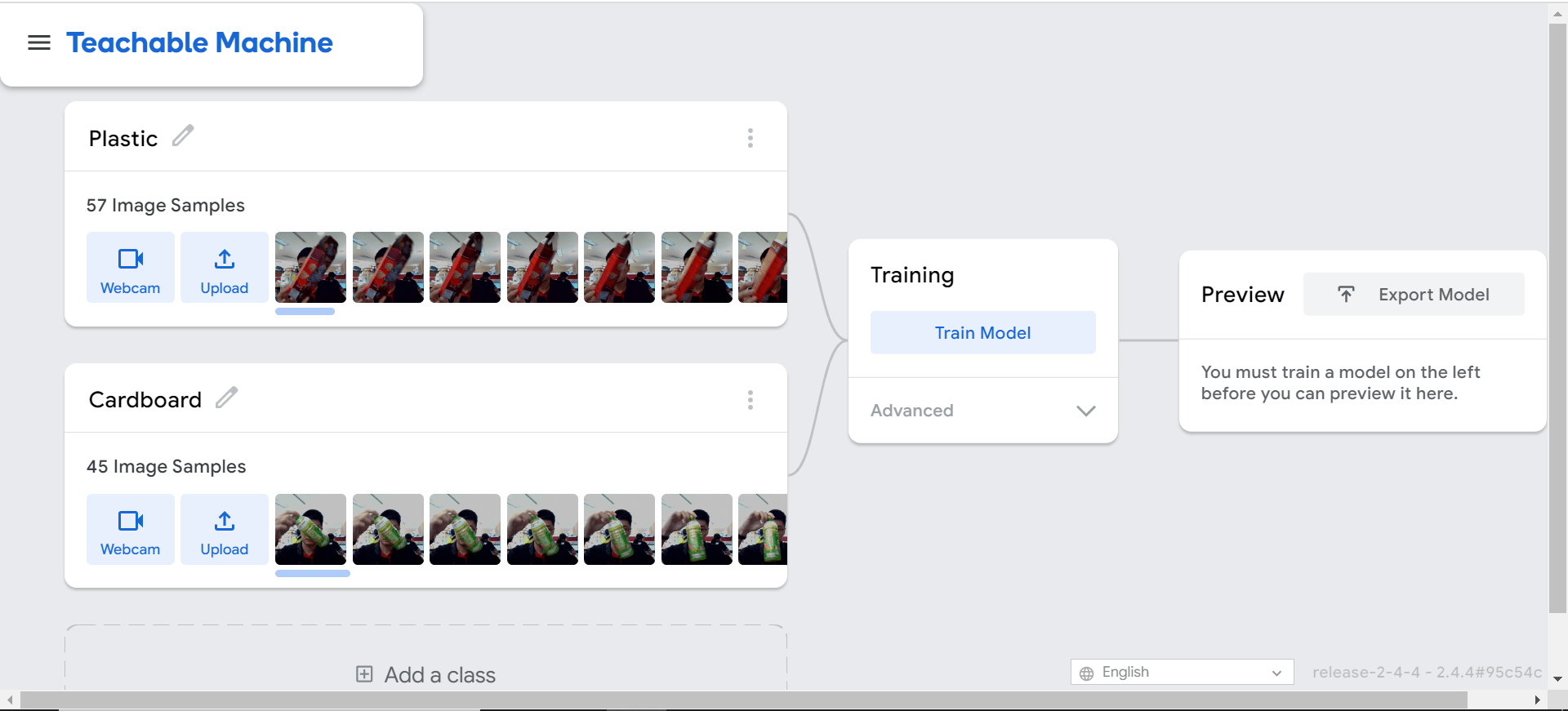
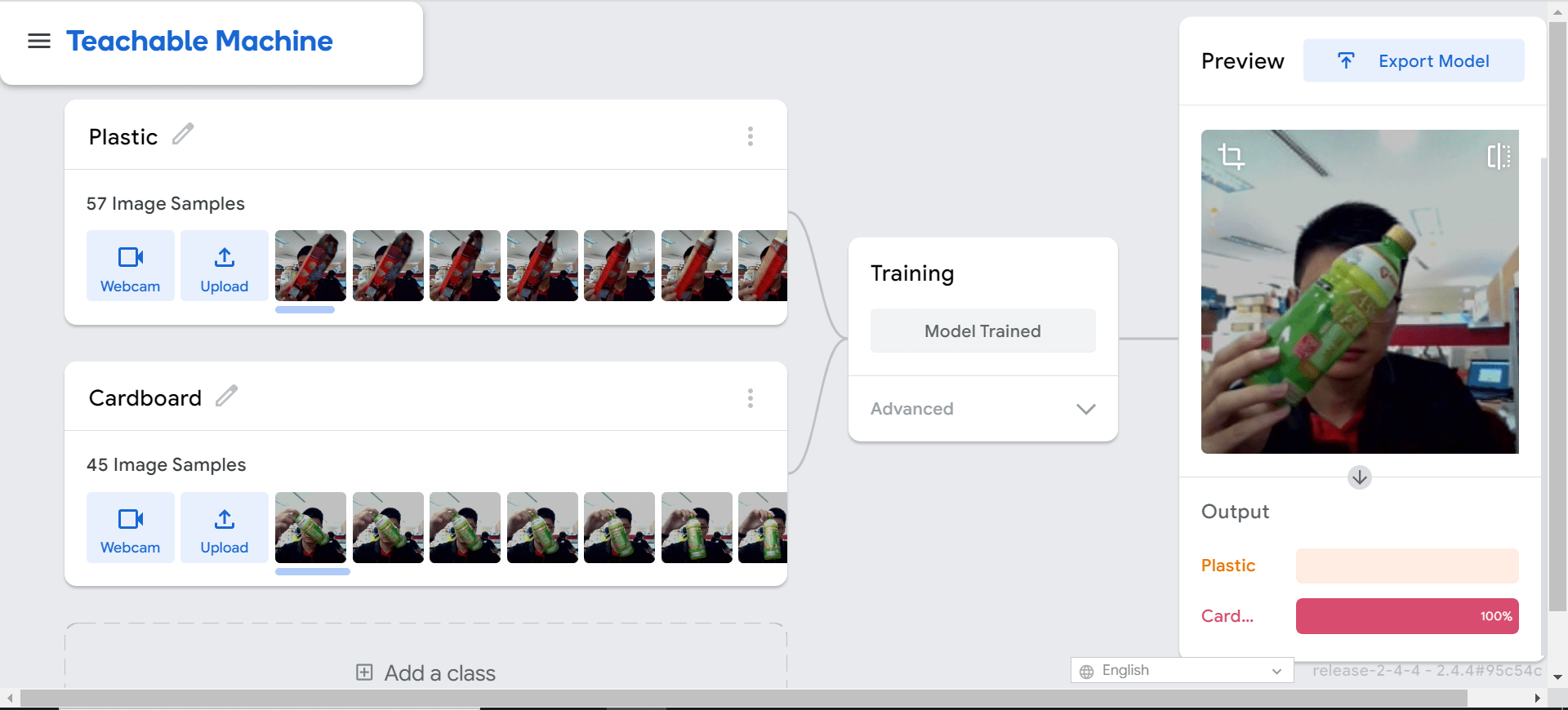
Первоначально участники следовали инструкциям и обучались обращению с пластиковыми бутылками и картонной упаковкой. И они начали сканировать другие предметы, которые им не давали, например бутылки с водой). Именно тогда посыпались вопросы, и урок перешел в беседу о грамотности ИИ.
Все началось с того, что одна из групп начала тренировать модель с розовой упаковкой Hello Panda и протестировала модель со своей розовой металлической бутылкой. Когда розовая металлическая бутылка дала почти 100% уверенность в том, что ее материал — картон, группа начала спрашивать, учится ли модель по цвету.
Затем я предложил группе попробовать обучить картонный класс с розовой и красной упаковкой Hello Panda и понаблюдать за изменением результатов. Как и ожидалось, машина с меньшей уверенностью предсказала, что розовая металлическая бутылка (невидимый объект) была картонной.
Из этого примера участникам были выделены следующие моменты.
Модель хороша настолько, насколько хороши передаваемые в нее данные
Как говорится, «мусор на входе, мусор на выходе». Когда мы не предоставляем хороших данных, модель может быть недостаточно надежной, чтобы обобщать ее для получения правильного прогноза. Даже с появлением нулевых классификаторов, если метка не указана, модель в лучшем случае может попытаться угадать и поместить элемент в определенную категорию. Например, модель, вероятно, начала с того, что подумала, что картон розовый. Но с большим количеством примеров того, как выглядит картон, он может научиться обобщать и выделять другие признаки, говорящие нам, что это картон. Кроме того, мы знаем, что материалы классифицируются не только по внешнему виду, но и по ощущениям. Следовательно, возможно, использование мультимодальной модели может быть более эффективным.
При обучении с учителем способ маркировки данных может привести к ошибкам
Если вы еще не поняли, этикетки на рисунках выше неверны (пластик и картон были неправильно маркированы). Если данные помечены неправильно, модель даст неправильную классификацию.
Аналогия
Поскольку это комната учителей, я использовал следующую аналогию, чтобы обсудить наши наблюдения. Учителя часто курируют ресурсы для обучения наших студентов, и мы предоставляем несколько примеров для обучения наших студентов. Мы можем контролировать наши примеры и испытания, которые мы им устанавливаем, но мы не можем контролировать то, что происходит у них в голове. Но когда мы тестируем их, мы можем определить/догадаться, каковы их неправильные представления, возможно, подправить данные, чтобы уточнить их понимание. И мы проверим их снова, чтобы увидеть, научились ли они. Но когда мы учим их неправильному содержанию, они обязательно узнают что-то неправильное. Именно тогда нам нужно будет переобучить модель с правильными примерами. Однако единственная разница в том, что я могу переобучить модель с контрольной точки, но я не могу попросить студентов просто забыть то, что они узнали, и сбросить с определенной точки.
Последствия
Естественно, следующий вопрос будет заключаться в том, каковы будут последствия, если мы будем доверять моделям без участия человека. Типичные тематические исследования включают одобрение кредита, заявления о приеме на работу, прогнозирование преступлений и пригодность страховки. Если предоставленные данные предвзяты или нерепрезентативны для разных групп людей, мы можем получить дискриминационную модель. Если мы обучаем большой языковой модели (LLM) с большим количеством онлайн-текста с негативными, вульгарными и гендерно-расовыми комментариями, последующие задачи также могут генерировать такие тексты. Поэтому было проведено много исследований о том, как очистить данные, чтобы избавиться от предубеждений (которые в своей собственной форме субъективны, поскольку зависят от людей, очищающих данные).
Я рад, что сессия перешла к обсуждению грамотности в области ИИ. Возможно, это можно включить в учебную программу, чтобы позволить учащимся изучить и узнать больше об ограничениях ИИ, чтобы они могли начать задавать более правильные вопросы о модели и данных.