Получение точности SOTA на уровне 88% в наборе данных Food-101 с использованием модели ResNet50 с FastAI в Google Colab.
Давайте прямо в это.
Приведенные ниже команды оболочки устанавливают необходимые пакеты. Мне пришлось понизить версию PyTorch и Torchvision из-за проблем совместимости с Colab.
%reload_ext autoreload %autoreload 2 !apt-get update !apt install wget !pip install pathlib !pip install fastai !pip install "torch==1.4" "torchvision==0.5.0"
Ниже приведены мои импорты. Я решил использовать библиотеку FastAI. У Джереми Ховарда была отличная лекция о создании классификаторов. Это простая библиотека, которая позволяет разработчикам использовать PyTorch, и она много думала о многоуровневой классификации.
Прямо под импортом у меня также есть класс Label Smoothing. Сглаживание меток было добавлено только в бета-версию FastAI 2.0 на момент написания этой записной книжки, поэтому мне пришлось включать его вручную.
import torch
import torch.nn as nn
from fastai import *
from fastai.vision import *
from fastai.callbacks.hooks import *
from pathlib import Path
import os, shutil
from torch.distributions.beta import Beta
def lin_comb(a, b, frac_a): return (frac_a * a) + (1 - frac_a) * b
def unsqueeze(input, dims):
for dim in listify(dims): input = torch.unsqueeze(input, dim)
return input
def reduce_loss(loss, reduction='mean'):
return loss.mean() if reduction=='mean' else loss.sum() if reduction=='sum' else loss
class LabelSmoothingCrossEntropy(nn.Module):
def __init__(self, ε:float=0.1, reduction='mean'):
super().__init__()
self.ε,self.reduction = ε,reduction
def forward(self, output, target):
c = output.size()[-1]
log_preds = F.log_softmax(output, dim=-1)
loss = reduce_loss(-log_preds.sum(dim=-1), self.reduction)
nll = F.nll_loss(log_preds, target, reduction=self.reduction)
return lin_comb(loss/c, nll, self.ε)
Сборка набора данных
Поскольку я использую Colab Pro, мне приходится импортировать свой набор данных каждый раз, когда я запускаю блокнот. Я смог найти набор данных Food-101 на AWS благодаря fastAI, потому что ETH Zurich больше не размещала набор данных на своем веб-сайте (https://vision.ee.ethz.ch/datasets_extra/food-101/). Приведенный ниже код загружает tar-файл, извлекает, переименовывает и собирает изображения на основе данных из файлов train.txt и test.txt. Я предпочитаю хранить все изображения поездов в food-101/images/train, а все тестовые изображения — в food-101/images/test. Я также перемещаю все свои метафайлы в food-101/meta.
# Removing the default sample_data directory that comes with every new Colab instance
!rm -rf sample_data
# Removes the existing food-101 dataset for a fresh, complete download
!rm -rf food-101
# Downloads the food-101 dataset tar file
!wget https://s3.amazonaws.com/fast-ai-imageclas/food-101.tgz
# Untars the tar file
!tar -xvf food-101.tgz
# Removes the redundant h5 directory
!rm -rf food-101.tgz food-101/h5/
# Creates the meta, train and test directories inside food-101/images
!mkdir food-101/meta food-101/images/train food-101/images/test
# Moves all .txt and .json files to the meta directory
!mv food-101/*.txt food-101/*.json food-101/meta/
# Moves all test images to the food-101/images/test directory and renames them.
with open('food-101/meta/test.txt') as test_file:
for line in test_file:
name_of_folder = line.split('/')[0]
name_of_file = line.split('/')[1].rstrip()
Path('food-101/images/' + name_of_folder + '/' + name_of_file + '.jpg').rename('food-101/images/test/' + name_of_folder + '_' + name_of_file + '.jpg')
# Moves all training images to the food-101/images/train directory and renames them.
with open('food-101/meta/train.txt') as train_file:
for line in train_file:
name_of_folder = line.split('/')[0]
name_of_file = line.split('/')[1].rstrip()
Path('food-101/images/' + name_of_folder + '/' + name_of_file + '.jpg').rename('food-101/images/train/' + name_of_folder + '_' + name_of_file + '.jpg')
# Removes empty directories inside Food-101/images.
with open('food-101/meta/train.txt') as train_file:
for folder in train_file:
name_of_folder = folder.split('/')[0]
if os.path.exists('food-101/images/' + name_of_folder):
shutil.rmtree('food-101/images/' + name_of_folder)
Запуск команд оболочки, чтобы проверить, правильно ли я разделил изображения поезда и тестов. Должно быть 75 750 обучающих изображений и 25 250 тестовых изображений.
%cd /content/food-101/images/train/ !ls -1 | wc -l %cd ../test !ls -1 | wc -l %cd /content/ /content/food-101/images/train 75750 /content/food-101/images/test 25250 /content
Построение модели
Поскольку каждое изображение во всем наборе данных помечено, я решил использовать имена каждого изображения в качестве классов для классификатора с помощью регулярных выражений. Я тренирую модель с 20% тренировочного набора в качестве проверочного набора. Для увеличения данных я использую функцию .get_transforms() fastAI, потому что преобразования выполняются на лету, поэтому резкого увеличения размера набора данных не происходит, а о случайности заботится библиотека fastAI. Я уменьшаю каждое изображение до размера 224 для лучшего обучения. Размер пакета равен 8, потому что я не хочу превышать лимит памяти в CUDA (у меня были проблемы с этим, когда я использовал большие размеры пакетов). Я использую .normalize(imagenet_stats), чтобы легко нормализовать данные на основе статистики каналов RGB из набора данных ImageNet.
np.random.seed(42) batch_size = 8 path = 'food-101/images/train' file_parse = r'/([^/]+)_\d+\.(png|jpg|jpeg)$' data = ImageList.from_folder(path).split_by_rand_pct(valid_pct=0.2).label_from_re(pat=file_parse).transform(get_transforms(), size=224).databunch(bs = batch_size).normalize(imagenet_stats)
В моем ученике, где я добавил ResNet50 в качестве базовой архитектуры, я использую точность для своей метрики и измеряю для топ-1. Я также применяю сглаживание меток к своей модели. Сглаживание меток помогает обучить модель неправильно классифицированным данным, чтобы повысить ее производительность. Хотя это приводит к тому, что модель неправильно учится на меньший процент, это также уменьшает потери. Когда я потерял уверенность в отношении меток, я увидел, что модель работает намного лучше по сравнению с тестовым набором.
top_1 = partial(top_k_accuracy, k=1) learn = cnn_learner(data, models.resnet50, metrics=[accuracy, top_1], loss_func = LabelSmoothingCrossEntropy(), callback_fns=ShowGraph)
Обучение
Это этап обучения моей модели. Прежде чем запускать набор эпох, я начинаю с определения скорости обучения. Я добавил suggestion=True, чтобы приблизить интервал, который я буду выбирать. В приведенном ниже случае оптимальная скорость обучения составляла около 1e-06.
learn.lr_find() learn.recorder.plot(suggestion=True)

Основываясь на предложении средства поиска скорости обучения, я получаю срез скорости обучения между 1e-06 и 1e-04. Я запускаю 5 эпох на этой скорости обучения и сохраняю веса как этап-1. Точность модели увеличивается в первом прогоне. К концу 5-й эпохи точность модели улучшилась с 40,7% до 58,5%.
learn.fit_one_cycle(5, max_lr=slice(1e-06, 1e-04))
learn.save('stage-1')
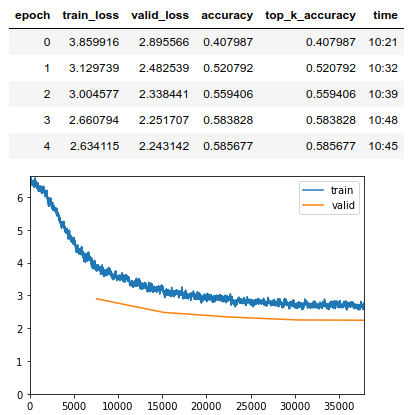
Теперь я нахожу новую скорость обучения, чтобы запустить другой набор эпох. Я делаю то же самое, что и выше. Одна вещь, которую я всегда делаю, это то, что в конце каждого цикла из 5 эпох я размораживаю модель. В этом случае моя скорость обучения составила примерно 1e-041.
learn.unfreeze() learn.lr_find() learn.recorder.plot(suggestion=True)

Я пробежал еще 5 эпох и сохранил их как stage-2. Точность модели росла так же быстро, как и на этапе 1, но на этот раз она пересекает линию проверки.
learn.fit_one_cycle(5, max_lr=slice(1e-05, 1e-04))
learn.save('stage-2')

Я хотел посмотреть, смогу ли я добиться большей точности. Для этого я воссоздал объект связки данных. Я оставил его таким же, как и в предыдущем объявлении, за исключением того, что здесь я увеличил размер изображения с 224 до 512. Я также хотел загрузить стадию 2, чтобы запустить средство поиска скорости обучения.
data = ImageList.from_folder(path).split_by_rand_pct(valid_pct=0.2).label_from_re(pat=file_parse).transform(get_transforms(), size=512).databunch(bs = batch_size).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=[accuracy, top_1], loss_func = LabelSmoothingCrossEntropy(), callback_fns=ShowGraph)
learn.load('stage-2')
learn.unfreeze()
learn.lr_find()
learn.recorder.plot(suggestion=True)
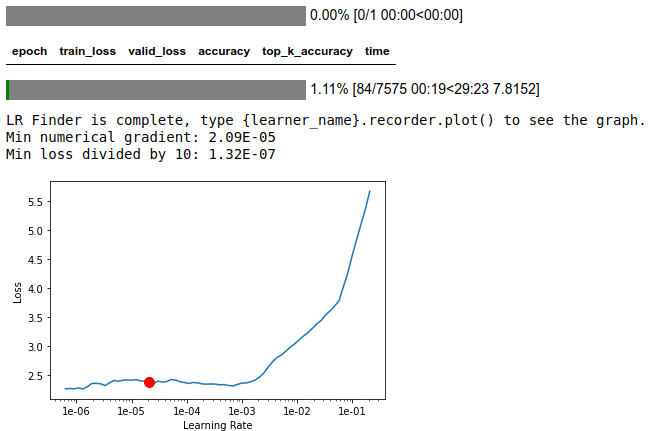
Я провел еще один набор из 5 эпох с новой скоростью обучения. Мой последний набор эпох дал мне оценку точности 77,3%, но после увеличения размера изображения я достиг точности 84,2%. Время обучения значительно увеличилось (с 11 минут на эпоху до 30 минут), потому что я увеличил размер изображения.
learn.fit_one_cycle(5, max_lr=slice(1e-05, 1e-04))
learn.save('stage-3')
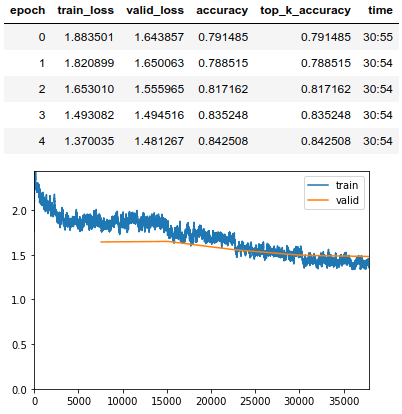
Хотя кривая начинает выпрямляться, я хотел запустить дополнительный набор из 5 эпох, чтобы получить максимальную точность от моей модели, поэтому я запустил новый искатель скорости обучения.
learn.unfreeze() learn.lr_find() learn.recorder.plot(suggestion=True)

learn.fit_one_cycle(5, max_lr=slice(1e-06, 1e-04))
learn.save('stage-4')

Не похоже, что во время тренировок я смогу достичь точности выше 84,7%. Если бы я запускал дополнительные эпохи, график просто колебался бы.
Неверные предсказания
Я хотел посмотреть, какие изображения вызвали больше всего проблем у модели. Когда дело доходит до еды, здесь много визуальных совпадений. Например, для модели нет ничего странного в том, что она путает стейк с соусом и какой-нибудь десерт, похожий на пудинг, из-за сходства цвета, формы, текстуры и т. д.
interp = ClassificationInterpretation.from_learner(learn) interp.plot_top_losses(12, figsize=(15, 11))

interp.most_confused(min_val=5)
[('filet_mignon', 'steak', 26),
('chocolate_mousse', 'chocolate_cake', 24),
('steak', 'filet_mignon', 22),
('donuts', 'beignets', 19),
('prime_rib', 'steak', 19),
('beef_tartare', 'tuna_tartare', 15),
('dumplings', 'gyoza', 15),
('chocolate_mousse', 'tiramisu', 14),
('chocolate_cake', 'chocolate_mousse', 13),
('pork_chop', 'steak', 13),
('apple_pie', 'bread_pudding', 12),
('ice_cream', 'frozen_yogurt', 12),
('grilled_salmon', 'pork_chop', 11),
('sushi', 'sashimi', 11),
('baby_back_ribs', 'steak', 10),
('chocolate_mousse', 'panna_cotta', 10),
('ramen', 'pho', 10),
('tiramisu', 'chocolate_mousse', 10),
('tuna_tartare', 'beef_tartare', 10),
('bread_pudding', 'apple_pie', 9),
('breakfast_burrito', 'huevos_rancheros', 9),
('lobster_bisque', 'clam_chowder', 9),
('apple_pie', 'baklava', 8),
('chicken_quesadilla', 'breakfast_burrito', 8),
('hamburger', 'pulled_pork_sandwich', 8),
('tuna_tartare', 'ceviche', 8),
('baby_back_ribs', 'pork_chop', 7),
('chocolate_cake', 'tiramisu', 7),
('falafel', 'tacos', 7),
('filet_mignon', 'pork_chop', 7),
('huevos_rancheros', 'nachos', 7),
('huevos_rancheros', 'tacos', 7),
('ice_cream', 'chocolate_mousse', 7),
('pork_chop', 'filet_mignon', 7),
('pulled_pork_sandwich', 'hamburger', 7),
('steak', 'prime_rib', 7),
('beet_salad', 'foie_gras', 6),
('bruschetta', 'caprese_salad', 6),
('ceviche', 'tuna_tartare', 6),
('cheesecake', 'carrot_cake', 6),
('cheesecake', 'strawberry_shortcake', 6),
('chicken_quesadilla', 'tacos', 6),
('escargots', 'french_onion_soup', 6),
('falafel', 'crab_cakes', 6),
('foie_gras', 'pork_chop', 6),
('huevos_rancheros', 'croque_madame', 6),
('peking_duck', 'spring_rolls', 6),
('ravioli', 'gnocchi', 6),
('ravioli', 'lasagna', 6),
('ravioli', 'shrimp_and_grits', 6),
('shrimp_and_grits', 'risotto', 6),
('caprese_salad', 'greek_salad', 5),
('cheesecake', 'bread_pudding', 5),
('cheesecake', 'panna_cotta', 5),
('chicken_curry', 'gnocchi', 5),
('chicken_quesadilla', 'nachos', 5),
('club_sandwich', 'grilled_cheese_sandwich', 5),
('crab_cakes', 'falafel', 5),
('croque_madame', 'grilled_cheese_sandwich', 5),
('eggs_benedict', 'croque_madame', 5),
('french_fries', 'poutine', 5),
('garlic_bread', 'pizza', 5),
('greek_salad', 'caesar_salad', 5),
('grilled_cheese_sandwich', 'club_sandwich', 5),
('grilled_salmon', 'foie_gras', 5),
('guacamole', 'nachos', 5),
('gyoza', 'dumplings', 5),
('hummus', 'chicken_quesadilla', 5),
('nachos', 'tacos', 5),
('onion_rings', 'fried_calamari', 5),
('pulled_pork_sandwich', 'grilled_cheese_sandwich', 5),
('risotto', 'fried_rice', 5),
('risotto', 'shrimp_and_grits', 5),
('steak', 'pork_chop', 5),
('strawberry_shortcake', 'cheesecake', 5)]
Когда я смотрю на вывод .most_confused(), я вижу, что путаница модели была между едой, у которой практически нет физических различий. Например, самая большая путаница была между филе-миньоном и стейком. Филе-миньон и стейк на самом деле одно и то же. Стейк — это просто широкий выбор говяжьих отрубов, а филе-миньон — это просто вырезка из меньшей части вырезки.
Обычно я также использую матрицу путаницы, но каждый раз, когда я пытался включить ее, ядро просто умирало, и все мои переменные терялись, поэтому я решил обойтись без нее.
Тестирование
Теперь пришло время протестировать обученную модель. Я создал новую переменную группы данных data_test. Это то же самое, что и выше, за исключением того, что в split_by_folder() я добавил тестовые изображения.
Я выбрал learn.validate() в качестве метода точности. Причина в том, что learn.validate() используется, если существует существующий набор проверки, а наборы проверки всегда помечены. Библиотека fastAI берет тестовые наборы вслепую, даже если тестовые изображения имеют метки, поэтому я не могу рассчитать точность только на этом основании. Для меня было логичнее создать новый объект группы данных, в который я включу свой тестовый набор как набор проверки (split_by_folder(train='train', valid='test')) и сравню с ним свою обученную модель.
path = '/content/food-101/images'
data_test = ImageList.from_folder(path).split_by_folder(train='train', valid='test').label_from_re(file_parse).transform(size=512).databunch().normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=[accuracy, top_1],callback_fns=ShowGraph)
learn.load('stage-4')
Проверка дает мне SoTA 88,1% ≈ 88%
learn.validate(data_test.valid_dl) [0.5012631, tensor(0.8809), tensor(0.8809)]
By:
Онур Андрос Озбек
Монреаль, Квебек