Некоторый контент в этом руководстве аналогичен тому, который я поделился в разделе Краткий обзор учебного пособия по NeurIPS 2021 | Самоконтролируемое обучение: самопрогнозирование и контрастное обучение. Оба учебника содержат исчерпывающие обновления по обучению с самостоятельным наблюдением и контрастному обучению, а этот учебник NAACL 2022 больше фокусируется на применении контрастного обучения в НЛП. Пожалуйста, ознакомьтесь с моим последним постом, так как я не буду подробно освещать пересекающиеся темы. Надеюсь, что сочетание этих двух постов поможет вам быстро взглянуть на последние достижения контрастного обучения.
В наши дни существует множество задач сопоставительного обучения, все из которых следуют одной идее: кодирование (встраивание) похожих образцов данных должно оставаться близким друг к другу и держаться подальше от разнородных. Нюансы среди этих целей в первую очередь проявляются в следующих двух аспектах.
- Форма контрастных проб.
- Сколько отсчетов в целевой функции?
Большинство контрастивных целей обучения противопоставляют два образца (пара), три образца (триплет) или более (набор). При работе с двумя образцами отношения между двумя образцами либо схожи, либо различны. Для трех выборок и более мы могли бы более явно охарактеризовать взаимосвязь между этими выборками. Например, мы могли бы выбрать опорную точку (триплетные потери) или описать попарную связь между каждым из образцов (поднятые структурированные потери).
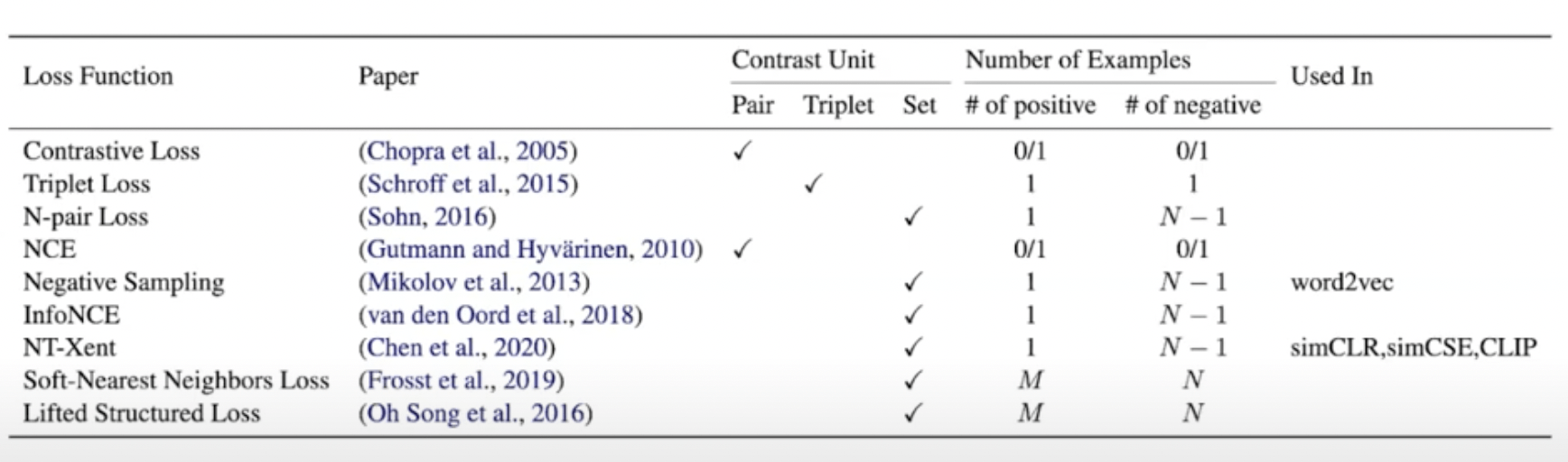
Спикер этого урока резюмировал эти различные контрастные цели обучения в следующей таблице.
Как получить контрастные данные?
Как многие из нас, возможно, знают, контрастное обучение — это мощный метод использования врожденной и взаимной информации потенциально массивных немаркированных данных, если мы можем обозначить взаимосвязь между ними. Итак, возникает проблема, как нам получить такие контрастные данные?
Оказывается, что многие современные методы получения сравнительных данных основаны на
- применение увеличения данных для сбора положительных пар, и
- применять случайную выборку для сбора отрицательных пар.
Спикер также отмечает, что есть несколько проблем, о которых мы должны знать.
Задача 1. Нетривиальное увеличение данных.
Разнообразный набор сложных методов увеличения данных позволяет нам собирать широкий спектр положительных пар и повышать способность нашей модели к обобщению.
Здесь я ввожу только условный BERT (c-BERT), так как другие методы (обратный перевод, отсев), описанные в этом руководстве, перекрываются с моим предыдущим постом на Medium. C-BERT — это метод увеличения данных для предложений. Он генерирует новое предложение с аналогичным значением, обусловленным входным предложением и дополнительной меткой предложения.

Проблема 2. Риск «систематической ошибки выборки» (т. е. ложноотрицательного результата).
Поскольку отрицательные образцы выбираются случайным образом, мы могли бы объединить изображения двух кошек в проблемную отрицательную пару.

Неизбежно мы будем выбирать некоторые положительные образцы, чтобы быть отрицательными парами. Что, если мы примем во внимание возможность этого «невезения» в нашей сравнительной цели обучения? К счастью, Чуанг и соавт. предложено непредвзятое контрастное обучение. Основной интуицией этого метода является это уравнение, которое разлагает распределение случайных выборок на интерполяцию двух распределений. Вероятность того, что выборка будет выбрана, представляет собой интерполяцию вероятности того, что эта выборка будет выбрана из положительного распределения, и вероятности того, что эта отрицательная выборка будет выбрана из отрицательного распределения.
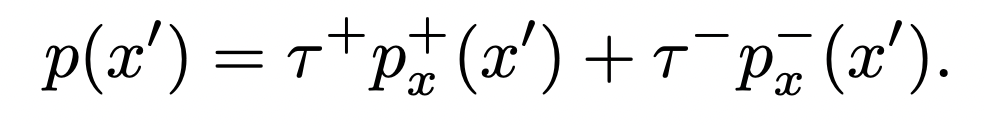
Позже они могли оценить распределение отрицательных выборок и устранить систематическую ошибку в текущей цели сравнительного обучения. Я рекомендую всем, кто интересуется математикой, стоящей за ML, прочитать эту вдохновляющую работу (Debiased Contrastive Learning).
Задача 3. Жесткий отрицательный майнинг.
Жесткие негативы — это негативные образцы, вложения которых близки к вложениям положительных образцов. Модели трудно отделить эти отрицательные образцы от положительных. Таким образом, добыча этих жестких негативов может способствовать обучению контрастному обучению.

Робинсон и др. предложил описанную выше стратегию выборки, которая умножает исходную вероятность выборки на коэффициент подобия. Чем более похожа отрицательная выборка на точку привязки, тем больше вероятность того, что она должна быть отобрана. Таким образом, модели могли бы повторять больше раз на жестких негативах, отделяя их от точки привязки.
Задача 4. Большой размер пакета.
Как видно из таблицы 1, некоторые цели контрастного обучения противопоставляют сразу несколько образцов. Откуда берутся эти образцы? На самом деле они взяты из одной и той же партии, которую мы назвали внутрипартийными негативами. SimCLR и CLIP используют размер пакета 32 КБ. Они также сообщают, что большие размеры пакетов помогают извлекать больше взаимной информации из нашего набора данных. Это согласуется с нашей интуицией, что большие размеры партий обеспечивают более разнообразный набор контрастных свойств.
Основной проблемой больших размеров пакетов является ограничение памяти. Обычно у нас нет аппаратных ресурсов, чтобы поместить 32 000 сэмплов в один пакет.
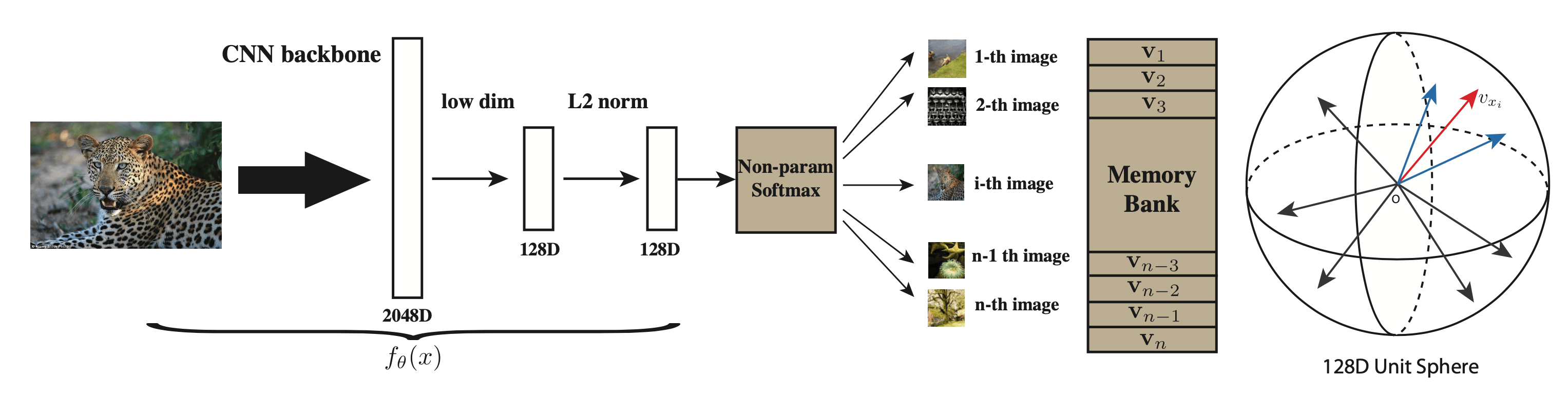
Одним из решений этого ограничения памяти является Memory Bank. Он вычисляет представление образцов заранее, вместо того, чтобы вычислять вложения для всех примеров в одном пакете.
Анализ контрастного обучения
- Геометрическая интерпретация (пропущена)
- Связь с взаимной информацией
- Теоретический анализ (пропущен)
- Надежность и безопасность
В учебном пособии читаются лекции по четырем вышеперечисленным областям. Однако я расскажу только о связи контрастного обучения с взаимной информацией, которую я нахожу наиболее интересной из всех.
Что такое взаимная информация? Он измеряет, насколько две случайные величины зависят друг от друга. Он равен нулю, если две случайные величины независимы.

InfoNCE, кажущееся на первый взгляд не имеющим отношения к взаимной информации, оказывается весьма релевантным ей. Напомним, что InfoNCE пытается отделить один положительный пример от нескольких отрицательных по отношению к вектору контекста (якорю). Если мы разделим и числитель, и знаменатель на произведение всех p(x_i), то оба они находятся в одинаковой форме взаимной информации.
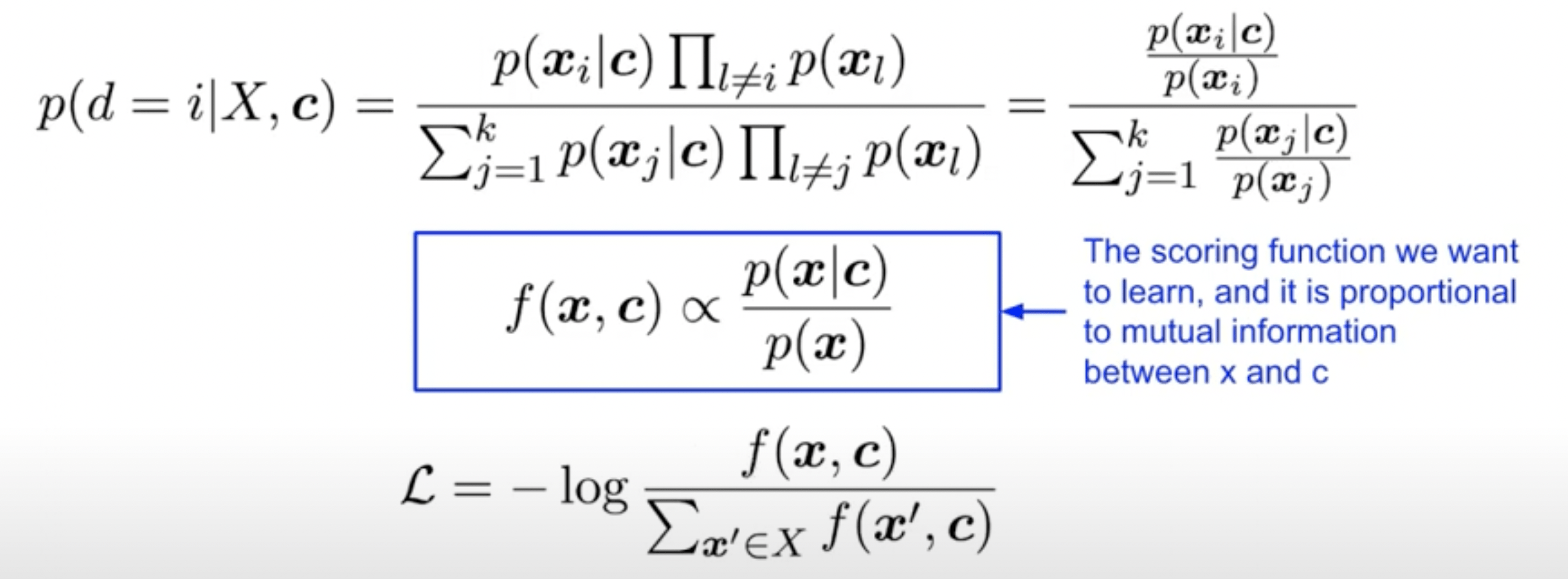
Теперь мы знаем, что минимизация потерь InfoNCE каким-то образом связана с максимизацией взаимной информации между положительными парами и минимизацией взаимной информации между отрицательными парами.
Тиан и др. предложила гипотезу InfoMin, которая использует взаимную информацию в контрастном обучении. Давайте подумаем об обрезке изображения, одном из распространенных методов увеличения данных. Как правильно обрезать изображение, чтобы оно содержало только необходимые функции, но не слишком много информации, перекрывающейся с другими обрезками? InfoMin предположил, что обрезанный вид должен отбрасывать как можно больше информации во входных данных, кроме информации, относящейся к задаче (например, самого объекта).

Контрастное обучение для НЛП
Этот учебник дал невероятно исчерпывающее введение в многочисленные модели НЛП. Поскольку этот пост предназначен для того, чтобы поделиться некоторыми ключевыми идеями о контрастном обучении, мы пропустим эту часть в этом посте. Не стесняйтесь ознакомиться с учебным пособием самостоятельно и получить быстрое представление об этих моделях.