Блаж Стоянович
Графовые нейронные сети (GNN) становятся все более популярными для обработки графоструктурированных данных, таких как социальные сети, молекулярные графы и графы знаний. Однако сложный характер данных на основе графа и нелинейные отношения между узлами на графе могут затруднить понимание того, почему GNN делает тот или иной прогноз. С ростом популярности графовых нейронных сетей также возрос интерес к объяснению их прогнозов.
Важность объяснений в практических приложениях машинного обучения невозможно переоценить. Они помогают укрепить доверие и прозрачность моделей, поскольку пользователи могут лучше понять, как делаются прогнозы, и факторы, влияющие на них. Они улучшают процесс принятия решений, предоставляя лицам, принимающим решения, дополнительное понимание, позволяющее принимать более обоснованные решения на основе предсказаний моделей. Объяснения также облегчают практикующим специалистам отладку и повышение производительности разрабатываемых ими моделей. В некоторых областях, таких как финансы и здравоохранение, могут даже потребоваться пояснения в связи с соблюдением нормативных требований.
Объяснения в графическом машинном обучении в значительной степени являются постоянными исследовательскими усилиями, и объяснимость на графиках не так зрела, как интерпретируемость в других областях машинного обучения, таких как компьютерное зрение или НЛП. Кроме того, сами объяснения различаются из-за сложных реляционных данных, с которыми работают GNN:
- Понимание контекста.Объяснения требуют контекстуального понимания взаимосвязей и объектов между узлами в графе, что может быть сложным и трудным для понимания.
- Динамические отношения. Отношения между узлами на графике могут меняться со временем, что затрудняет объяснение прогнозов, сделанных в разные моменты времени.
- Разнородные данные.GML часто включает обработку разнородных типов данных со сложными функциями, что затрудняет предоставление единой методологии объяснения.
- Детализация объяснения. Объяснения должны объяснять как структурное происхождение прогноза, так и важность признаков. Это означает объяснение того, какие узлы, ребра или подграфы важны, а также какие функции узлов или ребер сильно влияют на результат прогнозирования.
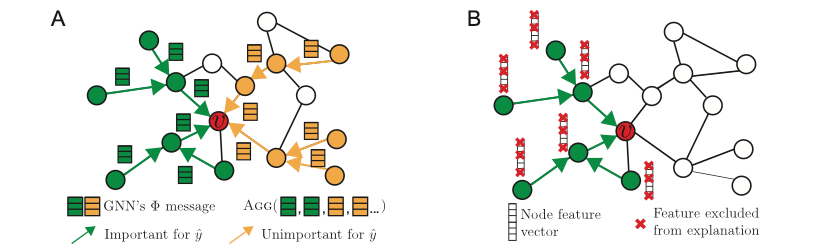
Помимо трудностей и сложностей графического машинного обучения, в последнее время в этой области было проведено много объединяющей работы, цель которой — предоставить единую основу для оценки объяснений [1,2] и предоставить таксономию существующего зоопарка объяснений. доступные методы [3].
В недавнем спринте сообщества сообщество PyG внедрило базовую структуру объяснимости вместе с различными методами оценки, эталонными наборами данных и визуализациями, которые упрощают начало работы с объяснениями Graph Machine Learning в PyG. Кроме того, фреймворк полезен как в том случае, если вы просто хотите использовать стандартные средства объяснения графов, такие как GNNExplainer [4] или PGExplainer [5], из коробки, так и если вы хотите внедрить, протестировать и оценить свои собственные методологии объяснения.
В этом сообщении блога мы шаг за шагом пройдемся по модулю объяснимости, проливая свет на то, как работает каждый компонент фреймворка и для какой цели он служит. После этого мы рассмотрим различные методы оценки объяснений и синтетические тесты, которые работают рука об руку, чтобы убедиться, что вы даете наилучшие объяснения для поставленной задачи. Мы продолжим, взглянув на методы визуализации, которые доступны из коробки. Наконец, мы рассмотрим шаги, необходимые для реализации вашего собственного метода объяснения в PyG, а также выделим работу над расширенными вариантами использования, такими как гетерогенные графики и объяснения предсказания ссылок.
Рамки
При разработке структуры объяснимости нашей целью было разработать простой в использовании модуль объяснимости, который:
- может быть расширен для удовлетворения требований многих приложений GNN
- может быть адаптирован к различным типам графиков и настройкам пояснений
- может предоставить вывод объяснения для всесторонней оценки и визуализации
На самом деле в основе фреймворка лежат четыре концепции:
- Класс Explainer: оболочка модуля объяснимости PyG для пояснений на уровне экземпляра.
- Класс Объяснение: класс для инкапсуляции вывода Объяснения.
- Класс ExplainerAlgorithm: алгоритм объяснимости, используемый эксплейнером для генерации объяснений для данного обучающего экземпляра (ов).
- Пакет метрика: оценочные метрики, которые используют вывод Объяснение и, возможно, модель GNN / наземную правду для оценки Алгоритма объяснения.
Чтобы увидеть, как они все объединяются, давайте взглянем на рисунок ниже:

Пользователь предоставляет настройки объяснения, а также модель и данные, которые необходимо объяснить. Класс Объяснитель, представляющий собой экземпляр PyG, обертывающий алгоритм объяснения — конкретный метод объяснения, генерирует объяснения для заданной модели и данных. Объяснения инкапсулированы в классе Explanation и могут быть дополнительно обработаны, визуализированы и оценены. Давайте теперь углубимся в различные доступные настройки объяснения.
Пример объяснения
Вот пример настройки Explainer, который использует GNNExplainer для пояснений модели в наборе данных Cora (см. пример gnn_explainer.py).
explainer = Explainer(
model=model,
algorithm=GNNExplainer(epochs=200),
explanation_type='model',
node_mask_type='attributes',
edge_mask_type='object',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
),
)
Маска уровня узла задается для всех атрибутов, а маска края задается для краев как объектов. Чтобы дать объяснение конкретному предсказанию модели, мы просто вызываем объяснитель:
node_index = 10 # which node index to explain explanation = explainer(data.x, data.edge_index, index=node_index)
Давайте теперь посмотрим на все гайки и болты, которые делают объяснения в PyG такими простыми!
Класс объяснения
Мы представляем объяснения, используя класс Explanation, который представляет собой объект Data или HeteroData, содержащий маски для узлов, ребер, функций и любых атрибутов данных. В этой парадигме маски действуют как поясняющие атрибуты для соответствующих узлов/ребер/признаков. Чем больше значение маски, тем важнее соответствующий компонент объяснения (0 совершенно не важен). Класс Explanation содержит методы для получения подграфа индуцированного объяснения, который состоит из всех ненулевых атрибутов объяснения и дополнения к подграфу объяснения. Кроме того, он включает в себя методы пороговой обработки и визуализации для объяснения.
Класс объяснения и настройки объяснения
Класс Explainer предназначен для обработки всех настроек объяснимости, эти настройки задаются либо как прямые параметры для Explainer, либо как конфиги в случае ModelConfig или ThresholdConfig. Этот новый интерфейс предоставляет множество настроек. Давайте рассмотрим доступные один за другим.
# Explainer Parameters model: torch.nn.Module, algorithm: ExplainerAlgorithm, explanation_type: Union[ExplanationType, str], model_config: Union[ModelConfig, Dict[str, Any]], node_mask_type: Optional[Union[MaskType, str]] = None, edge_mask_type: Optional[Union[MaskType, str]] = None, threshold_config: Optional[ThresholdConfig] = None,
model может быть любой моделью PyG, которую мы используем для создания объяснений. Дополнительные настройки модели указаны в ModelConfig, который определяет mode, task_level и return_type модели. mode описывает тип задачи, например. mode=multiclass-classification, task_level обозначает уровень задачи (задачи уровня узла, края или графа), а return_type описывает ожидаемый тип возвращаемого значения модели (raw, probs или log_probs).
Есть два типа объяснений, как указано в explanation_type (для более подробного обсуждения см. [1])
explanation_type="phenomenon"стремится объяснить, почему было принято определенное решение для определенного входа. Нас интересует феномен, который ведет от входных данных к выходным в наших данных. В этом случае метки используются в качестве целей для объяснения.explanation_type="model"призван дать постфактум объяснение предоставленногоmodel. В этом сеттинге мы пытаемся открыть черный ящик и объяснить его логику. В этом случае прогнозы модели используются в качестве целей для объяснения.
То, как именно вычисляются Explanation, определяется параметром algorithm, в модуле доступно несколько готовых:
GNNExplainer: Модель GNN-Explainer из статьи GNNExplainer: Генерация пояснений для графовых нейронных сетей.PGExplainer: Модель PGExplainer из статьи Параметризованный эксплейнер для графовой нейронной сети.AttentionExplainer: Объяснитель, который использует коэффициенты внимания, созданные GNN на основе внимания (например,GATConv,GATv2ConvилиTransformerConv), в качестве краевых объяснений.CaptumExplainer: Объяснитель на базе CaptumGraphMaskExplainer: The GraphMask-Explainer из статьи Интерпретация графовых нейронных сетей для НЛП с дифференцируемой маскировкой границ (частьtorch_geometric.contribна данный момент)PGMExplainer: Модель PGMExplainer из статьи PGMExplainer: Probabilistic Graphical Model Explanations for Graph Neural Networks (частьtorch_geometric.contribна данный момент)
Мы также поддерживаем множество различных типов масок, они устанавливаются с помощью node_mask_type и edge_mask_type и могут быть:
Noneне будет маскировать узлы/ребра"object"будет маскировать каждый узел/ребро"common_attributes"будет маскировать каждый элемент узла/атрибут ребра"attributes"будет маскировать каждый атрибут узла/ребра отдельно для всех узлов/ребер.

Наконец, вы также можете установить пороговое поведение с помощью файла ThresholdConfig. Если вы не хотите устанавливать пороговое значение для масок пояснений, вы можете установить для него значение None, в качестве альтернативы вы можете применить пороговое значение hard для любого значения, или вы можете сохранить только верхние значения k с помощью topk или установить верхние значения k равными 1. с topk_hard.
Объяснение Оценка
Генерация объяснения ни в коем случае не является концом рабочего процесса объяснимости. О качестве объяснения можно судить с помощью множества различных методов. PyG поддерживает некоторые готовые метрики оценки объяснения, вы найдете их в пакете metric.
Пожалуй, самой популярной оценочной метрикой является Fidelity+/- (подробности см. в [1]). Верность оценивает вклад созданного пояснительного подграфа в начальный прогноз, либо предоставляя модели только подграф (верность-), либо удаляя его из всего графа (верность+).

Оценки точности показывают, насколько хорошо объяснимая модель воспроизводит природное явление или логику модели GNN. После того, как мы подготовили объяснение, мы можем получить обе достоверности как:
from torch_geometric.explain.metric import fidelity fid_pm = fidelity(explainer, explanation)
Мы предоставляем оценку характеристики как средство объединения обеих верностей в единую метрику [1]. Более того, если у нас есть пара верности для объяснений на многих разных порогах (или энтропиях), мы можем вычислить площадь под кривой верности с помощью кривой верности auc. Кроме того, мы предоставляем метрику unfaithfulness, которая оценивает, насколько точно Explanation соответствует основному предсказателю GNN [6].
Такие метрики, как оценка достоверности и недостоверность, полезны для оценки объяснений, когда нет доступного объяснения «основной правды», то есть у нас нет заранее определенного набора узлов/функций/ребер, которые полностью объясняют предсказание конкретной модели или явление. В частности, при разработке новых алгоритмов объяснения нас может заинтересовать производительность на некоторых стандартных наборах эталонных данных [1,2]. Метод groundtruth_metrics сравнивает маски пояснений и возвращает выбор стандартных метрик ( ("accuracy", "recall", "precision", "f1_score", "auroc"):
from torch_geometric.explain.metric import groundtruth_metrics
accuracy, auroc = groundtruth_metrics(pred_mask,
target_mask,
metrics=["accuracy", "auroc"])
Конечно, чтобы оценивать объяснителей таким образом, сначала нужны эталонные наборы данных, в которых доступны наземные объяснения.
Эталонные наборы данных
Чтобы облегчить разработку и тщательную оценку новых алгоритмов объяснения графов, PyG теперь предоставляет несколько наборов данных для объяснения, таких как BA2MotifDataset, BAMultiShapesDataset и InfectionDataset, а также простой способ создания наборов синтетических эталонных данных. Поддержка обеспечивается через класс ExplainerDataset, который создает синтетические графы, происходящие от GraphGenerator, и случайным образом присоединяет к ним num_motifs множество мотивов, происходящих от MotifGenerator. Маски объяснимости на уровне узлов и ребер основаны на том, являются ли узлы и ребра частью определенного мотива или нет.
В настоящее время поддерживаются GraphGenerator:
BAGraph: Случайные графики Барабаси-Альберта (BA)ERGraph: Случайные графики Эрдоша-Реньи (ER)GridGraph: Двумерный сетчатый график
Но вы можете легко реализовать свой собственный, создав подкласс класса GraphGenerator. Кроме того, для мотивов мы поддерживаем
HouseMotif: Структурированный мотив дома из [4]CycleMotif: Мотив цикла из [4]CustomMotif: простой способ добавить любой мотив на основе пользовательской структуры либо из объектаData, либо из объектаnetworkx.Graph(например, формы колеса).
Наборы данных, которые мы можем сгенерировать с указанными выше настройками, являются надклассом эталонных наборов данных, используемых в GNNExplainer [4], PGExplainer [5], SubgraphX [8], PGMExplainer [9], GraphFramEx [1] и т. д.
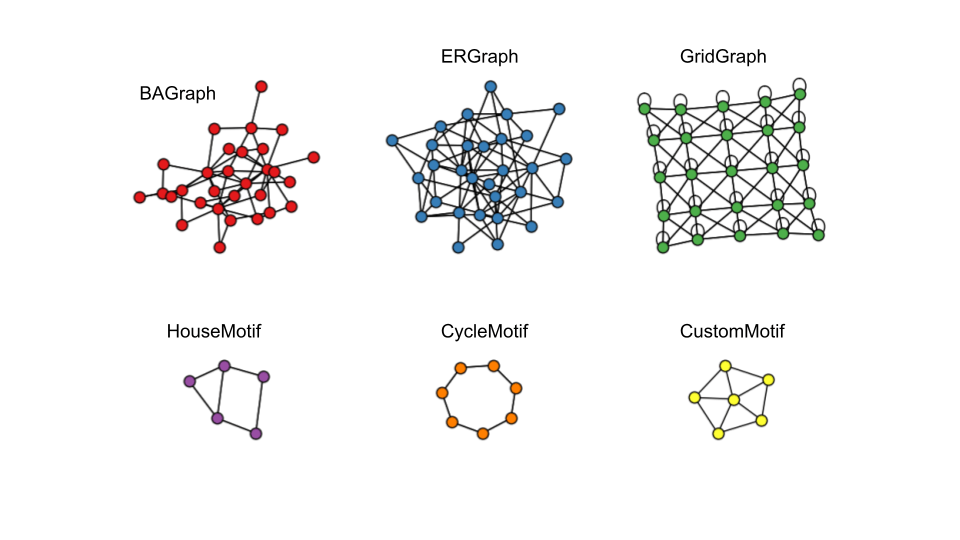
Мы можем генерировать новые наборы данных на лету с желаемыми начальными значениями и размерами. Например, чтобы сгенерировать набор данных на основе графиков Барабаси-Альберта с 80 мотивами домов, служащими метками объяснения истины, мы будем использовать:
from torch_geometric.datasets import ExplainerDataset
from torch_geometric.datasets.graph_generator import BAGraph
dataset = ExplainerDataset(
graph_generator=BAGraph(num_nodes=300, num_edges=5),
motif_generator='house',
num_motifs=80,
)
BAMultiShapesDataset — это синтетический набор данных для оценки алгоритмов объяснимости классификации графов [10]. Учитывая три атомарных мотива, а именно Дом (H), Колесо (W) и Сетка (G), BAMultiShapesDataset содержит 1000 графов Барабаси-Альберта с их метками в зависимости от прикрепления атомарных мотивов следующим образом:

Набор данных предварительно вычисляется, чтобы соответствовать официальной реализации.
Другой предварительно вычисленный набор данных — BA2MotifDataset[5]. Он содержит 1000 графиков Барабаси-Альберта. Половина графов прикреплена с помощью HouseMotif, а остальные — с пятиузловым CycleMotif. Графики относятся к одному из двух классов в соответствии с типом прикрепленных мотивов. Для создания подобных наборов данных вы можете использовать ExplainerDatasetwith генераторы графов и мотивов.
Кроме того, мы предоставляем генератор InfectionDataset [2], где узлы предсказывают свое расстояние от зараженных узлов (желтый) и используют уникальный путь к зараженным узлам в качестве объяснения. Узлы с неуникальными путями к зараженным узлам исключаются. Недостижимые узлы и узлы с расстоянием не менее max_path_length объединяются в один класс.
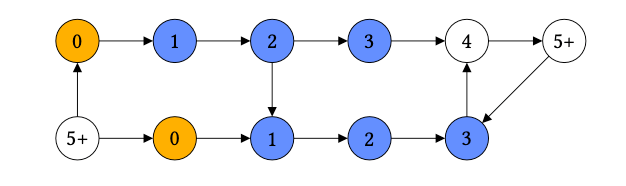
Чтобы создать набор данных о заражении, мы указываем генератор графа, длину пути заражения и количество зараженных узлов.
# Generate Barabási-Albert base graph
graph_generator = BAGraph(num_nodes=300, num_edges=500)
# Create the InfectionDataset to the generated base graph
dataset = InfectionDataset(
graph_generator=graph_generator,
num_infected_nodes=50,
max_path_length=3
)
В будущем мы планируем добавить еще больше поясняющих наборов данных и генераторов графиков, так что следите за обновлениями!
Визуализация объяснимости
Как упоминалось ранее, класс Explanation предоставляет базовые функции визуализации с помощью двух методов visualize_feature_importance() и visualize_graph().
Для визуализации объектов мы можем указать количество верхних объектов для построения с помощью top_k или передать метки объектов с помощью feat_labels.
explanation.visualize_feature_importance(feature_importance.png, top_k=10)
Вывод сохраняется по указанному пути, вот пример вывода из объяснения набора данных Cora выше:

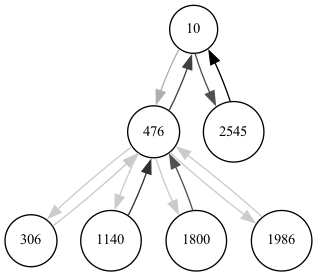
Мы также можем очень легко визуализировать график, вызванный объяснением. Результатом visualize_graph() является визуализация подграфа объяснения после фильтрации ребер в соответствии с их значениями важности (при необходимости, по настроенному порогу). У нас есть выбор из двух бэкендов (graphviz или networkx):
explanation.visualize_graph('subgraph.png', backend="graphviz")
Мы получаем локальный график узлов и ребер, которые способствуют объяснению, непрозрачность ребра соответствует важности ребра.
Реализация собственного ExplainerAlgorithm
Вся магия вычислений объяснения происходит внутри класса ExplainerAlgorithm, который передается классу Explainer. Множество популярных алгоритмов объяснения (GNNExplainer, PGExplainer и др.) уже реализованы и могут быть просто использованы. Однако, если вам понадобится нереализованный ExplainerAlgorithm, не бойтесь, просто создайте подкласс интерфейса ExplainerAlgorithm и реализуйте два необходимых абстрактных метода.
Метод forward вычисляет объяснения, он имеет следующую сигнатуру
def forward( self, # the model used for explanations model: torch.nn.Module, # the input node features x: Union[torch.Tensor, Dict[NodeType, torch.Tensor]], # the input edge indices edge_index: Union[torch.Tensor, Dict[NodeType, torch.Tensor]], # the target of the model (what we are explaining) target: torch.tensor, # The index of the model output to explain. # Can be a single index or a tensor of indices. index: Union[int, Tensor], optional, # Additional keyword arguments passed to the model **kwargs: optional, ) -> Union[Explanation, HeteroExplanation]
Чтобы помочь в построении forward() методов для различных алгоритмов объяснения, базовый класс ExplainerAlgorithmпредоставляет несколько полезных вспомогательных функций, таких как _post_process_mask для последующей обработки любой маски, чтобы не включать атрибуты элементов, не задействованных во время передачи сообщения, _get_hard_masksвозвращает жесткие узлы и маски ребер, которые включают только узлы и ребра, посещенные во время передачи сообщения, _num_hops для получения количества прыжков, из которых model собирает информацию, и другие.
Второй метод, который необходимо реализовать, — это метод supports().
supports(self) -> bool
Функция supports() проверяет, поддерживает ли объяснитель пользовательские настройки, представленные в self.explainer_configи self.model_config, она проверяет, определен ли алгоритм объяснения для конкретных используемых настроек объяснения.
Расширения для гетерогенных графов
Explanation, как описано выше, можно просто расширить до разнородных графов и HeteroData. В этом случае объяснение также является маской, но применяется ко всем элементам узла и ребра (с разными типами). Для этого мы реализовали класс HeteroExplanation, интерфейс которого практически идентичен Explanation. Кроме того, чтобы облегчить будущую работу в этом направлении, мы добавили в CaptumExplainer поддержку гетерогенных графов, которые могут служить шаблоном для будущих реализаций. Кроме того, большая часть структуры объяснимости уже ориентирована на будущее в этом направлении, и многие параметры устанавливаются в необязательных словарях для гетерогенного случая.

Объяснение предсказания ссылок
Для тех, кто хочет предоставить объяснения для прогнозов ссылок, мы добавили поддержку объяснения ссылок GNNExplainer. Идея состоит в том, чтобы рассматривать объяснение ребер просто как новый метод целевой индексации, индексируя тензор ребер вместо тензора признаков узла. Объяснения прогнозирования ссылок рассматривают объединение k-hop-окрестностей обеих конечных точек.
Эта реализация хорошо интегрируется с существующим кодом для поддержки большинства конфигураций пояснений. Пример настройки для объяснения предсказания ссылок будет выглядеть следующим образом.
model_config = ModelConfig(
mode='binary_classification',
task_level='edge',
return_type='raw',
)
# Explain model output for a single edge:
edge_label_index = val_data.edge_label_index[:, 0]
explainer = Explainer(
model=model,
explanation_type='model',
algorithm=GNNExplainer(epochs=200),
node_mask_type='attributes',
edge_mask_type='object',
model_config=model_config,
)
explanation = explainer(
x=train_data.x,
edge_index=train_data.edge_index,
edge_label_index=edge_label_index,
)
print(f'Generated model explanations in {explanation.available_explanations}')
Чтобы увидеть полный пример, посмотрите gnn_explainer_link_pred.py. Чтобы упростить начало работы с реализацией методов объяснения для любого уровня задач, мы также предоставляем примеры параметризованных тестов для всех уровней задач (граф, узел, ребро). Заинтересованные читатели могут взглянуть на test/explain.
Это был вихревой тур по объяснимости в PyG. На данный момент в PyG ведется работа над многими интересными вещами, как в области объяснимости графов, так и в других областях графового машинного обучения. Если вы хотите присоединиться к сообществу разработчиков с открытым исходным кодом, загляните на наши страницы Slack и github!
До следующего раза, команда PyG…
Рекомендации
[1] Амара К., Ин Р., Чжан З., Хан З., Шан Ю., Брандес У., Шемм С. и Чжан К., 2022 г. GraphFramEx: на пути к систематической оценке методов объяснимости графовых нейронных сетей. препринт arXiv: 2206.09677.
[2] Фабер, Л., К. Могаддам, А. и Ваттенхофер, Р., 2021 г., август. При сравнении с наземной истиной неверно: Об оценке методов объяснения gnn. В Материалы 27-й конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных (стр. 332–341).
[3] Юань, Х., Ю, Х., Гуй, С. и Цзи, С., 2022. Объяснимость в графовых нейронных сетях: таксономический обзор. Транзакции IEEE по анализу шаблонов и машинному интеллекту.
[4] Ин, З., Буржуа, Д., Ю, Дж., Зитник, М. и Лесковец, Дж., 2019. Gnnexplainer: создание объяснений для графовых нейронных сетей. Достижения в области нейронных систем обработки информации, 32.
[5] Луо, Д., Ченг, В., Сюй, Д., Ю, В., Зонг, Б., Чен, Х. и Чжан, X., 2020. Параметризованный объяснитель для графовой нейронной сети. Достижения в нейронных системах обработки информации, 33, стр. 19620–19631.
[6] Агарвал, К., Куин, О., Лаккараджу, Х. и Зитник, М., 2022. Оценка объяснимости графовых нейронных сетей. препринт arXiv arXiv:2208.09339.
[7] Baldassarre, F. and Azizpour, H., 2019. Методы объяснимости для графовых сверточных сетей. препринт arXiv arXiv:1905.13686.
[8] Юань, Х., Ю, Х., Ван, Дж., Ли, К. и Цзи, С., 2021 г., июль. Об объяснимости графовых нейронных сетей с помощью исследования подграфов. В Международной конференции по машинному обучению (стр. 12241–12252). ПМЛР.
[9] Ву, М. и Тай, М.Т., 2020. Pgm-explainer: объяснения вероятностной графической модели для графовых нейронных сетей. Достижения в системах обработки нейронной информации, 33, стр. 12225–12235.
[10] Аззолин, С., Лонга, А., Барбьеро, П., Лио, П. и Пассерини, А., 2022. Глобальная объяснимость gnns посредством логической комбинации изученных понятий. препринт arXiv arXiv:2210.07147.