
Пошаговые инструкции, как обучить модель классификации двоичного текста с помощью переносного обучения на предварительно обученной модели BERT (двунаправленные представления кодировщика от преобразователей) и делать пакетные прогнозы с помощью мелкозернистой модели на новых данные
Репозиторий GitHub с полным кодом блокнота здесь
Создайте кластер Databricks ML с установленной библиотекой Spark NLP
Databricks поставляется с средами выполнения машинного обучения, в которых есть множество библиотек, которые можно использовать для чего-либо, уже предустановленного ML. К сожалению, Spark NLP не входит в их число, и процесс настройки кластера с помощью Spark NLP не является простым и непростым, но привередливым и подверженным ошибкам. Точные инструкции, как это сделать, можно найти в официальной документации здесь, но вам обязательно нужно отредактировать конфиг Spark кластера с дополнительными spark.jars.packages И установить те же библиотеки через вкладку кластера Библиотеки. .
Как только вы решите, что правильно настроили свой кластер, запустите его, создайте блокнот Databricks Python, подключите его к только что созданному кластеру и запустите следующий код:
spark.sparkContext.getConf().get('spark.jars.packages')
Если все работает, ячейка выше сообщает одну строку с установленными банками. Если вы ничего не видите, значит, что-то еще не так.
Импортируйте библиотеки Spark NLP и запустите сеанс Spark.
В записной книжке создайте новую ячейку и выполните следующий код:
import sparknlp
from pyspark.ml import Pipeline
from sparknlp.annotator import *
from sparknlp.common import *
from sparknlp.base import *
spark = sparknlp.start()
print("Version of SparkNLP:", sparknlp.version())
print("Version of Spark :", spark.version)
Вывод должен выглядеть примерно так:
Загрузите и преобразуйте набор данных Kaggle, используемый для передачи обучения в модели BERT.
Для этой демонстрации я собираюсь использовать набор данных Kaggle под названием Mental Health Corpus, который содержит около 30 тысяч текстовых фрагментов, указывающих, может ли кто-то страдать от беспокойства, депрессии и других проблем с психическим здоровьем или нет.
Со страницы Kaggle загрузите файл archive.zip, распакуйте и создайте таблицу в базе данных Databricks по умолчанию. Просто выберите распакованный файл CSV и нажмите Создать таблицу, как показано ниже:

В записной книжке в новой ячейке загрузите содержимое ранее созданной таблицы в кадр данных Spark, выполните ETL и посмотрите количество обоих текстовых столбцов:
from pyspark.sql.functions import *
df = spark.read.table('default.mental_health') \
.withColumnRenamed('label', 'category') \
.select("category", "text") \
.withColumn("category", when(col("category") == 1, "depressed") \
.otherwise("not_depressed"))
df.groupBy("category").count().show()

Проверьте несколько текстовых столбцов:
df.show(50, truncate=100)

Разделите набор данных на наборы для обучения и тестирования.
train_text, test_text = df.randomSplit([0.8, 0.2], seed = 12345)
Запустите MLflow для эксперимента и отслеживания моделей
MLflow, платформа для жизненного цикла машинного обучения, встроена в среды выполнения Databricks ML и уже интегрирована с рабочей областью Databricks ML. Чтобы использовать его для этого эксперимента, выполните следующее в следующей ячейке записной книжки:
import mlflow from mlflow.models import Model, infer_signature, ModelSignature mlflow_run = mlflow.start_run() # Signature signature = infer_signature(test_text)
Классификация с вложениями предложений BERT
Чтобы избежать необходимости обучать модель машинного обучения с нуля, что также, вероятно, не даст хороших результатов на небольшом наборе данных, содержащем всего около 30 000 точек данных, мы собираемся провести перенос обучения на уже предварительно обученную большую языковую модель, BERT LaBSE Sentence Embeddings, через Spark NLP. Чтобы иметь возможность классифицировать текст, вложения предложений BERT будут объединены с ClassifierDLApproach в DocumentAssembler -> BertSentenceEmbeddings -> ClassifierDLApproach Конвейер Spark NLP, например:
document = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
embeddings = BertSentenceEmbeddings\
.pretrained("labse", "xx") \
.setInputCols(["document"])\
.setOutputCol("sentence_embeddings")
classsifierdl = ClassifierDLApproach()\
.setInputCols(["sentence_embeddings"])\
.setOutputCol("class")\
.setLabelColumn("category")\
.setMaxEpochs(10)\
.setEnableOutputLogs(True)
nlp_pipeline_bert = Pipeline(
stages=[document,
embeddings,
classsifierdl])
Время обучить модель на обучающем наборе данных, определенном ранее:
classification_model_bert = nlp_pipeline_bert.fit(train_text)
Зарегистрируйте модель в MLflow и создайте ссылку на URI модели.
После обучения модели отслеживайте ее в Экспериментах с Databricks через MLflow:
import pandas as pd
input_example = pd.DataFrame([{"index": 0, "text": "I'm lost in the darkness and can't find my way out."}, {"index": 1, "text": "Life is full of exciting possibilities!"}])
conda_env = {
'channels': ['conda-forge'],
'dependencies': [
'python=3.9.5',
{
"pip": [
'pyspark==3.1.2',
'mlflow<3,>=2.1',
'spark-nlp==4.2.8'
]
}
],
'name': 'mlflow-env'
}
model_name = "BERT_NLP_mental_health_classification_model"
mlflow.spark.log_model(classification_model_bert, model_name, conda_env=conda_env, signature=signature, input_example=input_example)
mlflow.log_artifacts("com.johnsnowlabs.nlp:spark-nlp_2.12:4.2.8")
mlflow.end_run()
mlflow_model_uri = "runs:/{}/{}".format(mlflow_run.info.run_id, model_name)
display(mlflow_model_uri)
После регистрации модели ее можно загрузить обратно в эту или любую другую записную книжку с подходящей средой выполнения Databricks из отслеживания экспериментов MLflow и использовать для пакетного вывода.
loaded_model = mlflow.spark.load_model(mlflow_model_uri)

Выполнение прогнозов на тестовом наборе данных
Давайте посмотрим, как эта модель, обученная на встраиваниях предложений BERT, работает с тестовым набором данных:
df_bert = loaded_model.transform(test_text).select("category", "text", "class.result").toPandas()
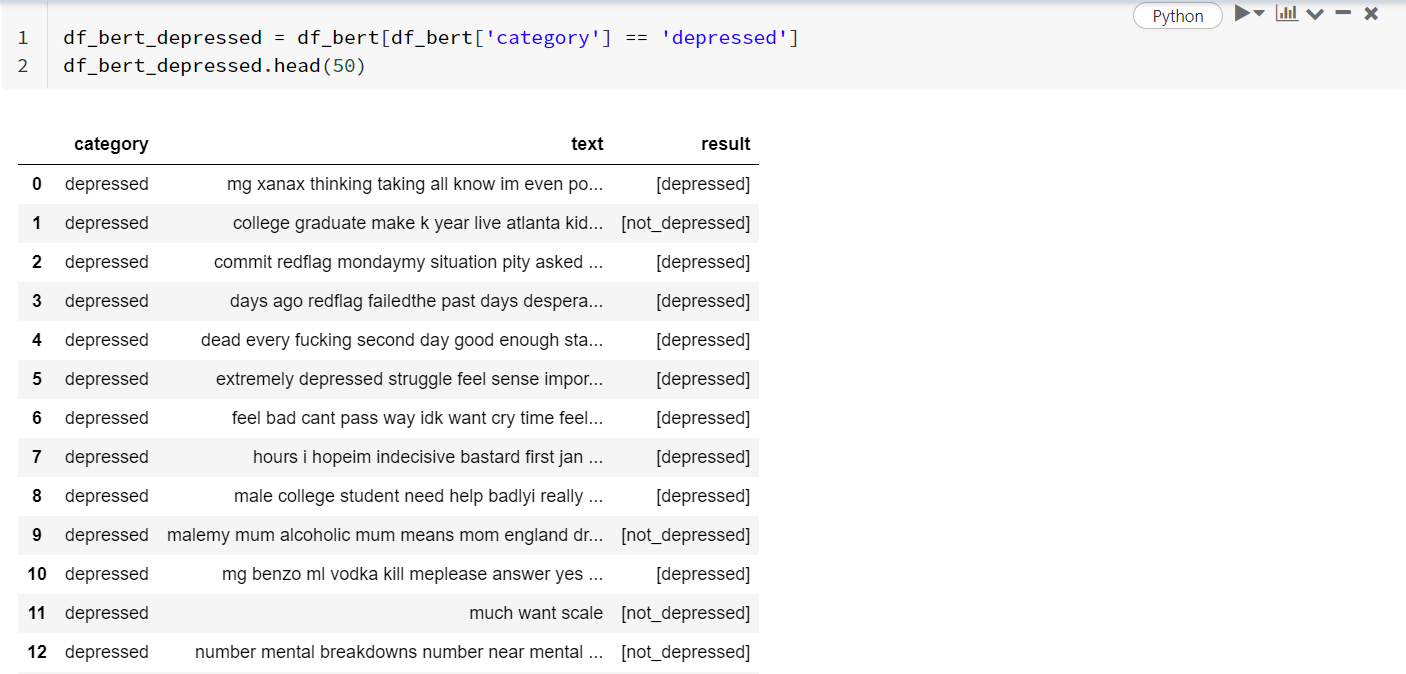
Посмотрите некоторые «депрессивные» прогнозы:
df_bert_depressed = df_bert[df_bert['category'] == 'depressed'] df_bert_depressed.head(50)
Посмотрите некоторые прогнозы «not_depressed»:
df_bert_not_depressed = df_bert[df_bert['category'] == 'not_depressed'] df_bert_not_depressed.head(50)

Похоже, что в целом модель не так уж плоха в классификации текстовых фрагментов с правильной меткой, но возникают проблемы, когда текст очень короткий. С другой стороны, как вы классифицируете «большую нехватку масштаба» или «плохую шутку» в «депрессию» или «не_депрессию»…?
Давайте создадим Scikit-learn Classification report, чтобы увидеть общую точность всего набора тестовых данных:
from sklearn.metrics import classification_report, accuracy_score print(classification_report(df_bert.category, df_bert.result.str[0]))
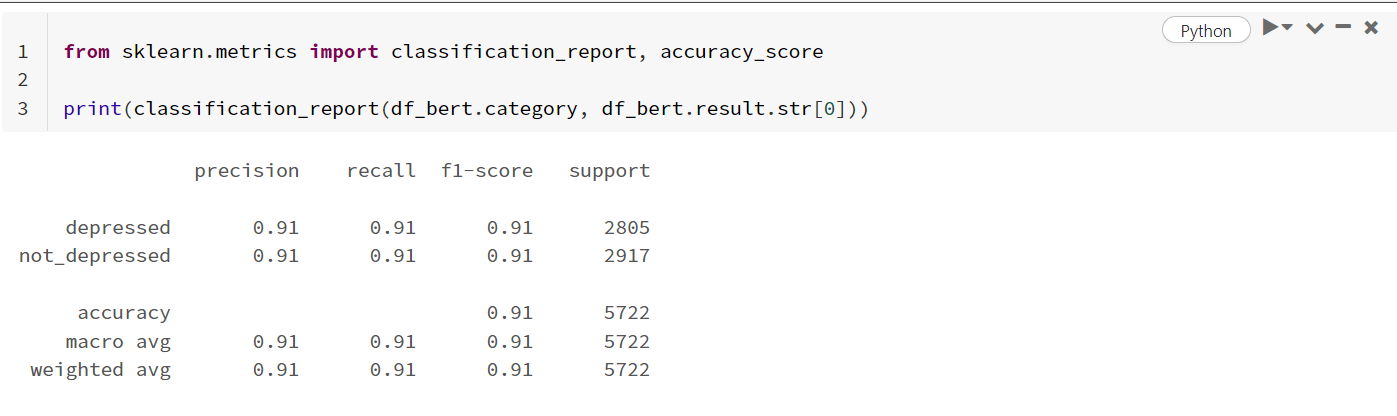
Это сводится к точности 91%, что означает, что модель примерно правильно классифицирует 9 из 10 текстовых фрагментов из тестового набора данных. Что касается небольшого количества написанного кода, размера тренировочного набора и общих усилий, затраченных на создание этой модели, я бы сказал, что это довольно приличный результат.
Давайте создадим новый фрейм данных с немаркированными текстовыми фрагментами, чтобы проверить функциональность модели на ранее невидимых данных, которые также могут несколько отличаться по стилю и т. д. от данных в обучающем корпусе:
df_new = spark.createDataFrame([
(1, "I'm so alone and isolated in my darkness."),
(2, "remember that when we show consideration for others, great things can be achieved"),
(3, "oopdeedoop beedlebob goopdeedoo pooplepoo!"),
(4, "i am very unhappy my life is miserable no one likes me i want to be alone"),
(5, "i went to bed early last night and got lots of sleep"),
(6, "today wasn't bad i got some shit done and went ona nice walk"),
(7, "Kitties and doggies snuggle up together, giving each other the love and warmth that only furry friends can provide. Their purrs and yips fill the air with joy and sweetness. Together, they make a truly wonderful pair."),
(8, "I feel like I'm all alone in this world. No one understands me or cares about me. I just wish things were different."),
(9, "Every sunrise brings a new possibility for creating your own happiness."),
(10, "I just can't find the will to go on.")
]).toDF("id", "text")
Посмотреть результаты прогноза:
df = loaded_model.transform(df_new).select("text", "class.result").toPandas()
display(df)

Ну, это выглядит в основном правильно, не так ли?
Нижняя граница
Spark NLP определенно имеет кривую обучения, и его нелегко установить правильно и без сбоев в кластере Databricks, но после настройки довольно просто использовать машинное обучение на естественном языке и создавать модели, которые выходят за рамки игровой площадки с относительно небольшим количеством кода. . Интеграция с Databricks определенно нуждается в улучшении и упрощении, и я также не смог реализовать обслуживание модели в реальном времени из-за того, что упомянуто здесь (я думаю):

Кроме этого, возможности кажутся безграничными, и я обязательно рассмотрю это подробнее, если возникнет необходимость создать что-то NLP с помощью Spark и/или Databricks.