
Видение и предложение
Это вторая часть нашей статьи, в которой представлены видение и предложения Bitrock в области проектирования данных, искусственного интеллекта и машинного обучения. Первая часть ограничивает контекст, в котором мы фокусируемся и действуем, в то время как эта часть определяет наше видение и последующее предложение.
Зрение
Искусственный интеллект (ИИ) формирует будущее человечества почти во всех отраслях и способствует прогрессу в разнородных областях, таких как большие данные, робототехника и Интернет вещей. Мы твердо убеждены, что искусственный интеллект и в будущем будет оставаться движущей силой инноваций и прогресса. Как компания, мы признаем жизненно важную важность ИИ и МО для организаций, чтобы они не просто выживали, но и процветали на рынке.
Вот почему мы стремимся предоставить нашим клиентам платформу, инструменты и опыт, чтобы использовать весь потенциал ИИ и помогать им создавать инновационные решения, помогая им вводить в действие надежные и надежные решения на основе ИИ. решения, и мы адаптируем наше предложение для удовлетворения потребностей клиентов в этой области.
AI/ML — это последняя часть головоломки, последний отрезок в гонке. Для его построения нужны прочные опоры: надежная и масштабируемая платформа данных, предназначенная для развития, а не только для последней поставки, где безопасность и управление является центральным, с автоматическими тестами и непрерывной интеграцией/развертыванием. Ведь для данных тем более справедлив девиз «мусор на входе, мусор на выходе».
Платформы данных должны быть адаптированы к потребностям клиентов: не существует универсального подхода к проблемам инженерии данных, скорее есть компании, клиенты, партнеры с разным опытом и потребностями, требующие разных решений. Перефразируя молоток Маслоу, не все можно забить молотком.
Мы верим в индивидуальные решения для наших клиентов, помогая им преодолеть сложности текущего ландшафта данных и разрабатывая платформу, которая лучше соответствует их существующей инфраструктуре и потребностям.
Мы также стремимся помочь нашим клиентам определить четкую и эффективную стратегию использования данных, которая соответствует общей бизнес-цели. Организации должны определить цели, процессы и бизнес-задачи; предоставить структуру и процессы управления данными, уравновешивающие вопросы безопасности, конфиденциальности и упрощающие процесс обнаружения, доступа и использования данных.
Чтобы предоставлять наилучшие услуги, мы ценим наше партнерство: на сегодняшний день мы являемся партнерами Databricks, Confluentи HashiCorp.
Принципы дизайна
Наши решения следуют определенным принципам проектирования, определяющим наш выбор и дизайн:
Сначала облако
Облако в первую очередь означает приоритет облака над локальными решениями. Другими словами, необходимо обосновать выбор локальных решений, а не облачных.
Мы знаем о нежелании некоторых компаний использовать облачные решения: тем не менее, в настоящее время все еще очень мало причин не использовать облачные технологии. Преимуществ, предоставляемых облаком, слишком много: более быстрый выход на рынок, простое масштабирование, отсутствие предварительных затрат на лицензию/оборудование, более низкие эксплуатационные расходы. По сути, это позволяет нам отдать на аутсорсинг непрофильные процессы и сосредоточиться на том, что наиболее важно для бизнеса.
ML/AI с самого начала
В последние годы машинное обучение (МО) и искусственный интеллект (ИИ) стали свидетелями огромного скачка вперед, в основном из-за увеличения доступности вычислительных ресурсов (более быстрые графические процессоры, больший объем памяти) и данных. Искусственный интеллект достиг или превзошел человеческий уровень производительности во многих сложных задачах: автономное вождение теперь стало реальностью, а социальные сети широко используют машинное обучение для обнаружения вредоносного контента и целевой рекламы, в то время как генеративные сети, такие как GPT-3 от OpenAI или Imagen от Google, могут стать игрой. изменения в стремлении к искусственному общему интеллекту (AGI).
AI/ML — это уже не будущее, а настоящее.
Некоторые организации будут использовать это как конкурентное преимущество перед своими конкурентами; другие будут рассматривать это как домашнее задание, чтобы не отставать и оставаться конкурентоспособными на рынке. Наверняка никто больше не может позволить себе игнорировать это (а может быть, только монополии и государственная администрация?).
AI и ML играют центральную роль в нашем видении и формируют наш архитектурный и технологический выбор.
В этом контексте непрерывная интерпретация данных, обнаружение закономерностей и принятие своевременных решений на основе исторических данных и данных в реальном времени, так называемая непрерывная аналитика, будут играть решающую роль в определении бизнес-стратегий и станут одним из наиболее распространенных приложений. машинное обучение. Действительно, по оценкам Gartner, в течение 3 лет более 50% всех бизнес-инициатив будут требовать непрерывного анализа, а к 2023 году более трети предприятий будут иметь аналитиков, практикующих анализ решений, включая моделирование решений.
MLOps и разработка искусственного интеллекта
MLOps, или операции машинного обучения, — это область в сообществе машинного обучения, которая быстро набирает обороты. Он отстаивает необходимость управления жизненным циклом машинного обучения в соответствии с лучшими практиками программного обеспечения и философией DevOps. Этот подход направлен на то, чтобы сделать программное обеспечение на основе машинного обучения воспроизводимым, тестируемым и развиваемым, гарантируя развертывание и обновление моделей контролируемым и эффективным образом. Важность MLOps заключается в возможности повысить скорость и надежность развертывания моделей машинного обучения, одновременно снижая риск ошибок и повышая общую производительность моделей.
Демократизация данных
Мы уже подчеркивали важность демократизации данных. Для ее достижения необходимо наличие нескольких ключевых элементов. Во-первых, для этого требуется культура данных, при которой данные рассматриваются как стратегический актив, который ценится и используется во всей компании. Это требует участия и приверженности со стороны высшего руководства.
Повсеместный доступ к данным требует широкого внедрения более надежных решений управления данными с функциями обнаружения данных, чтобы эффективно управлять сложными процессами данных и делать данные доступными и пригодными для использования всеми, кто в них нуждается.
Сделать данные доступными означает также снизить входной барьер для них и, следовательно, предоставить более удобные для пользователя платформы, которые можно использовать автономно, без дополнительных знаний (так называемая платформа самообслуживания).
Сетка данных — это подход, ориентированный на крупномасштабные среды и идущий в этом направлении. Он устраняет разрозненность и узкие места в крупных компаниях и делает упор на децентрализацию владения данными, передавая право собственности на данные группам бизнес-доменов.
Сетка данных — это подход, который увеличивает общую сложность и создает новые проблемы для организаций, внедряющих его, но он может помочь им, когда масштабируемость и разрозненность данных фактически представляют собой входной барьер для использования данных в масштабах всей компании.
Эталонная архитектура
Мы в Bitrock воздерживаемся от предоставления универсального решения; мы скорее предоставляем эталонную архитектуру данных, созданную по образцу технологических стеков, используемых в нескольких компаниях, дополненную последними инновациями.
Мы ориентируемся на мультимодальную архитектуру обработки данных, специализирующуюся на AI/ML и операционных сценариях использования, способную удовлетворить аналитические потребности, типичные для хранилищ данных. Как объяснялось ранее, это альтернатива, ориентированная на бизнес-аналитику, основанная на хранилищах данных.
В основе системы лежат концепции озера данных и хранилища данных.
Озеро данных – это централизованный репозиторий, который позволяет хранить и управлять всеми вашими структурированными и неструктурированными данными в любом масштабе. Они традиционно ориентированы на продвинутую обработку операционных данных и ML/AI. Концепция хранилища данных добавляет к ним надежный уровень хранения в сочетании с механизмом обработки (spark, presto, …), чтобы расширить возможности хранения данных, что делает озера данных подходящими и для аналитических рабочих нагрузок.
Растет признание этой архитектуры, которая поддерживается широким кругом поставщиков, включая Databricks AWS, Google Cloud, Starburst и Dremio, а также поставщиками хранилищ данных, такими как Snowflake.
Для более подробного ознакомления с ним, пожалуйста, обратитесь к предыдущей статье в нашем блоге (Data Lakehouse, за пределами шумихи).
Наш предпочтительный механизм обработки — Apache Spark, который де-факто является стандартом для операционных рабочих нагрузок в сочетании с проверенным и надежным Apache Airflow или Astronom, версией SaaS. . В мире оркестровки Dagster или Prefect являются альтернативами Airflow, которые набирают все большую популярность. Они способствуют переходу к абстракции более высокого уровня, от управления рабочим процессом к обработке потоков данных.
Spark подходит как для пакетных рабочих нагрузок, так и для рабочих нагрузок в реальном времени, но для обработки данных в реальном времени хорошими альтернативами могут быть Apache Flinkи Kafka Streams, особенно для приложений с более жесткими задержками. требования.
В мире потоковой передачи, применяемом к AI и ML, есть еще один вариант — Helicon от Radicalbit, который представляет собой решение, направленное на сокращение разрыва между учеными и инженерами данных с использованием подхода без кода / с низким кодом. Возродился интерес к решениям без кода / с низким кодом, которые привлекают новых пользователей (то есть аналитиков и разработчиков программного обеспечения) на рынок ML, подталкиваемый новыми решениями ML с низким кодом, такими как Databricks AutoML, H2O, Datarobot и т. д.
Быстрое исследование данных может быть достигнуто либо с помощью специальных механизмов запросов, таких как Trino/Presto/Starburst/Databricks SQL, либо с помощью блокнотов, таких как Jupyter, или их управляемых версий.
Интеграция — это скучная домашняя работа, предшествующая веселой части. Тем не менее, он составляет наибольшую часть стоимости большинства проектов с данными, варьируясь от 20–30% в среднем до 70% в некоторых пессимистичных случаях.
С технической точки зрения уровень внедрения довольно разнообразен и обычно формируется в соответствии с источниками данных и инфраструктурой организации.
Традиционно данные извлекаются из операционных источников данных и преобразуются перед загрузкой в хранилище данных, так называемое ETL. Дешевое облачное хранилище и разделение хранения и вычислений заложили основу для смены парадигмы, выступающей за опережение фазы загрузки перед фазой преобразования (ELT). Этот шаблон, на самом деле не совсем новый для озер данных, блистает, поскольку он удаляет бизнес-логику из фазы загрузки на уровне внедрения, что позволяет упростить интеграцию за счет аутсорсинга.
Fivetran, наряду с Airbyte, Matillion и многими другими, являются примерами инструментов ELT. Строго говоря, термин ETL обычно больше используется в контексте хранилищ данных, однако эти инструменты интеграции также полезны для озер и архитектур озер: например, Fivetran недавно стал партнером Databricks.
На уровне внедрения Confluent также играет все более важную роль с Kafka Connectors, позволяя ему извлекать (и отправлять) данные из различных источников. Пара Kafka и CDC (Change Data Capture) с таким программным обеспечением, как Debezium/Qlik/Fivetran, становится все более и более распространенным шаблоном интеграции, используемым в этом контексте.
На следующем рисунке, основанном на унифицированной платформе данных от Horowitz (Bornstein, Li, and Casado 2020), показана наша архитектура, в частности поля, выделенные желтым цветом:
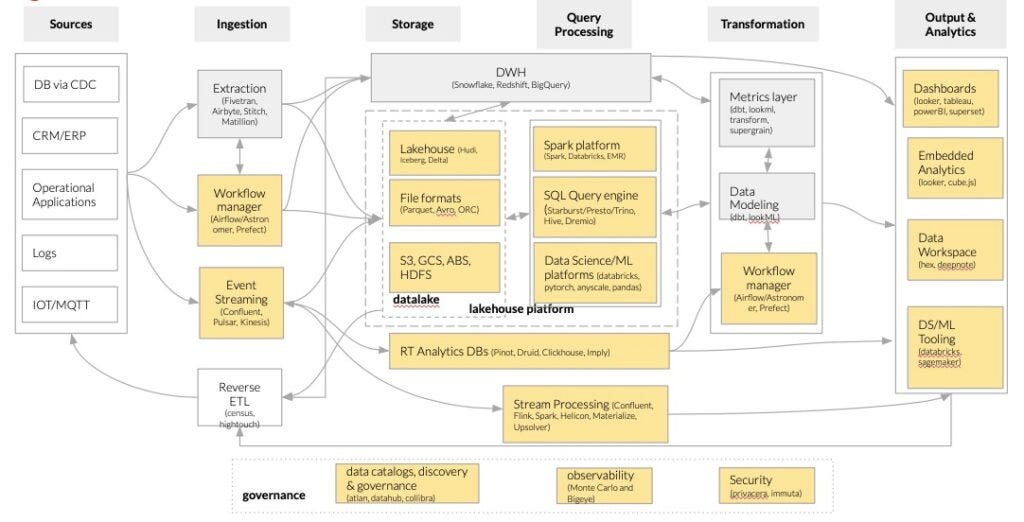
ML-платформа
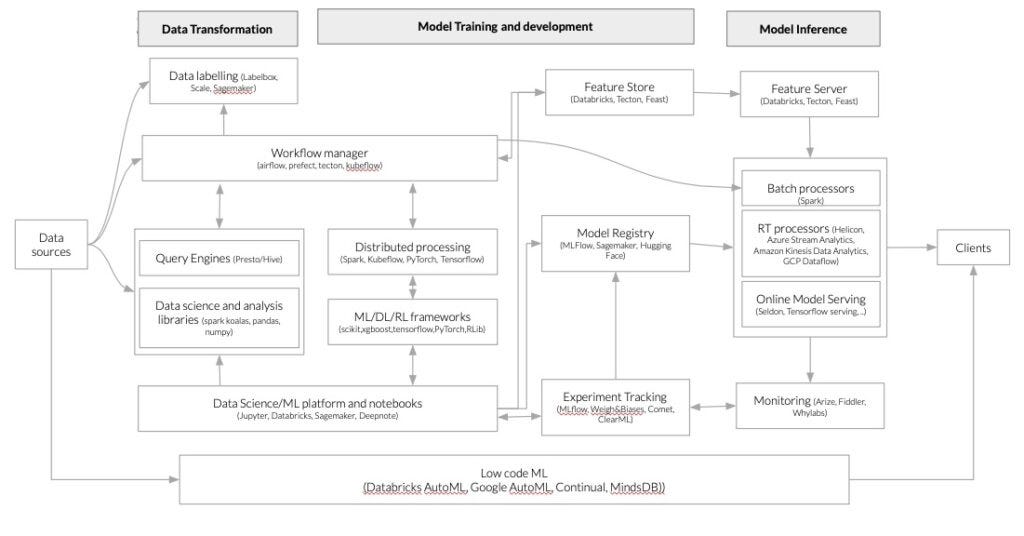
Центральная роль в нашей платформе отводится операционализации моделей машинного обучения и программного обеспечения на основе искусственного интеллекта.
MLOps, или операции машинного обучения, — это быстрорастущая область в сообществе машинного обучения, которая отстаивает необходимость управления жизненным циклом машинного обучения в соответствии с передовыми практиками, основанными на программном обеспечении, и философией DevOps. Этот подход направлен на то, чтобы сделать программное обеспечение на основе машинного обучения воспроизводимым, тестируемым и развиваемым, гарантируя, что модели развертываются и обновляются контролируемым и эффективным образом. Важность MLOps заключается в возможности повысить скорость и надежность развертывания моделей машинного обучения, одновременно снижая риск ошибок и повышая общую производительность моделей. Наша идея универсальной платформы для машинного обучения, предоставляющей все инструменты для реализации жизненного цикла ML, лучше всего описана на следующем рисунке, основанном на (Bornstein, Li, and Casado 2020).
Выводы
Мы считаем, что AI и ML имеют решающее значение для любой организации и будут иметь основополагающее значение для успеха и процветания на рынке.
Bitrock стремится предоставить клиентам платформу, инструменты и опыт, чтобы использовать весь потенциал искусственного интеллекта (ИИ) и машинного обучения (МО) и реализовать его с помощью проектирования ИИ и MLOps.
Мы адаптируем наше предложение для удовлетворения уникальных потребностей наших клиентов и верим в предоставление индивидуальных решений для наших клиентов. Наша цель — совместно определить четкую и эффективную стратегию работы с данными, которая соответствует их общим бизнес-целям.
Если у вас есть какие-либо вопросы, сомнения или вы просто хотите обсудить темы, связанные с данными, свяжитесь с нами: мы будем более чем рады помочь или просто поболтать!
Рекомендации
- Барбуцци, Антонио. 2022. «Data Lakehouse, за пределами шумихи» Bitrock.
- Борнштейн, Мэтт, Дженнифер Ли и Мартин Касадо. 2020. Новые архитектуры для современной инфраструктуры данных. Андреессен Горовиц. https://future.com/emerging-architectures-modern-data-infrastructure/.
Автор: Антонио Барбуцци, руководитель отдела данных, искусственного интеллекта и машинного обучения @Bitrock