В платформе, основанной на событиях, такой как Node.js, наиболее эффективным способом обработки ввода-вывода является работа в режиме реального времени, использование ввода, как только оно становится доступным, и отправка вывода, как только приложение его создает.
Итак, я познакомлю вас с потоками Node.js и их сильными сторонами. Пожалуйста, имейте в виду, что это только обзор, а более подробный анализ того, как использовать и создавать потоки.
Буферизация против потоковой передачи
Почти все асинхронные API, которые мы видели до сих пор, работают в буферном режиме. Для операции ввода в буферном режиме все данные, поступающие от ресурса, собираются в буфер до завершения операции; затем он передается обратно вызывающей стороне как один блок данных.
На следующей диаграмме показан наглядный пример этой парадигмы:
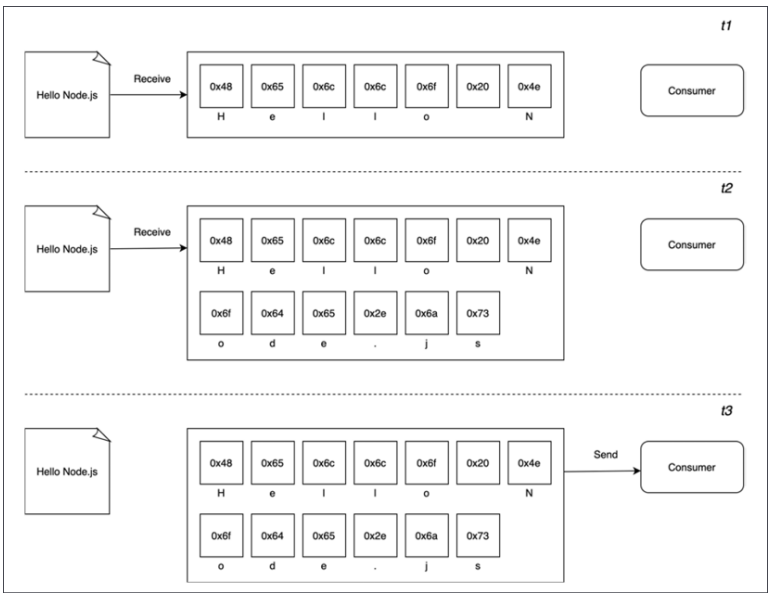
На картинке выше мы видим, что в момент времени t1 некоторые данные принимаются от ресурса и сохраняются в буфере. В момент времени t2 принимается еще одна порция данных — последняя, которая завершает операцию чтения, так что в момент времени t3 весь буфер отправляется потребителю.
С другой стороны, потоки позволяют нам обрабатывать данные, как только они поступают из ресурса. Это показано на следующей диаграмме:

На этот раз на картинке видно, что как только каждый новый блок данных поступает от ресурса, он тут же передается потребителю, который теперь имеет возможность обрабатывать его сразу, не дожидаясь, пока все данные будут собраны в буфер.
Но в чем разница между этими двумя подходами? Чисто с точки зрения эффективности потоки могут быть более эффективными с точки зрения как пространства (использование памяти), так и времени (время вычислений). Однако у потоков Node.js есть еще одно важное преимущество: комбинируемость. А теперь посмотрим, какое влияние эти свойства оказывают на то, как мы разрабатываем и пишем наши приложения.
Пространственная эффективность
Во-первых, потоки позволяют нам делать вещи, которые были бы невозможны при буферизации данных и их одновременной обработке. Например, рассмотрим случай, когда нам нужно прочитать очень большой файл, скажем, порядка сотен мегабайт или даже гигабайт. Очевидно, что использование API, возвращающего большой буфер после полного чтения файла, не является хорошей идеей. Представьте, что вы одновременно читаете несколько таких больших файлов; нашему приложению легко не хватило бы памяти. Кроме того, буферы в V8 ограничены по размеру. Вы не можете выделить больше нескольких гигабайт данных, поэтому мы можем упереться в стену, прежде чем закончится физическая память.
Фактический максимальный размер буфера зависит от платформы и версии Node.js. Если вам интересно узнать, каков предел в байтах на данной платформе, вы можете запустить этот код:
import buffer from 'buffer' console.log(buffer.constansts.MAX_LENGTH)
Сжатие с помощью буферизованного API
Чтобы сделать конкретный пример, давайте рассмотрим простое приложение командной строки, которое сжимает файл, используя формат GZIP. При использовании буферизованного API такое приложение в Node.js будет выглядеть следующим образом (обработка ошибок для краткости опущена):
import { promises as fs } from 'fs'
import { gzip } from 'zlib'
import { promisify } from 'util'
const gzipPromise = promisify(gzip)
const filename = process.argv[2]
async function main () {
const data = await fs.readFile(filename)
const gzippedData = await gzipPromise(data)
await fs.writeFile(`${filename}.gz`, gzippedData)
console.log('File successfully compressed')
}
main()
Теперь мы можем попытаться поместить предыдущий код в файл с именем gzip-buffer.js, а затем запустить его с помощью следующей команды:
node gzip-buffer.js <path to file>
Если мы выберем достаточно большой файл (например, около 8 ГБ), мы, скорее всего, получим сообщение об ошибке, в котором говорится, что файл, который мы пытаемся прочитать, больше, чем максимально допустимый размер буфера:
RangeError [ERR_FS_FILE_TOO_LARGE]: File size (8130792448)
Это именно то, чего мы ожидали, и это симптом того, что мы используем неправильный подход.
Сжатие с использованием потоков
Самый простой способ исправить наше приложение Gzip и заставить его работать с большими файлами — использовать потоковый API. Давайте посмотрим, как этого можно достичь. Напишем новый модуль со следующим кодом:
// gzip-stream.js
import { createReadStream, createWriteStream } from 'fs'
import { createGzip } from 'zlib'
const filename = process.argv[2]
createReadStream(filename)
.pipe(createGzip())
.pipe(createWriteStream(`${filename}.gz`))
.on('finish', () => console.loh('File successfully compressed'))
"Это оно?" Вы можете спросить. Да! Как мы уже говорили, потоки удивительны благодаря своему интерфейсу и возможности компоновки, что позволяет создавать чистый, элегантный и лаконичный код. Через некоторое время мы увидим это более подробно, но сейчас важно понимать, что программа будет работать без сбоев с файлами любого размера и с постоянным использованием памяти. Попробуйте сами (но учтите, что сжатие большого файла может занять некоторое время).
Эффективность времени
Давайте теперь рассмотрим случай приложения, которое сжимает файл и загружает его на удаленный HTTP-сервер, который, в свою очередь, распаковывает его и сохраняет в файловой системе. Если бы клиентский компонент нашего приложения был реализован с использованием буферизованного API, загрузка началась бы только тогда, когда весь файл был прочитан и сжат. С другой стороны, распаковка начнется на сервере только после получения всех данных. Лучшее решение для достижения того же результата включает использование потоков. На клиентской машине потоки позволяют нам сжимать и отправлять фрагменты данных, как только они считываются из файловой системы, тогда как на сервере они позволяют нам распаковывать каждый фрагмент, как только он получен от удаленного узла. Давайте продемонстрируем это, создав упомянутое ранее приложение, начиная со стороны сервера.
Давайте создадим модуль с именем gzip-receive.js, содержащий следующий код:
import { createServer } from 'http'
import { createWriteStream } from 'fs'
import { createGunzip } from 'zlib'
import { basename, join } from 'path'
const server = createServer((req, res) => {
const filename = basename(req.headers['x-filename'])
const destFilename = join('received_files', filename)
console.log(`File request received: ${filename}`)
req
.pipe(createGunzip())
.pipe(createWriteStream(destFilename))
.on('finish', () => {
res.writeHead(201, { 'Content-Type': 'text/plain' })
res.end('OK\n')
console.log(`File saved: ${destFilename}`)
})
})
server.listen(3000, () => console.log('Listening on http://localhost:4000'))
В предыдущем примере req — это объект потока, который используется сервером для получения порциями данных запроса из сети. Благодаря потокам Node.js каждый фрагмент данных распаковывается и сохраняется на диск сразу после его получения.
Вы могли заметить, что в нашем серверном приложении мы используем basename() для удаления любого возможного пути из имени полученного файла. Это лучшая практика безопасности, поскольку мы хотим убедиться, что полученный файл сохранен именно в нашей папке Received_files. Без basename() злоумышленник может создать запрос, который может эффективно переопределить системные файлы и внедрить вредоносный код в серверную машину. Представьте, например, что произойдет, если для имени файла установлено значение /usr/bin/node? В таком случае злоумышленник может эффективно заменить наш интерпретатор Node.js любым произвольным файлом.
Клиентская часть нашего приложения войдет в модуль с именем gzip-send.js, и он выглядит следующим образом:
import { request } from 'http'
import { createGzip } from 'zlib'
import { createReadStream } from 'fs'
import { basename } from 'path'
const filename = process.argv[2]
const serverHost = process.argv[3]
const httpRequestOptions = {
hostname: serverHost,
port: 4000,
path: '/',
method: 'PUT',
headers: {
'Content-Type': 'application/octel-stream',
'Content-Encoding': 'gzip',
'X-Filename': basename(filename)
}
}
const req = request(httpRequestOptions, () => {
console.log(`Server response: ${res.statusCode}`)
})
createReadStream(filename)
.pipe(createGzip())
.pipe(req)
.on('finish', () => {
console.log('File successfully sent')
})
В предыдущем коде мы снова используем потоки для чтения данных из файла, а затем сжимаем и отправляем каждый фрагмент, как только он считывается из файловой системы.
Теперь, чтобы попробовать приложение. давайте сначала запустим сервер, используя следующую команду:
node zip-receive.js
Затем мы можем запустить клиент, указав файл для отправки и адрес сервера (например, localhost):
node gzip-send.js <path to file> localhost
если мы выберем достаточно большой файл, мы сможем оценить, как данные передаются от клиента к серверу. Но почему именно эта парадигма — когда у нас есть потоковые данные — более эффективна по сравнению с использованием буферизованного API? Следующая картинка должна облегчить понимание этой концепции:

При обработке файл проходит ряд последовательных этапов:
- [Клиент] Чтение из файловой системы
- [Клиент] Сжать данные
- [Клиент] Отправить на сервер
- [Сервер] Получение от клиента
- [Сервер] Распаковать данные
- [Сервер] Записать данные на диск
Чтобы завершить обработку, мы должны пройти каждый этап, как на конвейере, последовательно, до конца. На предварительном изображении мы видим, что при использовании буферизованного API процесс полностью последовательный. Чтобы сжать данные, мы сначала должны дождаться, пока будет прочитан весь файл, затем, чтобы отправить данные, мы должны дождаться, пока весь файл будет прочитан и сжат, и так далее.
Используя потоки, сборочная линия запускается, как только мы получаем первый фрагмент данных, не дожидаясь, пока будет прочитан весь файл. Но что еще более удивительно, когда доступен следующий блок данных, нет необходимости ждать завершения предыдущего набора задач; вместо этого параллельно запускается еще одна сборочная линия. Это прекрасно работает, потому что каждая выполняемая нами задача является асинхронной, поэтому ее можно распараллелить с помощью Node.js. Единственным ограничением является то, что порядок, в котором куски поступают на каждом этапе, должен быть сохранен. Внутренняя реализация потоков Node.js заботится о поддержании порядка за нас.
Как видно из рисунка, результатом использования потоков является то, что весь процесс занимает меньше времени, потому что мы не тратим время на ожидание того, чтобы все данные были прочитаны и обработаны одновременно.
Компонуемость
Код, который мы видели до сих пор, уже дал нам обзор того, как потоки могут быть составлены благодаря методу pipe(), который позволяет нам соединять различные процессорные блоки, каждый из которых отвечает за одну функциональную задачу, в идеальном Node.js. стиль. Это возможно, потому что потоки имеют единый интерфейс, и они могут понимать друг друга с точки зрения API. Единственным предварительным условием является то, что следующий поток в конвейере должен поддерживать тип данных, созданный предыдущим потоком, который может быть двоичным, текстовым или даже объектным.
Чтобы взглянуть на еще одну демонстрацию возможностей этого свойства, мы можем попробовать добавить уровень шифрования к приложению gzip-send/gzip-receive, которое мы создали ранее.
Для этого нам нужно будет применить небольшие изменения как к нашему клиенту, так и к серверу.
Добавление шифрования на стороне клиента
Начнем с клиента:
//...
import { createCipheriv, randomBytes } from 'crypto'
const filename = process.argv[2]
const serverHost = process.argv[3]
const secret = Buffer.from(process.argv[4], 'hex')
const iv = randomBytes(16)
//...
Давайте посмотрим, что мы изменили здесь:
- Прежде всего, мы импортируем поток преобразования createCipheriv() и функцию randomBytes() из модуля шифрования.
- Мы получаем секрет шифрования сервера из командной строки. Мы ожидаем, что строка будет передана в виде шестнадцатеричной строки, поэтому мы считываем это значение и загружаем его в память, используя буфер, установленный в шестнадцатеричный режим.
- Наконец, мы генерируем случайную последовательность байтов, которую будем использовать в качестве вектора инициализации для шифрования файла.
Теперь мы можем обновить часть кода, отвечающую за создание HTTP-запроса:
const httpRequestOptions = {
hostname: serverHost,
headers: {
'Content-Type': 'application/octel-stream',
'Content-Encoding': 'gzip',
'X-Filename': basename(filename),
'X-Initialization-Vector': iv.toString('hex')
}
}
//...
const req = request(httpRequestOptions, (res) => {
console.log(`Server response: ${res.statusCode}`)
})
createReadStream(filename)
.pipe(createGzip())
.pipe(createCipheriv('aes192', secret, iv))
.pipe(req)
//...
Основные изменения здесь следующие:
- Мы передаем вектор инициализации серверу в виде HTTP-заголовка.
- Мы шифруем данные сразу после фазы Gzip.
Это все для клиентской стороны.
Добавление расшифровки на стороне сервера
Давайте теперь рефакторим сервер. Первое, что нам нужно сделать, это импортировать некоторые служебные функции из основного криптомодуля, которые мы можем использовать для генерации случайного ключа шифрования (секрета):
import { createDecipheriv, randomBytes } from 'crypto'
const secret = randomBytes(24)
console.log(`Generated secret: ${secret.toString('hex')}`)
Сгенерированный секрет выводится на консоль в виде шестнадцатеричной строки, чтобы мы могли поделиться ею с нашими клиентами.
Теперь нам нужно обновить логику приема файлов:
const server = createServer((req, res) => {
const filename = basename(req.headers['x-filename'])
const iv = Buffer.from(
req.headers['x-initialization-vector'], 'hex')
const destFilename = join('received_files', filename)
console.log(`File request received: ${filename}`)
req
.pipe(createDecipheriv('aes192', secret, iv))
.pipe(createGunZip())
.pipe(createWriteStream(destFilename))
})
Здесь мы применяем два изменения:
- Мы должны прочитать вектор инициализации шифрования, отправленный клиентом.
- Первый шаг конвейера потоковой передачи теперь отвечает за расшифровку входящих данных с использованием потока преобразования createDecipheriv из модуля шифрования.
С очень небольшими усилиями (всего несколько строк кода) мы добавили в наше приложение уровень шифрования; нам просто пришлось использовать некоторые уже доступные потоки Transform (createCipheriv и createDecipheriv) и включить их в конвейеры обработки потоков для клиента и сервера. Подобным образом мы можем добавлять и комбинировать другие потоки, как если бы мы играли с кубиками Lego.
Основным преимуществом этого подхода является возможность повторного использования, но, как видно из кода, потоки также обеспечивают более чистый и модульный код. По этим причинам потоки часто используются не только для работы с чистым вводом-выводом, но и как средство упрощения и модульности кода.
Теперь, когда мы представили потоки, мы готовы более структурировано изучить различные типы потоков, доступные в Node.js.