Привет всем энтузиастам данных. Во-первых, давайте разберемся с выбросами.
Выбросы — это точки данных, которые значительно отличаются от остальных данных. Это влияет на статистический анализ данных и влияет на эффективность нашей модели машинного обучения. Чтобы максимизировать точность модели, мы должны удалить выбросы из набора данных.
Алгоритмы, использующие метрику расстояния или основанные на статистических допущениях (например, линейная регрессия), более чувствительны к выбросам, тогда как алгоритмы, основанные на границах решений или более устойчивые к шуму (например, деревья решений), менее чувствительны. к выбросам.
Алгоритмы, чувствительные к выбросам:
- Линейная регрессия
- Логистическая регрессия
- Кластеризация K-средних
- K-ближайшие соседи (KNN)
Алгоритмы, менее чувствительные к выбросам:
- Деревья решений
- Случайные леса
- Машины повышения градиента (GBM)
- Наивный Байес
Способы выявления выбросов
Использование Z-оценки
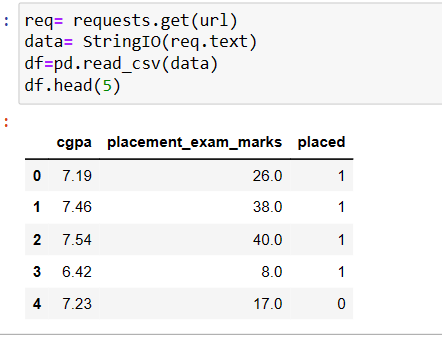
##First let's plot a graph to see the distribution of data points plt.figure(figsize=(16,5)) plt.subplot(1,2,1) sns.distplot(df['cgpa']) plt.subplot(1,2,2) sns.distplot(df['placement_exam_marks']) plt.show()

#Calculate Mean and Standard Deviation
print("mean of CGPA {}".format(df['cgpa'].mean()))
print("mean of CGPA {}".format(df['cgpa'].std()))
output:
mean of CGPA 6.96124000000001
mean of CGPA 0.6158978751323894
#Calculating the boundary values
# Here we are considering outliers as data points which are beyond the Max and Min
# boundry values
print("Max value to be considered {}".format(df['cgpa'].mean() + 3*df['cgpa'].std()))
print("Min value to be considered {}".format(df['cgpa'].mean() - 3*df['cgpa'].std()))
output:
Max value to be considered 8.808933625397177
Min value to be considered 5.113546374602842
#now let's find the outliers in out dataset
df[(df['cgpa']> 8.80) | (df['cgpa'] < 5.11)]
Output:

Теперь есть два способа обработки выбросов. либо мы можем обрезать выбросы, либо мы можем сделать Capping. Ниже приведен пример обрезки.
# Excluding outliers and creating new data frame object with uniform distribution new_df=df[(df['cgpa']< 8.80) & (df['cgpa'] > 5.11)] new_df

Ограничение — это метод, при котором мы не удаляем выбросы, а устанавливаем для них максимальное и минимальное пороговые значения. Для вышеперечисленного, например, любой показатель «cgpa», превышающий 8,80, устанавливается на 8,80, а значение ниже 5,11 устанавливается на 5,11. Ниже приведен пример укупорки.
##Capping
upper_limit= df['cgpa'].mean() + 3*df['cgpa'].std()
lower_limit= df['cgpa'].mean() - 3*df['cgpa'].std()
import numpy as np
df['cgpa']= np.where( df['cgpa'] > upper_limit,upper_limit,
np.where(df['cgpa']< lower_limit,
lower_limit,df['cgpa']
)
)
df.shape
output: (1000, 3)
Использование IQR (межквартильный диапазон)
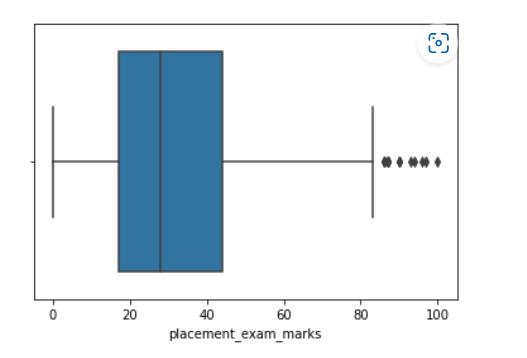
## Now let's treat the outliers of column "placement_exam_marks" by IQR method df['placement_exam_marks'].describe() output: count 1000.000000 mean 32.225000 std 19.130822 min 0.000000 25% 17.000000 50% 28.000000 75% 44.000000 max 100.000000 Name: placement_exam_marks, dtype: float64 # This information gives us meaningful insight into data. # as the mean value is greater than the 50th percentile, which means data is positively skewed. ##let's plot boxplot to gain insights of data distribution sns.boxplot(df['placement_exam_marks'])
###Finding IQR percentile_25 = df['placement_exam_marks'].quantile(0.25) percentile_75 = df['placement_exam_marks'].quantile(0.75) percentile_75, percentile_25 output: (44.0, 17.0)
Формула IQR: 75-й процентиль — 25-й процентиль.
IQR = percentile_75 - percentile_25 IQR output: 27.0 Upper_limit=percentile_75 + 1.5 * IQR Lower_limit=percentile_25 -1.5 * IQR Upper_limit,Lower_limit output: (84.5, -23.5)
Теперь у нас есть верхнее и нижнее пороговое значение для выбросов. Все, что выше 84,5 и ниже -23,5, считается выбросом. давайте узнаем эти точки во фрейме данных.
##Finding the outliers df[df['placement_exam_marks'] > Upper_limit] output:

поэтому давайте обрежем выбросы.
#Trimming new_df = df[df['placement_exam_marks'] < Upper_limit] new_df output:

Вы можете выполнить Capping так же, как и мы, имея дело с выбросами с помощью метода Z-Score.
Итак, это все для понимания основных основ обработки выбросов.