
По мере того как бизнес-системы становятся все более сложными, пользователи все больше беспокоятся о производительности системы и необходимости отслеживать соответствующие показатели во время работы системы. Это включает в себя получение информации о показателях мониторинга в режиме реального времени, мониторинг и предупреждение о соответствующих проблемах, а также объединение бизнес-анализа для обнаружения аномалий.
Мониторинг производительности приложений (APM) отслеживает и диагностирует производительность системы, собирая, сохраняя и анализируя системные данные, которые можно наблюдать. Его основные функции включают мониторинг показателей производительности, анализ цепочки вызовов и карты топологии приложений. Как правило, данные о производительности системных операций получают с помощью метрик, трассировки и ведения журналов.
В этой статье объясняется, как ShardingSphere-Agent собирает метрики мониторинга ShardingSphere-JDBC и как отображать их визуально.
Выполнение
Существует два метода, которые обычно рассматриваются при сборе метрик: ручное отслеживание событий в бизнес-методах и использование агента Java для ненавязчивого отслеживания событий. Первый метод слишком сильно вмешивается в бизнес и не является хорошим выбором для включения в бизнес логики, не связанной с бизнесом. Поэтому, как правило, лучше использовать Java Agent для ненавязчивого отслеживания событий.
В зависимости от агента Java изменение байт-кода цели для сбора данных также называется технологией зондирования. ShardingSphere-Agent использует агент Java для добавления прокси-агента при запуске JVM и использует Byte Buddy для изменения целевого байт-кода для имплантации логики сбора данных.
Введение модуля
shardingsphere-agent-api: определяет расширенные интерфейсы, конфигурации плагинов и многое другое.
shardingsphere-agent-core: определяет процессы загрузки плагинов и вход агента.
shardingsphere-agent-plugins: определяет плагины.
В этой статье в основном представлен плагин индикатора в модуле shardingsphere-agent-plugins. В рамках этого модуля плагин индикатора в основном имеет следующие модули.
shardingsphere-agent-metrics-core: Модуль определения коллекции индикаторовshardingsphere-agent-metrics-prometheus: Модуль отображения данных индикатора
Настройка отслеживания событий
Значимые классы следует рассматривать для отслеживания. Например, в ShardingSphere-JDBC наиболее часто используемыми и важными являются ShardingSphereStatement и ShardingSpherePreparedStatement. Мы часто используем методы execute, executeQuery и executeUpdate этих двух классов для запуска SQL, поэтому эти методы также являются наиболее важными местами, на которые следует обратить внимание. Соответствующие показатели также могут быть собраны с помощью этих методов.
Например, можно отслеживать время выполнения этих методов. Существующий индикатор jdbc_statement_execute_latency_millis logs the execute, executeQuery и executeUpdate методов ShardingSphereStatement и ShardingSpherePreparedStatement и отслеживает время выполнения методов.
Метрики
Метрики мониторинга ShardingSphere-JDBC
Показатели мониторинга, собираемые ShardingSphere-Agent, соответствуют стандарту OpenMetrics. В следующей таблице описаны показатели:
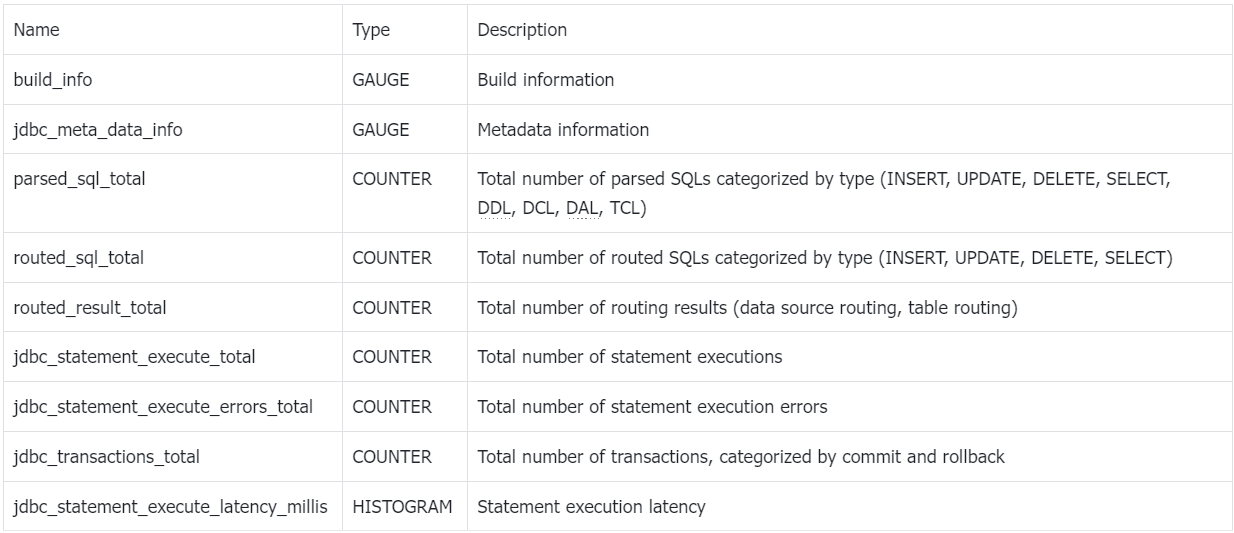
Эти показатели можно использовать для мониторинга производительности ShardingSphere-JDBC и выявления любых проблем, которые могут возникнуть. Метрики собираются и отображаются визуально с помощью плагина индикатора в модуле shardingsphere-agent-plugins.
Метрики мониторинга JVM
Помимо сбора метрик для ShardingSphere-JDBC, ShardingSphere-Agent также предоставляет соответствующие метрики для JVM. В следующей таблице описаны эти показатели:

Эти метрики можно использовать для мониторинга производительности JVM и выявления любых проблем, которые могут возникнуть. Метрики собираются и отображаются визуально с помощью плагина индикатора в модуле shardingsphere-agent-plugins.
Объяснение типа показателя:
- Метрики типа GAUGE указывают, что значение метрики может увеличиваться или уменьшаться.
- Метрики типа COUNTER указывают, что значение метрики может только увеличиваться и никогда не уменьшаться.
- Метрики типа HISTOGRAM представляют собой гистограмму, которая в основном используется для распределения значений метрик, таких как время выполнения метода.
Гид пользователя
Пример использования проекта Spring Boot, интегрированного с ShardingSphere-JDBC: Чтобы продемонстрировать, как собирать и отображать метрики с помощью ShardingSphere-Agent, мы будем использовать проект Spring Boot, который интегрируется с ShardingSphere-JDBC. Чтобы настроить проект, выполните следующие действия:
- Загрузите файл spring-boot-shardingsphere-jdbc-test.jar. Инструкции по настройке можно найти в официальной документации ShardingSphere [1].
- Скачайте ShardingSphere-Agent с официального сайта [2]. Обратите внимание, что ShardingSphere-JDBC и ShardingSphere-Agent должны иметь одну и ту же версию и поддерживаться, начиная с версии 5.3.2.
- Настройте структуру каталогов ShardingSphere-Agent следующим образом:
cd agent
tree
├── LICENSE
├── NOTICE
├── conf
│ └── agent.yaml
├── plugins
│ ├── lib
│ │ ├── shardingsphere-agent-metrics-core-${latest.release.version}.jar
│ │ └── shardingsphere-agent-plugin-core-${latest.release.version}.jar
│ ├── logging
│ │ └── shardingsphere-agent-logging-file-${latest.release.version}.jar
│ ├── metrics
│ │ └── shardingsphere-agent-metrics-prometheus-${latest.release.version}.jar
│ └── tracing
│ ├── shardingsphere-agent-tracing-opentelemetry-${latest.release.version}.jar
└── shardingsphere-agent-${latest.release.version}.jar
- Настройте файл
agent.yaml, чтобы включить мониторинг.
plugins:
metrics:
Prometheus:
host: "localhost"
port: 39090
props:
jvm-information-collector-enabled: "true"
Детали конфигурации:
hostпредставляет собой IP-адрес, по которому метрики отображаются на локальном компьютере. По умолчаниюlocalhost.portпредставляет порт, на котором отображаются метрики.jvm-information-collector-enabledпоказывает, собирается ли информация о метриках, связанных с JVM. По умолчаниюtrue.
Начать проект
java -javaagent:${agentPath}/agent/shardingsphere-agent-${latest.release.version}.jar -jar spring-boot-shardingsphere-jdbc-test.jar
Примечание. javaagent следует настроить с абсолютным путем к файлу jar.
После запуска проекта отправьте запросы к соответствующим бизнес-интерфейсам в проекте, чтобы активировать соответствующее отслеживание и создать данные показателей.
Затем посетите http://127.0.0.1:39090, где находятся открытые данные метрик, чтобы получить информацию о данных. Ниже приведен скриншот некоторых показателей:
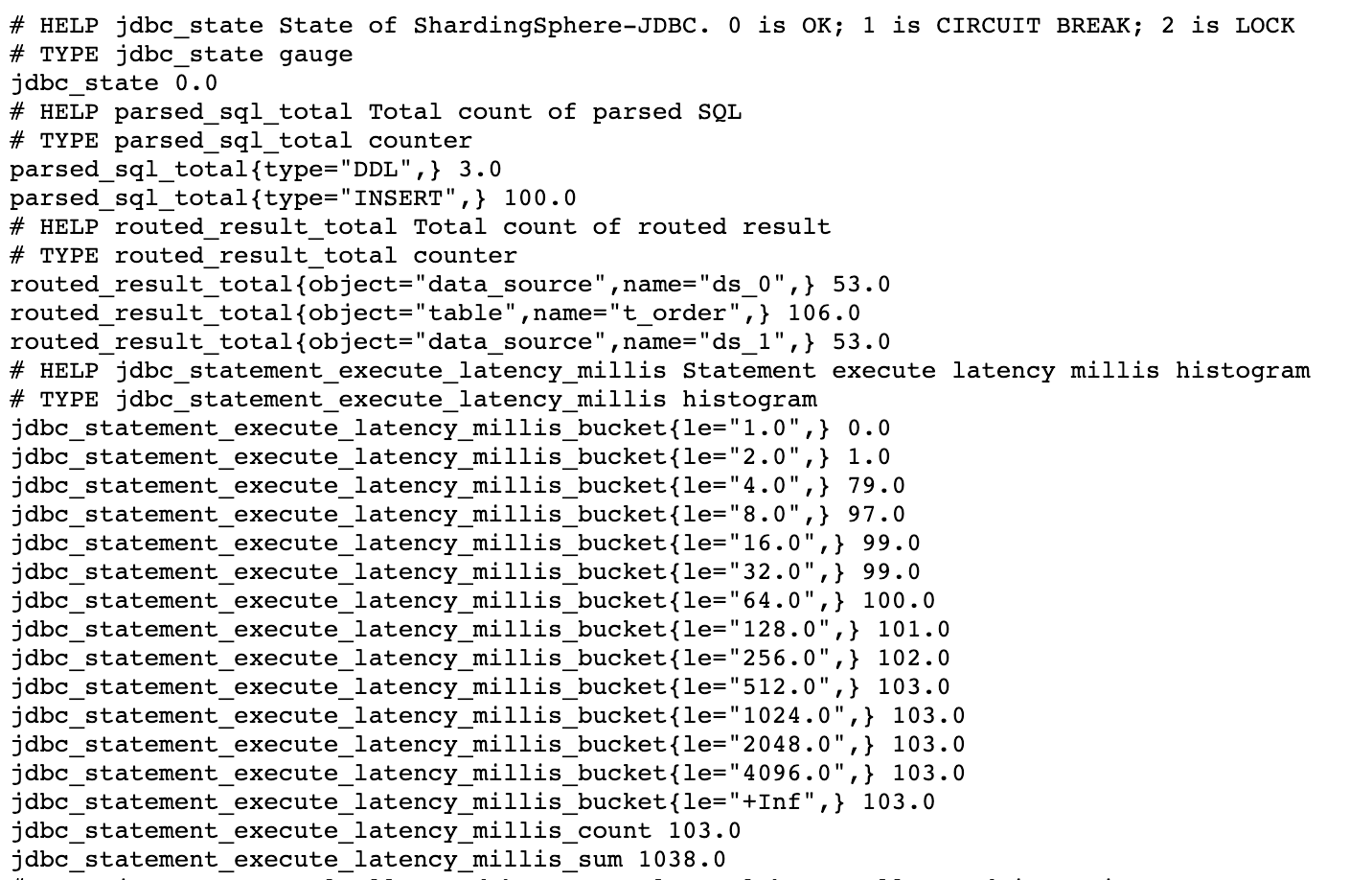
Примечание:
jdbc_statement_execute_latency_millis_bucket, jdbc_statement_execute_latency_millis_count и jdbc_statement_execute_latency_millis_sum на скриншоте выше получены из метрики jdbc_statement_execute_latency_millis.
В соответствии со спецификацией метрики при создании метрики типа HISTOGRAM автоматически создаются метрики с суффиксами _bucket, _count и _sum. Мы обсудим, как их использовать позже.
В производственных сценариях Prometheus часто используется для сбора и хранения метрик, а Grafana — для визуализации. Далее настроим Prometheus и Grafana.
Прометей
Добавьте следующую конфигурацию в файл prometheus.yml для сбора данных мониторинга. Подробнее об использовании Prometheus см. на официальном сайте Prometheus [3].
scrape_configs:
- job_name: "jdbc"
static_configs:
- targets: ["127.0.0.1:39090"]
Графана
Чтобы визуализировать собранные данные мониторинга в Grafana, нам нужно настроить источник данных Prometheus и написать запросы PromQL для извлечения нужных данных метрик. Дополнительную информацию об использовании Grafana можно найти на официальном сайте [4]. Чтобы узнать, как использовать PromQL, обратитесь к официальной документации [5].
Например, мы можем использовать метрику jdbc_statement_execute_total для отображения среднего количества операторов SQL, выполняемых в минуту. Вот пример того, как этого добиться:
rate(jdbc_statement_execute_total{instance=~'192.168.65.2:39090'}[1m])
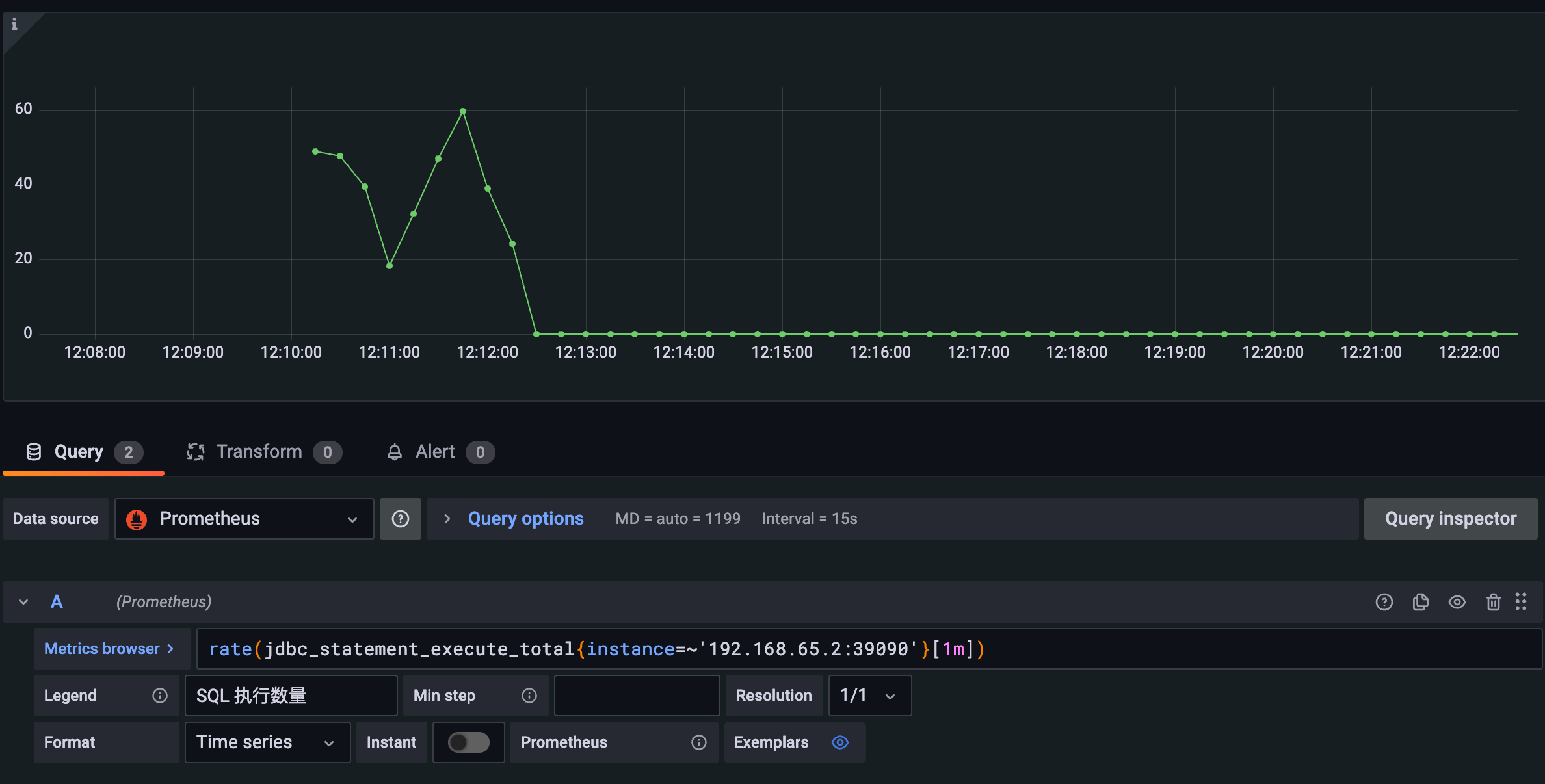
Чтобы просмотреть метрики SQL, перенаправленные во внутреннюю базу данных, можно использовать метрику routed_sql_total для отображения. Эта метрика использует тег type для разделения операторов SQL по их типам (INSERT, UPDATE, DELETE и SELECT), что упрощает анализ статистики различных типов SQL.
rate(routed_sql_total{instance=~'192.168.65.2:39090'}[1m])
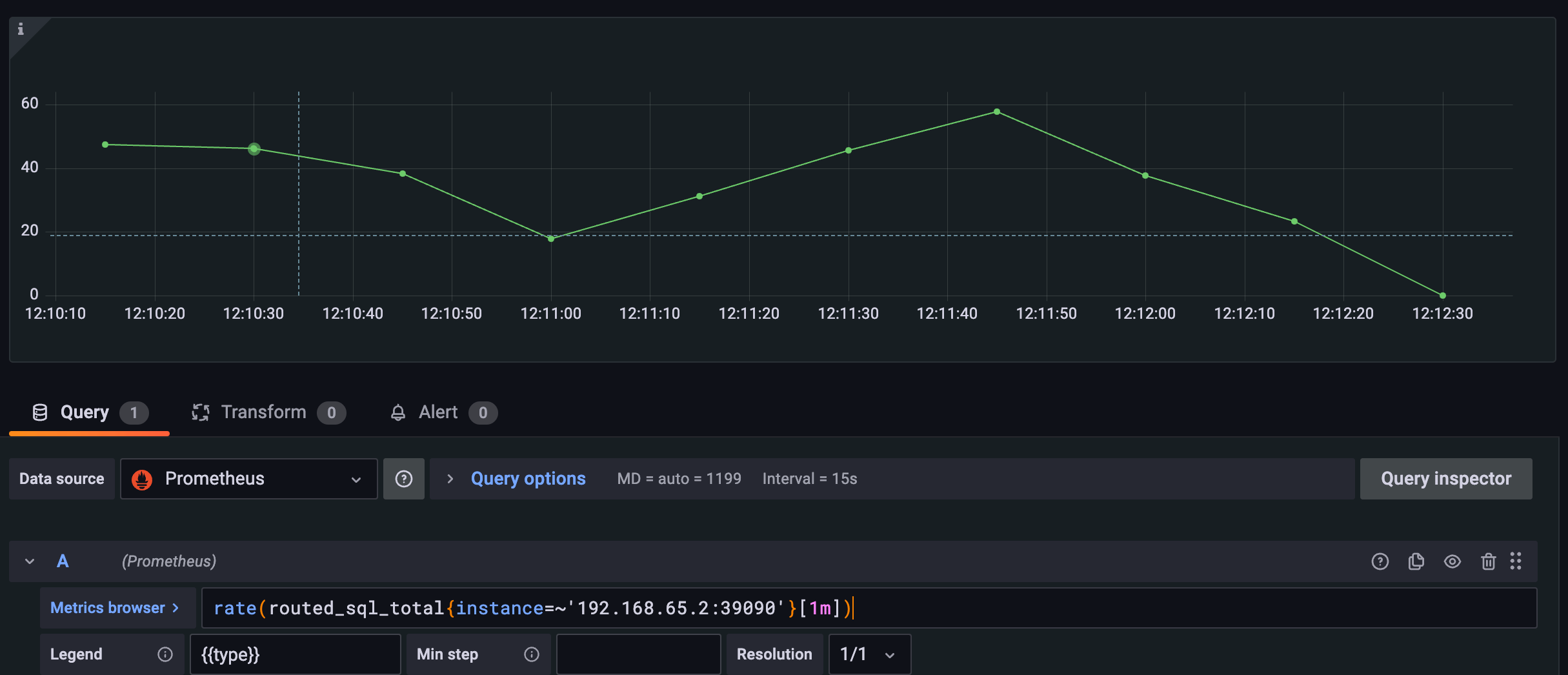
Другие метрики типа COUNTER можно получить с помощью аналогичного оператора PromSQL. Мы рекомендуем вам попробовать их самостоятельно.
Часто нас больше беспокоит время, необходимое для выполнения операторов SQL. В данном случае метрика jdbc_statement_execute_latency_millis — это именно то, что нам нужно. Формат и значение представленной исходной метрики поясняются ниже:
# HELP jdbc_statement_execute_latency_millis Statement execute latency millis histogram
# TYPE jdbc_statement_execute_latency_millis histogram
jdbc_statement_execute_latency_millis_bucket{le="1.0",} 0.0
jdbc_statement_execute_latency_millis_bucket{le="2.0",} 898.0
jdbc_statement_execute_latency_millis_bucket{le="4.0",} 5065.0
jdbc_statement_execute_latency_millis_bucket{le="8.0",} 5291.0
jdbc_statement_execute_latency_millis_bucket{le="16.0",} 5319.0
jdbc_statement_execute_latency_millis_bucket{le="32.0",} 5365.0
jdbc_statement_execute_latency_millis_bucket{le="64.0",} 5404.0
jdbc_statement_execute_latency_millis_bucket{le="128.0",} 5405.0
jdbc_statement_execute_latency_millis_bucket{le="256.0",} 5458.0
jdbc_statement_execute_latency_millis_bucket{le="512.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="1024.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="2048.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="4096.0",} 5459.0
jdbc_statement_execute_latency_millis_bucket{le="+Inf",} 5459.0
jdbc_statement_execute_latency_millis_count 5459.0
jdbc_statement_execute_latency_millis_sum 27828.0
jdbc_statement_execute_latency_millis_bucket{le="1.0",} 0.0указывает, сколько раз время выполнения находится в пределах 1 миллисекунды, что в данном случае равно 0.jdbc_statement_execute_latency_millis_bucket{le="2.0",} 898.0указывает, сколько раз время выполнения находится в пределах 2 миллисекунд, что в данном случае равно 898.jdbc_statement_execute_latency_millis_bucket{le="4.0",} 5065.0указывает, сколько раз время выполнения находится в пределах 4 миллисекунд, что в данном случае равно 5065.- В строке 16 «+Inf» представляет статистику за пределами максимального времени выполнения, что в данном случае представляет статистику за пределами 4096 миллисекунд.
jdbc_statement_execute_latency_millis_count 5459.0представляет собой общее количество выполнений, которое в данном случае равно 5459.jdbc_statement_execute_latency_millis_sum 27828.0представляет общее время выполнения, которое в данном случае составляет 27828 миллисекунд.
ceil(sum(increase(jdbc_statement_execute_latency_millis_bucket{instance=~'192.168.65.2:39090', le!='+Inf'}[1m])) by (le))
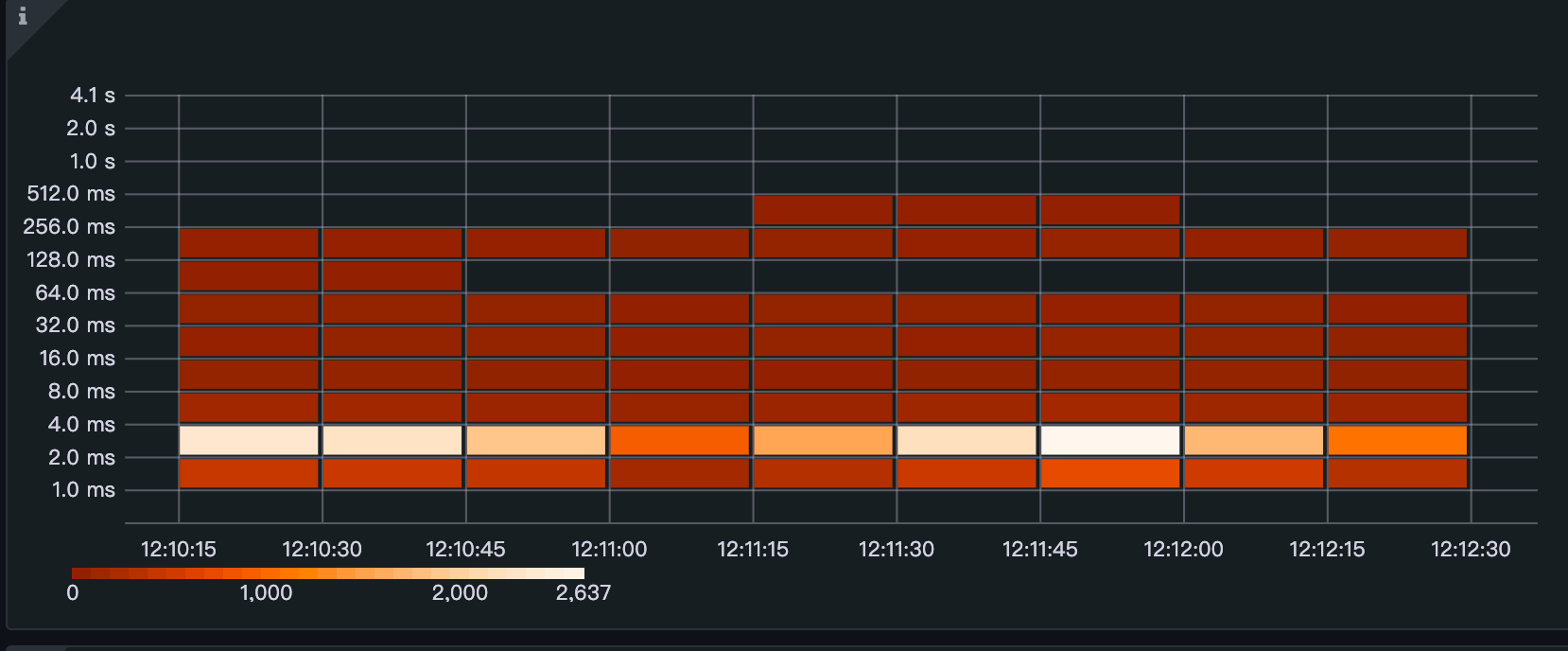
Тепловая карта эффективно визуализирует распределение времени выполнения, предоставляя ценную информацию о производительности системы.
Многие метрики можно собирать и анализировать с помощью Prometheus и Grafana. Отслеживая эти показатели и выявляя закономерности и тенденции в данных, пользователи могут получить ценную информацию о производительности и работоспособности своих систем и принять упреждающие меры для оптимизации производительности и предотвращения проблем до их возникновения.
Заключение
Приглашаем вас принять активное участие в расширении и улучшении показателей мониторинга ShardingSphere-JDBC. Если у вас есть какие-либо вопросы или предложения, не стесняйтесь поднимать их в GitHub issue [6] или присоединяйтесь к нашему сообществу Slack [7] для обсуждения.
Ссылки по теме
[1] Документация официального сайта ShardingSphere-JDBC
[2] Адрес загрузки ShardingSphere-Agent
[5] Официальная документация PromSQL
[6] Проблемы GitHub