Привет, однокурсники! Если вы следили за моими предыдущими постами, вы уже знакомы с механизмом внимания, значительным прорывом в области обработки естественного языка (NLP). Если нет, вернитесь к моему предыдущему сообщению в блоге здесь и познакомьтесь с этой увлекательной темой.
В этом блоге мы собираемся опираться на этот фундамент и исследовать одну из самых влиятельных архитектур НЛП на сегодняшний день: Трансформер. Эта революционная модель, рожденная из концепции «Внимание — это все, что вам нужно», стала движущей силой некоторых из самых впечатляющих языковых моделей, таких как GPT-3, BERT и T5.
Прежде чем мы углубимся в суть Трансформеров, важно понять ландшафт, из которого они произошли. Когда-то в мире обработки естественного языка (NLP) доминировали модели рекуррентных нейронных сетей (RNN) и долговременной памяти (LSTM). Эти архитектуры, будучи революционными сами по себе, демонстрировали ограничения, стимулировавшие разработку новых, более эффективных моделей.
Рекуррентные нейронные сети (RNN): память с ограничениями
RNN были разработаны для обработки последовательных данных, что делает их особенно подходящими для задач, связанных с временными или хронологическими размерами, такими как анализ текста, музыки и речи. Ключевой особенностью, отличающей RNN от базовых искусственных нейронных сетей (ANN), была их внутренняя память, позволяющая им использовать информацию из предыдущих входных данных для прогнозирования будущих результатов.
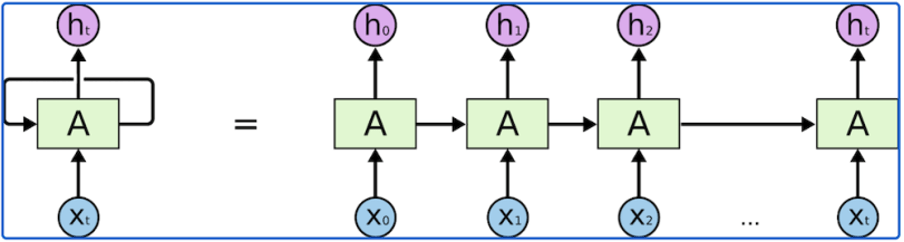
Однако RNN не были лишены недостатков. Последовательный характер их обработки делал их медленными и подверженными ошибкам при работе с длинными последовательностями. Они также были подвержены проблеме исчезающего градиента, когда градиенты, используемые для обновления весов сети во время обучения, становились чрезвычайно малыми, из-за чего сети было сложно изучать долгосрочные зависимости.
Долговременная кратковременная память (LSTM): скачок вперед, но недостаточный
LSTM, более продвинутый тип RNN, был разработан для решения некоторых из этих проблем. LSTM представили ветвь «пропустить», позволяющую информации обходить определенные этапы обработки, повышая способность сети сохранять информацию в течение более длительных периодов и уменьшая влияние исчезающих градиентов.

Несмотря на эти улучшения, LSTM оставались дорогостоящими в вычислительном отношении и сложными для обучения, особенно для последовательностей, превышающих 100 слов. Хотя они были шагом в правильном направлении, было ясно, что для более эффективного НЛП необходим новый подход.
Подготовка к работе: обзор механизмов внимания
Прежде чем мы отправимся в путешествие по лабиринту моделей трансформеров, давайте вернемся к концепции механизмов внимания. Эти гениальные устройства позволяют нейронным сетям расставлять приоритеты в релевантной информации при обработке данных последовательности. Они действуют как прожектор мозга, сосредотачиваясь на важных частях и затемняя остальные. Этот метод оказался жизненно важным в мире НЛП, обеспечивая основу для архитектуры Трансформера, которую мы собираемся исследовать.

Рассвет Трансформеров: инновация, изменившая правила игры
Трансформеры ворвались на сцену НЛП в 2017 году с влиятельной статьей «Внимание — это все, что вам нужно» Васвани и др. Эта новая архитектура модели взяла концепцию внимания и расширила ее, в результате чего была создана структура, полностью основанная на само-внимании. Эта конструкция позволила преобразователям обрабатывать входные последовательности параллельно, а не последовательно, преодолев барьеры скорости вычислений и ограничений памяти, которые мешали их предшественникам RNN и LSTM.

Трансформер внутри: взгляд на архитектуру
Модель Transformer состоит из двух основных компонентов: Encoder и Decoder. Обе части состоят из нескольких слоев нейронных сетей с самостоятельным вниманием и прямой связью, что позволяет им обрабатывать сложные преобразования последовательностей и делать точные прогнозы.
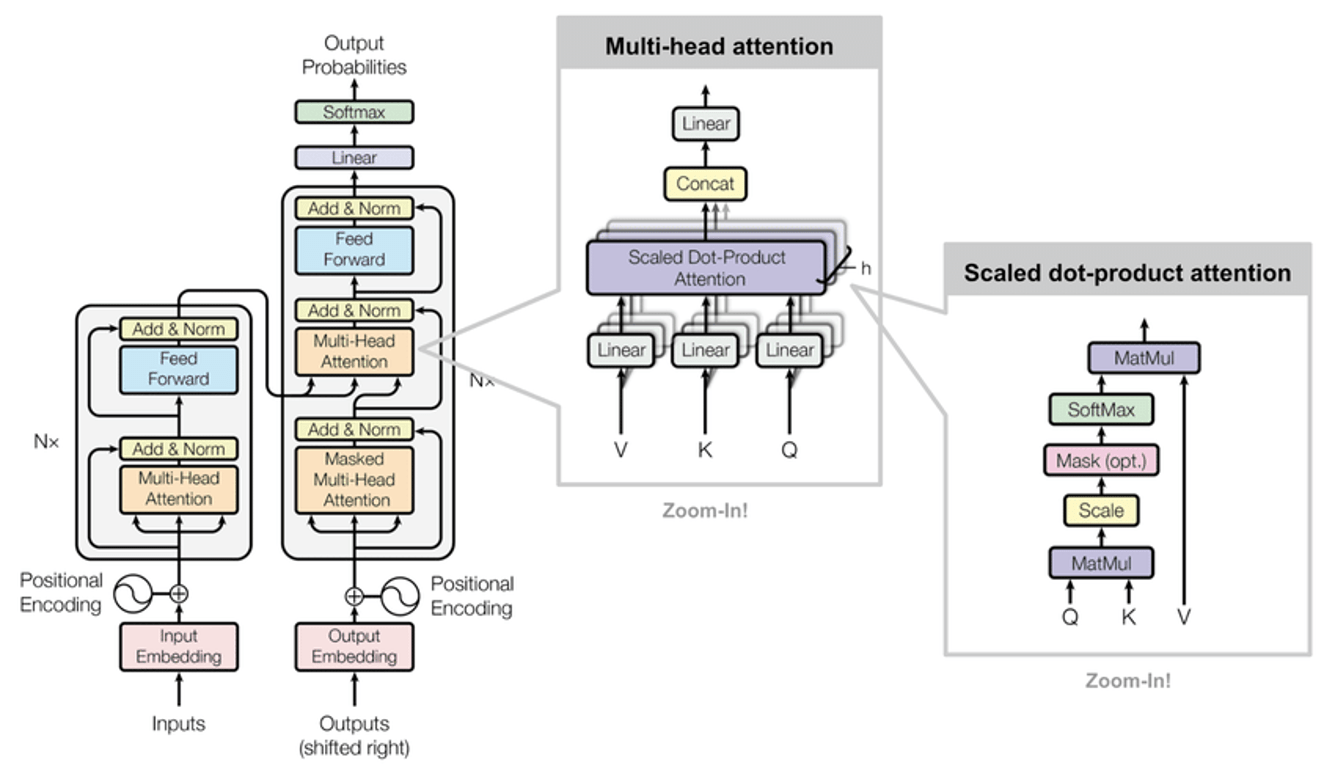
Кодер: прослушивание ввода
Давайте подумаем о кодировщике как о маэстро оркестра, где каждый инструмент в ансамбле представляет собой элемент в нашей входной последовательности. Каждый инструмент играет свою роль, но задача маэстро — понять, как каждая нота влияет на общую мелодию. Это то, что делает наш кодировщик — он обрабатывает входные данные, улавливает контекст и переводит его на язык, понятный модели.
Каждый слой кодировщика работает как высокочувствительное ухо, прислушиваясь к различным частям входной последовательности с помощью магии собственного внимания. Этот процесс подобен прожектору, освещающему различные части последовательности, понимая их значение и кодируя эту информацию таким образом, чтобы фиксировать сложные отношения в данных.
Результат? Набор векторов, каждый из которых является дистиллированным представлением входного элемента, но не изолированно — вместо этого он подобен богатому контекстуальному снимку роли этого элемента в общей схеме последовательности. Как будто наш маэстро Кодировщик не только слышит каждый инструмент, но и понимает, как каждая нота влияет на мелодию, ритм и гармонию произведения.

Декодер: подготовка вывода
Представьте, что вы находитесь в гончарной мастерской мирового класса. Вы видели, как сырая, бесформенная глина превращается в красиво структурированный горшок в умелых руках ремесленника — Кодировщика, в нашей аналогии с Трансформером. Теперь пришло время для последних штрихов, украшений, которые сделают этот горшок по-настоящему уникальным. Вот тут-то и вступает наш Декодер, мастер в мире трансформеров.
Имея в своем арсенале контекстно-богатые векторы, дар Кодировщика, Декодер приступает к обработке выходной последовательности, формируя и формируя ввод в окончательную форму, которая служит нашей цели. Это не просто задача копирования и вставки, а сложный процесс понимания, интерпретации и создания.
Декодер, как и его партнер, Кодировщик, также использует силу внутреннего внимания. Но вот где сюжет сгущается. В нем используется хитрая вариация, известная как маскированное самовнимание. Этот оригинальный прием гарантирует, что предсказание в данной позиции зависит только от известных выходных данных из более ранних позиций, эффективно сохраняя хронологическую целостность последовательности. Это подобно нашему мастеру-ремесленнику, тщательно изготавливающему каждую часть горшка в определенной последовательности, следя за тем, чтобы каждый шаг зависел только от предыдущих.
В грандиозном концерте модели «Трансформер» Декодер — солист, который приносит представление домой. Он выходит на сцену, вооруженный контекстом и пониманием, и создает результат, который является одновременно значимым и последовательным.
Разоблачение скрытого внутреннего внимания: секретный агент в декодере
Прежде чем мы углубимся в тонкости этой секретной операции, давайте освежим наше понимание внимания к себе. Это способ декодера сосредоточиться на различных частях входных данных, взвешивая их в зависимости от их актуальности для текущей задачи. Но в декодере мы хотим гарантировать, что каждая выходная позиция может относиться только к более ранним позициям в последовательности или к текущей позиции, а не к будущим позициям. Мы не хотим портить финал, даже не начав!
Вот где наш секретный агент, замаскированное внимание к себе, вступает в игру. По сути, это само-внимание с завязанными глазами, которое не позволяет ему видеть будущие позиции в последовательности. Это гарантирует, что прогноз для данного шага не зависит от каких-либо будущих шагов.
Представьте, что вы пытаетесь предсказать следующее слово в предложении. Если вы находитесь на слове «быстрая коричневая лиса», вы не хотите заглядывать вперед и видеть «перепрыгивает через ленивую собаку». Лисе еще не время прыгать! Маска в замаскированном внутреннем внимании гарантирует именно это, позволяя декодеру поддерживать напряжение и целостность последовательности.
Маска реализуется довольно просто, путем установки будущих позиций на отрицательную бесконечность (или очень большое отрицательное число) перед шагом softmax в расчете собственного внимания. Поскольку softmax очень большого отрицательного числа близок к нулю, это эффективно обнуляет будущие позиции и не позволяет декодеру заглянуть вперед.

Секретный соус: многозадачное внимание
Представьте себе: вы на шумной вечеринке, пытаетесь поддержать разговор. Это мелодия фоновой музыки, звон бокалов, смех соседней группы и шепот человека, с которым вы разговариваете. Среди этого хаоса ваш мозг проделывает фантастическую работу, сосредотачиваясь на важных для вас частях, отфильтровывая фоновый шум и понимая разговор. Вы можете думать о механизме Multi-Head Attention как о мозге модели Transformer, выполняющем очень похожую работу.
Секретный ингредиент рецепта успеха Transformer — это механизм Multi-Head Attention. Эта увлекательная функция позволяет модели жонглировать несколькими мячами одновременно, одновременно настраиваясь на разные части входной последовательности, как вы на вечеринке. Это похоже на наличие нескольких наборов глаз, каждый из которых может сосредоточиться на разных аспектах данных, обеспечивая богатое, многогранное понимание контекста.
Думайте о каждом руководителе как о человеке, который является экспертом в своем собственном праве. Один может быть фантастическим в понимании тона текста, в то время как другой может преуспеть в улавливании сложных грамматических структур. Когда вы объединяете этих экспертов и объединяете их идеи, вы получаете более полное и тонкое понимание данных.
С помощью этого механизма Transformer может динамически решать, какие части последовательности имеют значение на каждом этапе генерации выходных данных, уделяя больше внимания одним частям и меньше — другим. Это делает Transformer легко адаптируемой моделью, способной понимать сложные закономерности и отношения в данных.
Позиционное кодирование: молчаливый герой
Давайте на минутку представим себе оркестр — ансамбль различных инструментов, каждый из которых играет свою роль в создании гармоничной симфонии. А что, если бы мы убрали дирижера, того, кто задает темп и направляет оркестрантов в их исполнении? Результатом был бы диссонирующий хаос. Точно так же в замысловатом танце архитектуры Трансформера один безмолвный герой задает ритм и направляет процесс: Позиционное кодирование.
Преобразователь, способный работать со всей входной последовательностью параллельно, обеспечивает революционную скорость выполнения задач последовательного преобразования. Но с этой силой приходит уникальная проблема. В отличие от своих аналогов RNN и LSTM, Transformer по своей сути не понимает порядок или последовательность входных данных. По сути, это все равно, что пытаться читать книгу, просматривая все страницы сразу — вы можете уловить суть, но поток и нюансы повествования будут потеряны.
Вот где наш невоспетый герой, позиционное кодирование, начинает действовать. Эта функция наполняет Transformer пониманием относительного положения или порядка элементов в последовательности. Это как дирижер нашего оркестра, тонко указывая, когда должен играть каждый инструмент, направляя мелодию к ее крещендо.
В задачах, где последовательность ввода напрямую влияет на интерпретацию, таких как языковой перевод или понимание предложений, позиционное кодирование не просто важно — оно незаменимо. Представьте, что вы переводите предложение с английского на французский без учета порядка слов; результатом будет беспорядочный беспорядок. Позиционное кодирование предотвращает такой хаос, сохраняя целостность последовательности и смысла, который она несет.
Наследие трансформера: BERT, GPT и не только
Воздействие Transformer выходит за рамки его автономных возможностей. Его архитектура стала основой для некоторых из наиболее влиятельных моделей современного NLP, включая BERT (представления двунаправленного кодировщика из преобразователей) и GPT (генеративный предварительно обученный преобразователь). Эти модели добились значительных успехов в таких задачах, как генерация текста, анализ настроений и машинный перевод, продолжая наследие Transformer.

Последние мысли
Архитектура Transformer изменила правила игры в мире НЛП, предоставив мощный, масштабируемый и эффективный подход к обработке данных последовательности. Его инновационное использование механизмов внимания, позиционного кодирования и параллельной обработки позволило ему выйти на новый уровень в понимании и создании человеческого языка.
Хотя сегодня мы многое рассмотрели, мы только коснулись того, на что способны Трансформеры. Наша роль как специалистов по данным состоит в том, чтобы продолжать исследовать, экспериментировать и расширять эти модели для решения новых и все более сложных проблем.
Итак, являетесь ли вы опытным специалистом по данным или только начинаете свое путешествие, я надеюсь, что этот блог пробудил стремление к дальнейшему изучению, копанию глубже и раскрытию секретов и потенциальных импровизаций, основанных на Трансформерах. Кто знает? Возможно, именно вы откроете следующий большой прорыв в НЛП.

До следующего раза продолжайте исследовать, учиться и помните — в мире науки о данных путь так же важен, как и пункт назначения. Удачного погружения в данные!