В этом блоге я попытался сжать тему линейной регрессии до 12 пунктов. Я изложил базовое концептуальное понимание темы и постарался сделать все как можно проще. Я очень уверен, что если вы охватите эти вопросы линейной регрессией, вы сможете ответить на все вопросы интервью, связанные с линейной регрессией.
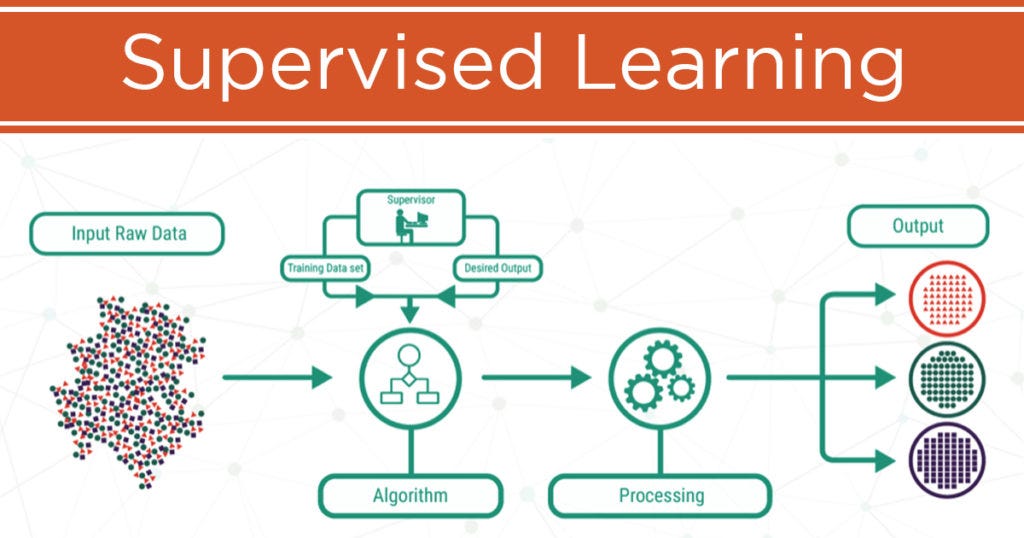
контролируемое обучение
Обучение с учителем — это тип машинного обучения, при котором мы учим компьютерную модель делать прогнозы или принимать решения на основе помеченных примеров. Это включает в себя предоставление модели входных данных и соответствующих желаемых выходных или целевых значений.
Проще говоря, контролируемое обучение похоже на обучение компьютера распознавать закономерности или делать прогнозы, показывая ему примеры с четкими метками или ответами. Это похоже на то, как учитель направляет ученика, предоставляя ему решенные упражнения или примеры.
Цель обучения с учителем — построить модель, которая хорошо обобщает невидимые данные, то есть она может точно прогнозировать или классифицировать новые примеры, которые не были частью обучающего набора. Предоставляя модели помеченные примеры, она может учиться на предоставленных знаниях и делать прогнозы или решения самостоятельно.
Он делится на два типа: классификация и регрессия.
Классификация и ее тип
Классификация — это тип обучения с учителем в машинном обучении, целью которого является присвоение входных данных предопределенным категориям или классам. Здесь целевая переменная может иметь только дискретный набор значений.
- Двоичная классификация имеет два класса и относит каждую выборку к одному из них.
- Мультиклассовая классификация имеет три или более классов, и каждый образец принадлежит только к одному классу.
- Многометочная классификация присваивает каждому образцу несколько меток с возможностью привязки к более чем одному классу.
Регрессия
Проще говоря, регрессия похожа на поиск математической формулы или закономерности, описывающей, как одна или несколько переменных связаны с конкретным результатом. Это позволяет нам делать прогнозы о непрерывном значении, например прогнозировать цены на жилье на основе таких характеристик, как размер, местоположение и количество комнат.
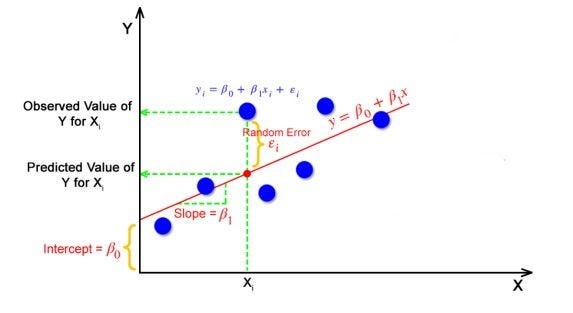
Простая линейная регрессия
Простая линейная регрессия — это базовая форма регрессионного анализа, которая моделирует взаимосвязь между двумя переменными: независимой переменной (часто обозначаемой как «x») и зависимой переменной (часто обозначаемой как «y»). Он предполагает линейную связь между этими переменными. Цель простой линейной регрессии — найти наиболее подходящую линию, представляющую эту связь. Линия определяется путем оценки наклона (обозначается как «β1») и точки пересечения (обозначается как «β0») линии.
Здесь следует отметить одну вещь: линейная регрессия предполагает линейность параметров модели и не обязательно линейность между функциями и целью. Функция регрессии log(y) = A + B(log(x)) + C является линейной регрессией, тогда как y = (exp(A + Bx1)/(1 + exp(A + Bx1))) + C не является линейный, поскольку его нельзя преобразовать в уравнение с линейными параметрами.
Допущения линейной регрессии
- Между зависимыми и независимыми переменными существует линейная зависимость.
- Независимая переменная должна иметь нормальное распределение
- Позаботьтесь о мультиколлинеарности. Если VIF (коэффициент инфляции дисперсии) больше 5, то это случай мультиколлинеарности.
- Масштабирование функций требуется, так как за сценой используется алгоритм градиентного спуска.
- Гомоскедастичность (одинаковая дисперсия) должна быть в случае остатков
- Если в данных присутствует гетероскедастичность, означающая, что изменчивость остатков (истинное значение — прогнозируемое значение) различается на разных уровнях независимых переменных, предположения о линейной регрессии могут быть нарушены.
- Нет автокорреляции/последовательной корреляции по остаткам. означает, что остатки (ошибки) регрессионной модели не должны коррелировать друг с другом.
Множественная линейная регрессия
Множественная линейная регрессия — это расширение простой линейной регрессии, которое позволяет анализировать взаимосвязь между зависимой переменной (целевой переменной) и несколькими независимыми переменными (переменными-предикторами). Он используется, когда ожидается, что отношения между зависимой переменной и предикторами будут более сложными и будут включать несколько факторов.
Целью множественной линейной регрессии является оценка коэффициентов уравнения регрессии, которые лучше всего соответствуют данным. Уравнение принимает вид:
y = β0 + β1x1 + β2x2 + … + βn*xn
где:
- y - зависимая переменная (целевая переменная),
- x1, x2, …, xn — независимые переменные (переменные-предикторы),
- β0 — точка пересечения (значение y, когда все предикторы равны нулю),
- β1, β2, …, βn — коэффициенты, представляющие влияние каждой переменной-предиктора на зависимую переменную.
Различные функции потерь в линейной регрессии
Функция потерь используется для оценки производительности модели машинного обучения путем количественной оценки ошибки или потери между прогнозируемым выходом и фактическим целевым значением для одной точки данных.
Функция стоимости, также известная как целевая функция или функция ошибок, является мерой общей производительности модели машинного обучения на всем наборе обучающих данных. Он получается путем усреднения функции потерь по всем обучающим примерам. Функция стоимости учитывает совокупную ошибку или потерю модели по всем точкам данных.
- Среднеквадратическая ошибка (MSE): MSE — это наиболее часто используемая функция потерь в линейной регрессии. Он вычисляет среднеквадратичную разницу между прогнозируемыми значениями и фактическими значениями. Формула для MSE:
MSE = (1/n) * Σ(y_pred — y_actual)²
где:
- n - количество точек данных,
- y_pred — прогнозируемое значение зависимой переменной,
- y_actual — фактическое значение зависимой переменной.
Преимущество MSE в том, что есть только один глобальный минимум, и он дифференцируем.
Недостатком MSE является то, что большие ошибки наказываются сильнее, чем мелкие.
2. Средняя абсолютная ошибка (MAE): MAE — это альтернативная функция потерь, которая измеряет среднюю абсолютную разницу между прогнозируемыми значениями и фактическими значениями. Формула MAE:
MAE = (1/n) * Σ|y_pred — y_actual|
MAE менее чувствительна к выбросам по сравнению с MSE, поскольку не возводит ошибки в квадрат. Он обеспечивает более надежную меру средней ошибки прогнозирования.
Выбор между MSE и MAE зависит от конкретных требований задачи и характеристик данных. MSE обычно используется, когда основное внимание уделяется уменьшению общей квадратичной ошибки, в то время как MAE предпочтительнее, когда важно минимизировать влияние выбросов.
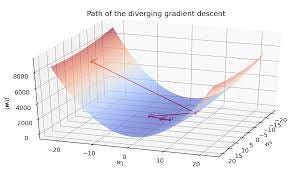
Алгоритм градиентного спуска
- Давайте рассмотрим случай простой линейной регрессии с функцией потерь в качестве MSE.
2. Пусть целевое значение y известно как y=β1x+β0.
3. Пусть yactual будет истинными значениями y. Нам нужно оптимизировать значения β1 и β0, чтобы наша модель выучила наилучшую линию соответствия.
4. Функция стоимости: J(β1,β0)= (1/n) * Σ(β1x+β0-yactual)2.
5. Примените формулу обновления веса
β1_новый = β1_старый — α * градиент
β0_новый = β0_старый — α * градиент
где:
- α - скорость обучения,
- градиент — это градиент функции стоимости по отношению к весу.
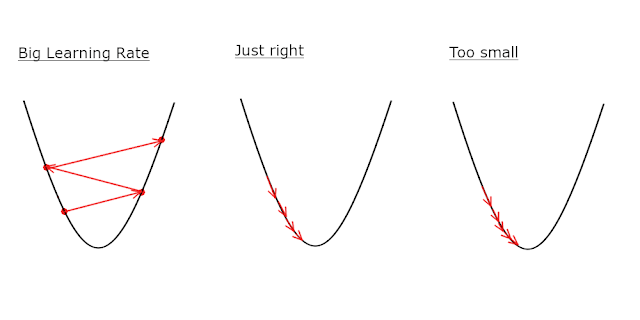
9. Скорость обучения
Скорость обучения является важным гиперпараметром в алгоритмах оптимизации на основе градиента, таких как градиентный спуск. Он определяет размер шага, предпринимаемого на каждой итерации для обновления параметров модели (весов). Выбор подходящей скорости обучения необходим для достижения эффективной и стабильной конвергенции во время обучения. Диапазон скорости обучения обычно зависит от конкретной проблемы и набора данных. Вот несколько рекомендаций по выбору разумного диапазона скоростей обучения:
- Слишком маленькая скорость обучения: если скорость обучения слишком мала, конвергенция будет медленной. Модель потребует больше итераций для достижения оптимального решения, а процесс обучения может занять больше времени. В крайних случаях слишком маленькая скорость обучения может привести к тому, что модель застрянет в локальных минимумах или вообще не сойдется.
- Слишком большая скорость обучения. С другой стороны, если скорость обучения слишком велика, обновления параметров модели будут слишком значительными на каждой итерации. Это может привести к выходу за пределы оптимального решения и колебаниям вокруг него. Процесс обучения может стать нестабильным, и модель может не сходиться или расходиться вообще.
- Разумный диапазон: разумный диапазон скорости обучения обычно составляет от 0,001 до 0,1. Этот диапазон обеспечивает хорошую отправную точку для большинства задач машинного обучения. В этом диапазоне вы можете экспериментировать и регулировать скорость обучения в зависимости от конкретной проблемы и набора данных. Меньшие наборы данных или проблемы с меньшим количеством функций могут выиграть от меньшей скорости обучения, в то время как большие наборы данных или более сложные проблемы могут потребовать большей скорости обучения.
- Графики скорости обучения: в некоторых случаях использование фиксированной скорости обучения на протяжении всего процесса обучения может быть неоптимальным. Графики скорости обучения могут быть реализованы для динамической регулировки скорости обучения во время обучения. Общие графики включают снижение скорости обучения, когда скорость обучения уменьшается с течением времени, и отжиг скорости обучения, когда скорость обучения уменьшается на определенных этапах или эпохах. Эти расписания помогают точно настроить скорость обучения в зависимости от прогресса обучения.
10. Показатели эффективности (оценки)
R-квадрат (R2) и скорректированный R-квадрат — это обычно используемые метрики оценки в регрессионном анализе для оценки степени соответствия регрессионной модели. Они предоставляют информацию о том, насколько хорошо модель соответствует данным, и о доле дисперсии зависимой переменной, которая может быть объяснена независимыми переменными.
R-квадрат (R2): R-квадрат — это статистическая мера, представляющая долю дисперсии зависимой переменной, которую можно предсказать на основе независимых переменных в регрессионной модели. Он варьируется от 0 до 1, где:
- R2 = 0 указывает на то, что независимые переменные не обладают объяснительной силой при прогнозировании зависимой переменной.
- R2 = 1 указывает на идеальное соответствие, когда вся изменчивость зависимой переменной объясняется независимыми переменными.
R-квадрат рассчитывается следующим образом: R2 = 1 — (SSR / SST)
где:
- SSR (сумма квадратов остатков) представляет собой сумму квадратов разностей между прогнозируемыми значениями и фактическими значениями зависимой переменной.
- SST (Общая сумма квадратов) представляет собой сумму квадратов разностей между фактическими значениями и средним значением зависимой переменной.
Более высокое значение R-квадрата предполагает лучшее соответствие модели данным. Однако сам по себе R-квадрат имеет ограничения, особенно при добавлении в модель большего количества независимых переменных. Он имеет тенденцию к увеличению по мере добавления дополнительных переменных, независимо от их истинной значимости для прогнозирования зависимой переменной. Здесь в игру вступает скорректированный R-квадрат.
Скорректированный R-квадрат: Скорректированный R-квадрат — это скорректированная версия R-квадрата, которая наказывает за включение в модель нерелевантных или ненужных независимых переменных. Он учитывает количество независимых переменных и размер выборки, чтобы обеспечить более точную оценку соответствия модели.
Скорректированный R-квадрат рассчитывается следующим образом: Скорректированный R2 = 1 — [(1 — R2) * ((n — 1) / (n — k — 1))]
где:
- n — количество наблюдений (размер выборки).
- k - количество независимых переменных (включая термин перехвата).
Скорректированный R-квадрат корректирует значение R-квадрата на основе количества независимых переменных и размера выборки. Это наказывает за добавление ненужных переменных, что приводит к более низкому значению, если дополнительные переменные не вносят значительного вклада в объяснительную способность модели.
Таким образом, R-квадрат дает представление о том, насколько хорошо независимые переменные объясняют изменение зависимой переменной, в то время как скорректированный R-квадрат корректирует количество переменных в модели. Важно учитывать обе метрики при оценке согласия и значимости переменных в регрессионной модели.
Могут ли показатели R2 учитываться в линейной регрессии
Нет, показатель R-квадрат (R2) в линейной регрессии не может быть отрицательным. Значение R2 всегда находится в диапазоне от 0 до 1 включительно.
R2 представляет собой долю дисперсии зависимой переменной, которая объясняется независимыми переменными в регрессионной модели. Значение 0 указывает на то, что независимые переменные не обладают объяснительной силой, а значение 1 указывает на идеальное соответствие, когда вся изменчивость зависимой переменной объясняется независимыми переменными.
Если значение R2 отрицательное, это указывает на то, что регрессионная модель работает хуже, чем простая горизонтальная линия (среднее значение зависимой переменной) при прогнозировании зависимой переменной. Однако отрицательные значения R2 не имеют смысла и не интерпретируются в контексте линейной регрессии.
Важно отметить, что R2 имеет свои ограничения и должен интерпретироваться в сочетании с другими показателями оценки и знанием предметной области. На него могут влиять предположения и ограничения линейной регрессии, такие как линейность, независимость и отсутствие выбросов или влиятельных точек.
12. Ограничения линейной регрессии
- Предположение о линейности: линейная регрессия предполагает линейную связь между зависимой переменной и независимыми переменными. Он может не точно фиксировать сложные, нелинейные отношения. Если истинная связь нелинейна, линейная регрессия может плохо соответствовать данным.
- Предположение о независимости: линейная регрессия предполагает, что наблюдения независимы друг от друга. Если между наблюдениями существует зависимость или корреляция, например, во временных рядах или пространственных данных, линейная регрессия может давать необъективные или неэффективные оценки.
- Выбросы и влиятельные точки: линейная регрессия чувствительна к выбросам и влиятельным точкам, которые непропорционально влияют на оценочные коэффициенты. Выбросы могут оказать существенное влияние на соответствие модели и могут исказить результаты.
- Мультиколлинеарность: линейная регрессия предполагает, что независимые переменные не сильно коррелируют друг с другом. При наличии мультиколлинеарности (высокой корреляции) между независимыми переменными становится сложно точно интерпретировать коэффициенты, и оценки могут быть нестабильными.
- Допущение гомоскедастичности: линейная регрессия предполагает постоянную дисперсию остатков (гомоскедастичность). Если изменчивость остатков непостоянна (гетероскедастичность), модель может недооценивать или переоценивать неопределенность оценок, что приводит к ненадежным выводам.
- Независимость от ошибок: линейная регрессия предполагает, что ошибки (остатки) независимы и одинаково распределены. Нарушения этого предположения, такие как автокорреляция в данных временных рядов, могут привести к необъективным оценкам и неверным выводам.
- Категориальные и нелинейные переменные. Линейная регрессия предназначена для непрерывных переменных. Он может не обрабатывать категориальные переменные напрямую, что требует дополнительных методов, таких как однократное кодирование. Нелинейные отношения между переменными могут потребовать преобразований или использования методов нелинейной регрессии.
- Экстраполяция: линейную регрессию следует использовать в пределах диапазона наблюдаемых данных. Экстраполяция модели за пределы наблюдаемого диапазона может быть ненадежной, поскольку предположения модели могут не выполняться, а прогнозы могут быть неточными. По этой причине мы не можем использовать линейную регрессию для анализа временных рядов (на самом деле любой регрессор в классическом машинном обучении может только для задач интраполяции, а не экстраполяции. Поэтому нам нужны такие модели, как ARIMA, SARIMA, SARIMAX, VARIMAX и т. д. в анализе временных рядов).
- Переоснащение или недообучение. Линейная регрессия может страдать от проблем переобучения или недообучения. Переобучение происходит, когда модель слишком близко подходит к обучающим данным и не может хорошо обобщить новые данные. Недообучение происходит, когда модель слишком проста и не может уловить основные закономерности в данных.