
В этой статье мы увидим, что такое функции распределения вероятностей.
Начнем с того, что такое переменные?
Переменные — это заполнители для неизвестных значений.
Есть 2 типа переменных
Алгебраические переменные
В алгебре переменные обычно используются для представления неизвестных величин или значений, которые могут измениться.
В таких уравнениях, как 2x + 5 = 15, переменная x представляет собой неизвестное значение, которое мы пытаемся найти. х = 5
Случайные переменные
Случайная величина — это переменная, которая может принимать различные значения в зависимости от результата случайного события или эксперимента.
Предположим, вы стоите на обочине дороги и угадываете рост проходящих людей. Здесь мероприятие измеряет рост людей. Он представлен Х.
X = {5.2, 5.6, 4.8, 6.0, 5.9 }
Примечание. В теории вероятностей и статистике случайные величины обычно обозначаются заглавными буквами, например X, Y или Z. Использование заглавных букв помогает отличить случайные величины от алгебраических величин, которые обычно обозначаются строчными буквами, такими как x, y. , или з.
Типы случайных величин
Случайные переменные можно разделить на два основных типа в зависимости от значений, которые они могут принимать:
Дискретная случайная переменная. Эти случайные величины могут принимать только определенные значения из счетного множества. Эти значения часто представляют собой целые числа или целые числа. Например, количество учеников в классе, результат броска игральной кости или количество автомобилей, проезжающих за данный час, — все это примеры дискретных случайных величин.
Непрерывная случайная переменная. Эти случайные переменные могут принимать любое значение в пределах указанного диапазона или интервала. Значения непрерывных случайных величин часто измеряются и могут включать десятичные числа. Примеры непрерывных случайных величин включают рост человека, время, которое требуется машине, чтобы пересечь светофор, или температуру в помещении.
Теперь, когда мы разобрались с типами переменных, мы перейдем к изучению вероятностных распределений.
Что такое распределения вероятностей?
Распределение вероятностей — это список всех возможных исходов случайной величины вместе с соответствующими значениями вероятности.
Давайте разберемся на примере.
Предположим, происходит подбрасывание монеты. Мы построим таблицу распределения вероятностей для события.

Событие бросания игральной кости.

Проблема с распространением?
Во многих сценариях количество результатов может быть намного больше, и поэтому записывать таблицу будет утомительно. Что еще хуже, количество возможных результатов может быть бесконечным, и в этом случае удачи в написании таблицы для этого.
Пример — рост людей, бросок 10 кубиков вместе.
Решение ??
Что, если мы воспользуемся математической функцией для моделирования связи между исходом и вероятностью?
Предположим, мы называем вероятность события Y, а исход X. Тогда мы можем создать функцию Y = f(X).
Примечание. Во многих случаях таблица распределения вероятностей и функции распределения вероятностей используются взаимозаменяемо.
Типы распределения вероятностей
Распределение вероятностей для дискретной случайной величины

Распределение вероятностей для непрерывной случайной величины

Почему важны распределения вероятностей?
- Дает представление о форме/распределении данных.
Пример. В распределении оценок учащихся в классе левостороннее распределение может свидетельствовать о том, что значительное число учащихся учатся хорошо или выше среднего, в то время как правостороннее распределение может указывать на более высокую долю более слабых результатов.
- И если наши данные следуют известному распределению, мы автоматически многое знаем о данных.
Пример: распределения вероятностей помогают нам в ситуациях, когда наши данные следуют хорошо известному распределению. Например, если мы определяем, что наши данные следуют нормальному распределению, мы можем использовать свойства нормального распределения, чтобы делать прогнозы и делать выводы. Например, мы можем с уверенностью заявить, что примерно 68,26% данных находятся в пределах одного стандартного отклонения от среднего.
Функции распределения вероятностей
Функция распределения вероятностей — это математическая функция, описывающая вероятность получения различных значений случайной величины в конкретном распределении вероятностей.
Функция распределения вероятностей дискретной случайной величины называется вероятностной функцией массы (PMF).
Функция распределения вероятностей непрерывной случайной величины называется функцией плотности вероятности (PDF).
Мы можем сделать кумулятивные распределительные функции (CDF) из PMF и PDF.
Функция массы вероятности (PMF)
PMF означает функцию массы вероятности. Это математическая функция, описывающая распределение вероятностей дискретной случайной величины.
PMF дискретной случайной величины присваивает вероятность каждому возможному значению случайной величины. Вероятности, присваиваемые PMF, должны удовлетворять двум условиям:
1. Вероятность, приписываемая каждому значению, должна быть неотрицательной (т. е. больше
или равна нулю).
2. сумма вероятностей, присвоенных всем возможным значениям, должна равняться 1.
Математически это можно записать как
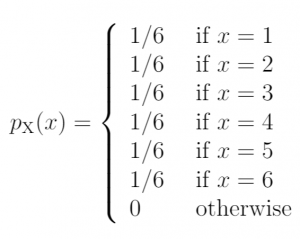
Примеры:
Распределение Бернулли

Биномиальное распределение

Совокупная функция распределения (CDF) PMF
Кумулятивная функция распределения (CDF) описывает вероятность того, что случайная величина X с заданным распределением вероятностей будет найдена со значением, меньшим или равным x.
F(x) = P(X <= x)
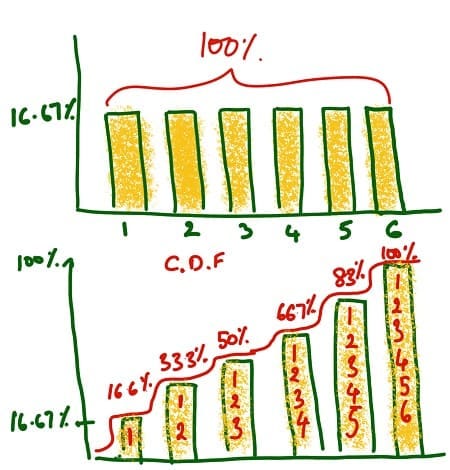
Ранее мы видели, что для игры в кости вероятность равна 1/6 для всех значений X от 1 до 6.
Предположим, мы хотим найти вероятность найти 3 или менее 3.
P(X <= 3) = P(X = 3) + P(X = 2) + P(X = 1) = 1/2
Функция плотности вероятности (PDF)
PDF означает функцию плотности вероятности. Это математическая функция, описывающая распределение вероятностей непрерывной случайной величины.

В PMF ось y представляла вероятность, но в PDF ось y представляла не вероятность, а плотность вероятности.
Мы получим такие вопросы:
- Почему плотность вероятности, а не вероятность?
В случае непрерывных случайных величин присвоение вероятности непосредственно отдельным значениям становится проблематичным из-за бесконечного числа возможных значений. Вместо этого используется понятие плотности вероятности. Плотность вероятности представляет собой относительную вероятность того, что случайная величина примет определенное значение в заданном диапазоне.
PDF обеспечивает относительную вероятность того, что случайная величина примет разные значения, а ее интеграл по диапазону дает вероятность того, что случайная величина попадет в этот диапазон.
Используя понятие плотности вероятности, мы можем эффективно описывать вероятности, связанные с непрерывными случайными величинами, и вычислять вероятности для интервалов, а не для отдельных значений. Этот подход необходим из-за бесконечного характера возможных значений в непрерывном распределении.
2. Что представляет площадь этого графика?
Область под графиком представляет собой вероятность попадания случайной величины в определенный интервал.
Важно отметить, что площадь под всей кривой PDF всегда равна 1, поскольку общая вероятность того, что случайная величина примет любое значение в пределах своего диапазона, составляет 100%. Это свойство гарантирует, что вероятности, назначенные PDF, действительны и непротиворечивы.
3. Как тогда рассчитать Вероятность?
Допустим, у нас есть PDF для роста взрослых, и мы хотим определить вероятность того, что рост взрослого человека окажется между 160 и 170 см. Мы рассчитали бы площадь под кривой PDF между этими двумя значениями высоты, чтобы получить интересующую вероятность.
4. Как рассчитывается график?
Оценка плотности
Оценка плотности – это статистический метод, используемый для оценки функции плотности вероятности
(PDF) случайной величины на основе набора наблюдений или данных. Проще говоря, это включает в себя оценку базового распределения набора точек данных.
Существуют различные методы оценки плотности, включая параметрические и непараметрические подходы. Параметрические методы предполагают, что данные следуют определенному распределению вероятностей (например, нормальному распределению), в то время как непараметрические методы не делают никаких предположений о распределении, а вместо этого оценивают его непосредственно на основе данных.
Обычно используемые методы оценки плотности включают оценку ядерной плотности
(KDE), оценку гистограммы и смешанные модели Гаусса (GMM). Выбор метода зависит от конкретных характеристик данных и предполагаемого использования оценки плотности.
Параметрическая оценка плотности
Оценка параметрической плотности — это метод оценки функции плотности вероятности (PDF) случайной величины путем предположения, что базовое распределение принадлежит определенному параметрическому семейству распределений вероятностей, например нормальному, экспоненциальному или распределению Пуассона.
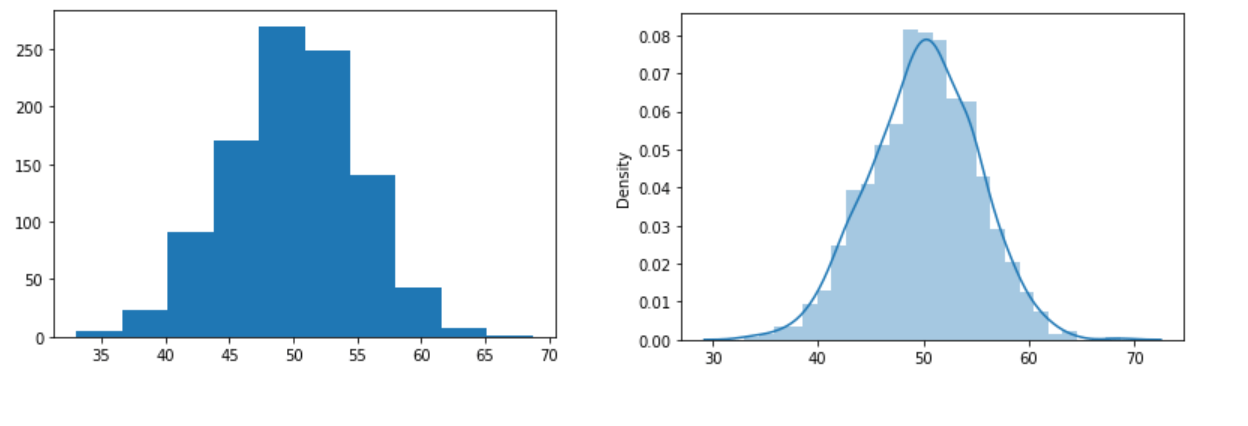
Предположим, у вас есть данные, следующие нормальному распределению со средним значением 50 и стандартным отклонением 5.
Для формулы нормального распределения для расчета PDF
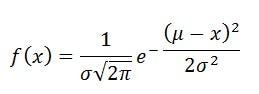
Мы знаем среднее значение и стандартное отклонение, и у нас есть точки данных x. Мы можем рассчитать PDF по приведенной выше формуле. Рисунок выше справа представляет PDF.
Непараметрическая оценка плотности (KDE)
Непараметрическая оценка плотности — это статистический метод, используемый для оценки функции плотности вероятности случайной величины без каких-либо предположений об основном распределении. Его также называют непараметрической оценкой плотности, поскольку он не требует
использования предопределенной функции распределения вероятностей, в отличие от параметрических методов, таких как распределение Гаусса.
Плюсы: не требует предположения о конкретном дистрибутиве.
Минусы: непараметрическая оценка плотности может потребовать значительных вычислительных ресурсов и может потребовать больше данных для получения точных оценок по сравнению с параметрическими методами.
Техника KDE включает использование функции ядра для сглаживания данных и создания непрерывной оценки базовой функции плотности.
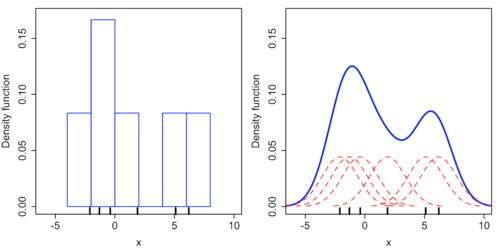
На приведенном выше рисунке наши данные не соответствуют каким-либо стандартным или известным распределениям, поэтому мы будем использовать непараметрический подход.

Рассматривая нашу точку данных как среднее значение, мы создадим нормальное распределение, как показано красным цветом выше. Теперь мы создадим проекцию, выделенную зеленым цветом, она пересекает нормальное распределение в 2 точках 0,03 и 0,04. Когда это суммируется, это дает значение 0,07, аналогичным образом мы выполним расчеты для всех точек данных.
Выше мы сказали, что, рассматривая нашу точку данных как среднее, мы нарисуем нормальное распределение, но для рисования нормального распределения вам нужны 2 параметра: среднее значение и стандартное отклонение. Стандартное отклонение известно как пропускная способность, более высокое стандартное отклонение будет формировать толстую кривую, а более низкое стандартное отклонение будет формировать тонкую кривую. Толстая кривая приводит к плавному KDE, а тонкая кривая приводит к остроконечному KDE.
Кумулятивная функция распределения (CDF) PDF
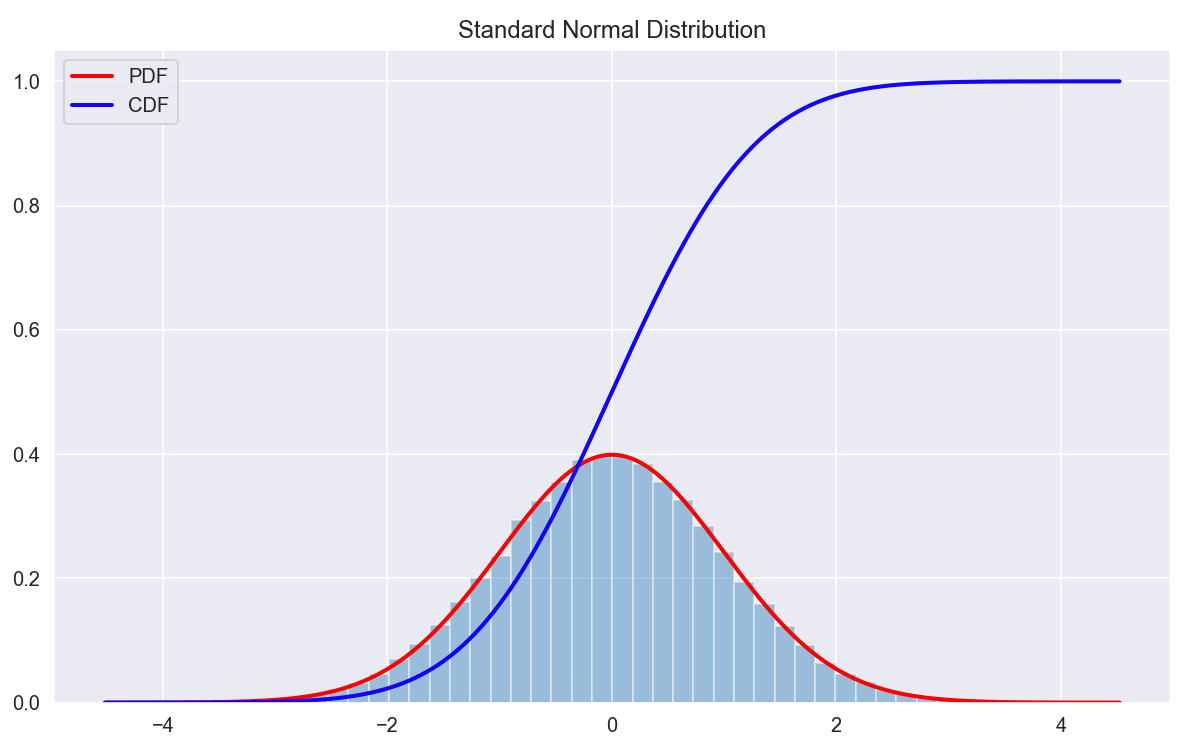
Скажем, x = 0, PDF даст вам вероятность P(x=0) = 0,4, но когда CDF P(x≤0) = 0,5 CDF даст вам вероятность до точки x=0, а PDF даст вам вероятность x =0.
Обобщить:
- PDF дает относительную вероятность попадания случайной величины в диапазон значений.
- CDF дает кумулятивную вероятность до определенного значения.