DuckDB чем-то напоминает распространенный подход к озеру, который вы видите повсюду, и может служить вычислительным механизмом на ваших платформах данных, где облачное хранилище используется для хранения, как обычно. Он может взаимодействовать с популярными инструментами, такими как dbt и Pandas.
Вы можете обернуть выполнение своих преобразований DuckDB с помощью инструментов оркестровки, таких как Airflow, Prefect или Dagster, или вы можете просто запустить несколько AWS Lambdas / Azure Functions, чтобы выполнять свои преобразования по дешевке без компромиссов.
Действительно ли мы знаем, как работать с облаком?
За годы внедрения облачных технологий мы поняли, что всегда следует масштабировать и избегать масштабирования. Десятки компьютеров меньшего размера лучше, чем один большой компьютер. Но насколько это правда? Давайте посмотрим на цены на экземпляры Azure Dv5 (Париж) и AWS m5 (Париж).
Тип инстанса vCPU (ядер) Память (ГБ) Цена за час ($) m5.large 2 8 0,112 D2v5 2 8 0,112 m5.xlarge 4 16 0,224 D4v5 4 16 0,224 m5.2xlarge 8 32 0,448 D8v5 8 32 0,448 m5.4xlarge 16 64 0,896 D16v5 16 64 0,896 m5.8xlarge 32 128 1,792 D32v5 32 128 1,792
Как видите, пока вы получаете одинаковое количество ядер и памяти, вы в конечном итоге будете платить одинаково, независимо от количества используемых вами различных узлов. Даже вопреки нашему общему правилу горизонтального масштабирования, с точки зрения производительности есть некоторые накладные расходы, которые теряются из-за необходимости передачи данных между узлами внутри кластера. Забавным примечанием является то, что вы можете точно увидеть, как Microsoft и Amazon соотносят свои цены.
Так что же вы получите, разделив вашу рабочую нагрузку на несколько узлов? Ответ здесь — распараллеливание. Если у вас есть рабочая нагрузка, которую можно распараллелить, вы можете масштабировать ее и запускать на нескольких узлах. Таким образом, работа выполняется быстрее, что, вероятно, является тем, к чему вы стремитесь.
Так что чисто теоретически — без учета продолжительности ваших рабочих нагрузок с данными — масштабирование будет более рентабельным, чем масштабирование. Конечно, есть и другие факторы, которые следует учитывать. Масштабирование и перенос узлов в кластер или из него гораздо более гибкие, чем масштабирование вверх и вниз по одному узлу.
Джордан Тигани, генеральный директор MotherDuck, написал длинный пост в блоге о масштабировании и масштабировании.
Зачем вам использовать DuckDB (повторно)?
Как один узел с DuckDB может быть быстрее, чем несколько узлов с проверенной технологией, такой как Apache Spark? Ответ: DuckDB работает внутри процесса.
Когда ваш компьютер взаимодействует с базой данных, он использует сокеты. Вы можете думать о них как о двух людях, использующих рации. Вы можете говорить, говорить то, что хотите сказать, а другой человек слушает. Другой человек отвечает, и вы слушаете. Представьте, насколько быстрее вы сможете общаться, если просто будете стоять рядом с этим человеком. Нет «Over» или нажатия кнопок, когда вы хотите говорить. Вы просто говорите то, что должны сказать, и, глядя на выражение лица, вы знаете, когда другой человек собирается ответить. Общение просто происходит гораздо более плавно и быстро.
То же самое касается использования сокетов по сравнению с внутрипроцессным взаимодействием. DuckDB может использовать ту же память компьютера, что и процесс, с которым он взаимодействует, и часто ему даже не нужно перемещать данные. Пропускная способность ограничена только скоростью дорожек на материнской плате между ЦП и ОЗУ, которая значительно увеличилась за последние годы, особенно в М-чипах Apple.
Представляем: MotherDuck
Итак, если принять во внимание вышеизложенное, работать с DuckDB (в облаке) становится намного интереснее. В разделе Зачем вам использовать DuckDB? я писал, что вы можете управлять DuckDB в облаке «без компромиссов». Без компромиссов? Ну, почти. Если вы отправитесь в приключение, как описано выше, вы можете столкнуться с некоторыми сложностями. DuckDB отлично работает в качестве локального хранилища данных, но совместное использование ваших данных в облаке или выполнение преобразований в контролируемой среде может быть непростой задачей.
Это именно то, что пытается решить MotherDuck.
MotherDuck — это управляемая служба DuckDB в облаке. Короче говоря, как пользователь DuckDB, вы можете легко подключиться к MotherDuck, чтобы улучшить локальную работу с DuckDB с помощью облачной управляемости, постоянства, масштабирования, совместного использования и производительности.
Утенки MotherDuck — это экземпляры DuckDB с одним узлом, которые обрабатывают ваши данные. Что MotherDuck делает очень хорошо, так это бесшовную интеграцию между вашей локальной средой и облаком. Огромная мощь DuckDB во многом зависит от простоты ее использования и простоты начала работы. Они проделали большую работу, чтобы сохранить этот опыт нетронутым.
Ниже приведены инструкции по установке MotherDuck в вашей среде DuckDB.
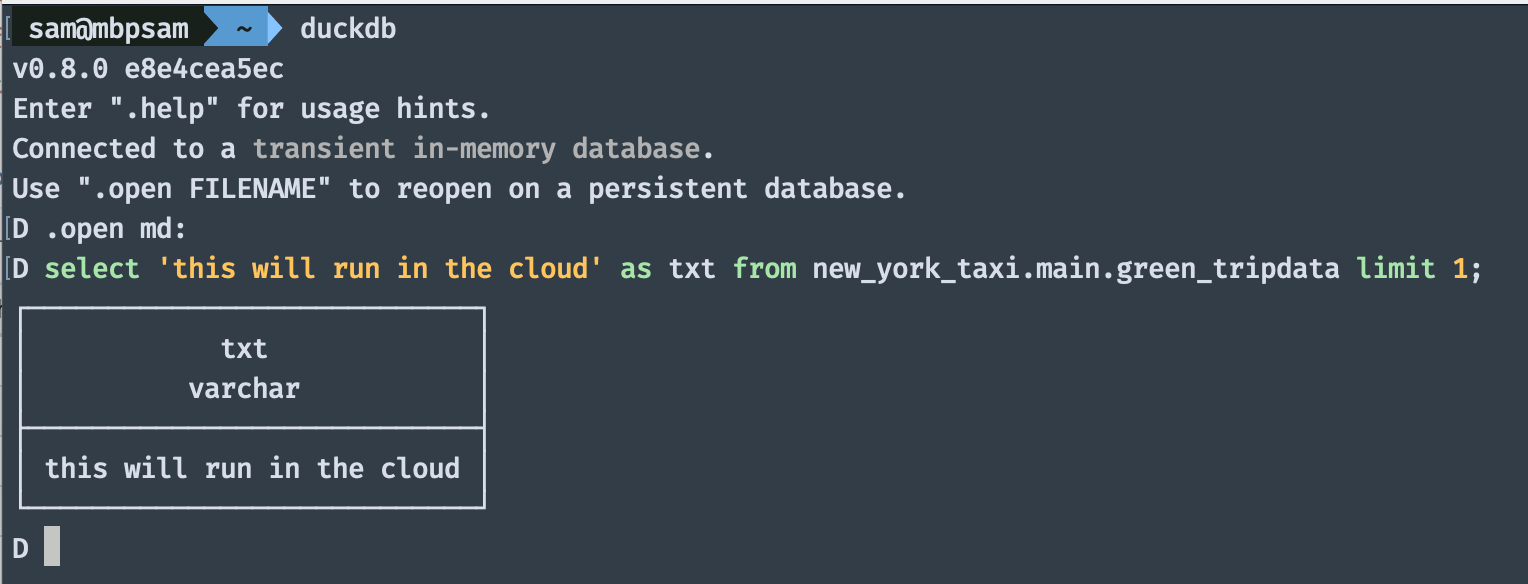
- Запустите этот SQL-запрос:
.open md:
Вот и все. Когда я сам попробовал MotherDuck, меня впечатлила простота использования. Строка выше открывает поток аутентификации в вашем браузере, и, конечно же, есть способ предоставить токен даже для автоматизации этого шага.
MotherDuck — хранилище данных

Команда MotherDuck состоит из бывших сотрудников Databricks, Snowflake, дизайнеров Google BigQuery и других. Что, если вам не нужен распределенный кластер с несколькими узлами для обработки ваших данных? Что делать, если у вас нет терабайт данных для обработки? Может быть, все ваши данные даже умещаются в памяти одного компьютера? В наши дни отдельные облачные узлы могут масштабироваться до десятков ГБ памяти. И если вы разумно обрабатываете свои данные, вам, вероятно, даже не придется загружать их все одновременно.
MotherDuck работает полностью без сервера. Пока тестировал альфа-версию, я так и не настроил ничего, связанного с производительностью. Запросы выполнялись мгновенно, и никакой подготовки не требовалось. Цена еще не объявлена, но я ожидаю, что она будет зависеть от времени выполнения ваших запросов и объема данных, которые вы храните в MotherDuck.
Гибридные запросы
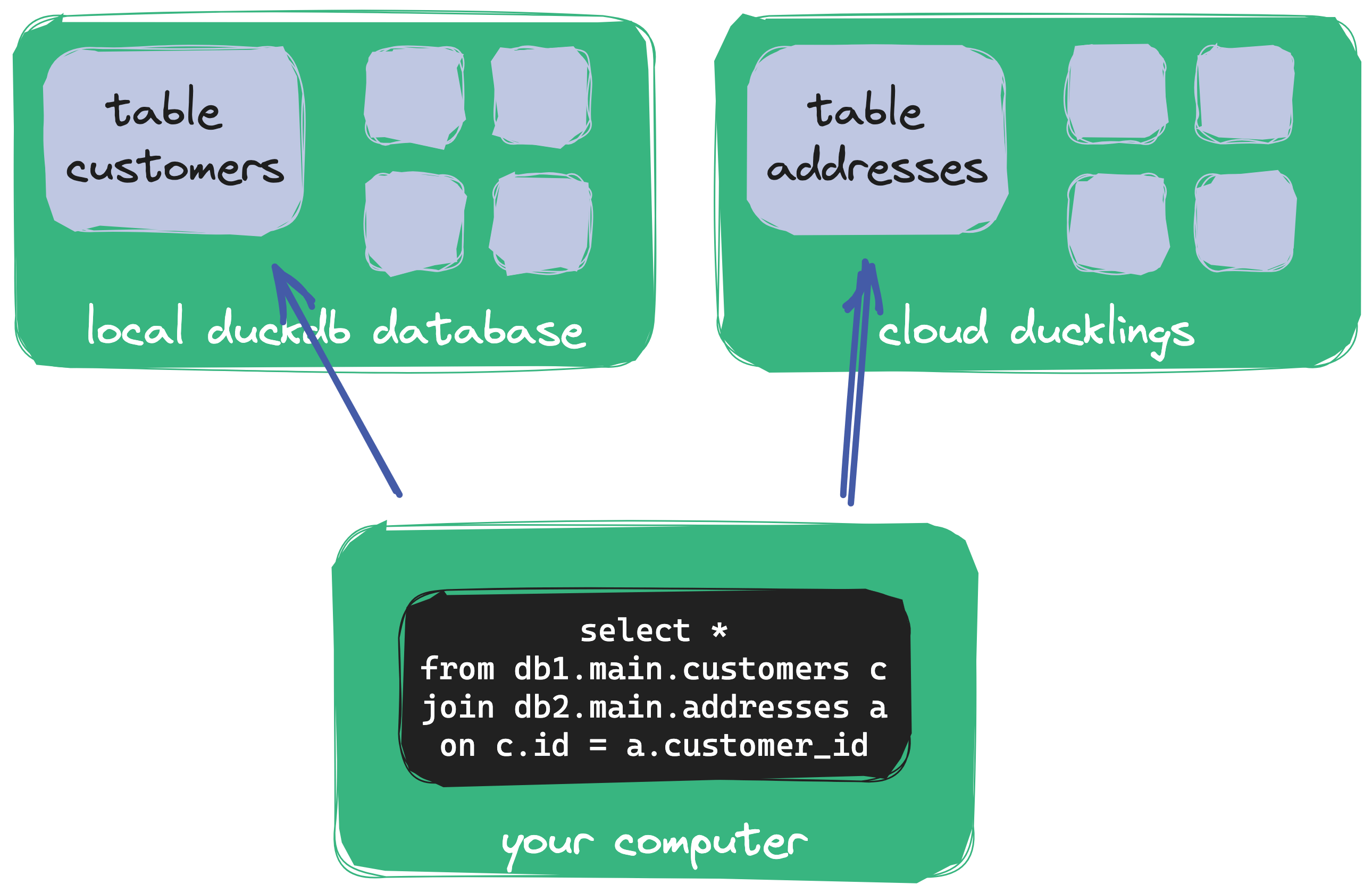
Одним из вариантов использования DuckDB является то, что вы можете создавать свои модели данных (dbt?) локально, запускать их в DuckDB и, когда вы будете довольны, отправлять их в промежуточную или производственную среду, где они работают с вашим фактическим хранилищем данных (например, Снежинка). Локальное использование DuckDB также проявляется в таких сценариях, как Modern-Data-Stack-in-a-box, где вы можете локально запускать всю свою платформу данных.
MotherDuck поддерживает этот подход. Запросы в DuckDB могут использовать комбинацию данных в облаке и локальных данных. Даже один запрос может соединить локально сохраненный файл паркета с облачной таблицей в MotherDuck. Это может включить новые рабочие процессы разработчиков, и я вижу возможности для использования этого в процессах извлечения и загрузки.
Все это делает MotherDuck отличным выбором в качестве следующего хранилища данных.
MotherDuck может стать идеальным хранилищем данных для пользователей, которым не нужен масштаб Snowflake или широкие возможности Databricks.
MotherDuck преобразует ваши данные
Нет ничего, что MotherDuck делает больше с точки зрения преобразования данных, чем то, на что уже была способна DuckDB. Вы можете использовать SQL, Python, Go или Java для преобразования данных с помощью MotherDuck. Некоторые дополнительные полезные функции — это сохранение учетных данных в облачном хранилище, таком как S3, поэтому вам не нужно помещать их в свой код.
MotherDuck также создал пользовательский интерфейс для своей платформы, в котором вы можете выполнять запросы и мгновенно получать результаты. Этот опыт будет очень знаком пользователям, которые раньше работали с ноутбуками Jupyter. Они работают над расширением этого с помощью таких функций, как встроенные графики, такие как гистограммы. Взаимодействовать с MotherDuck можно любым способом, которым вы сегодня пользуетесь DuckDB, или через их браузер.
MotherDuck как инструмент извлечения и загрузки
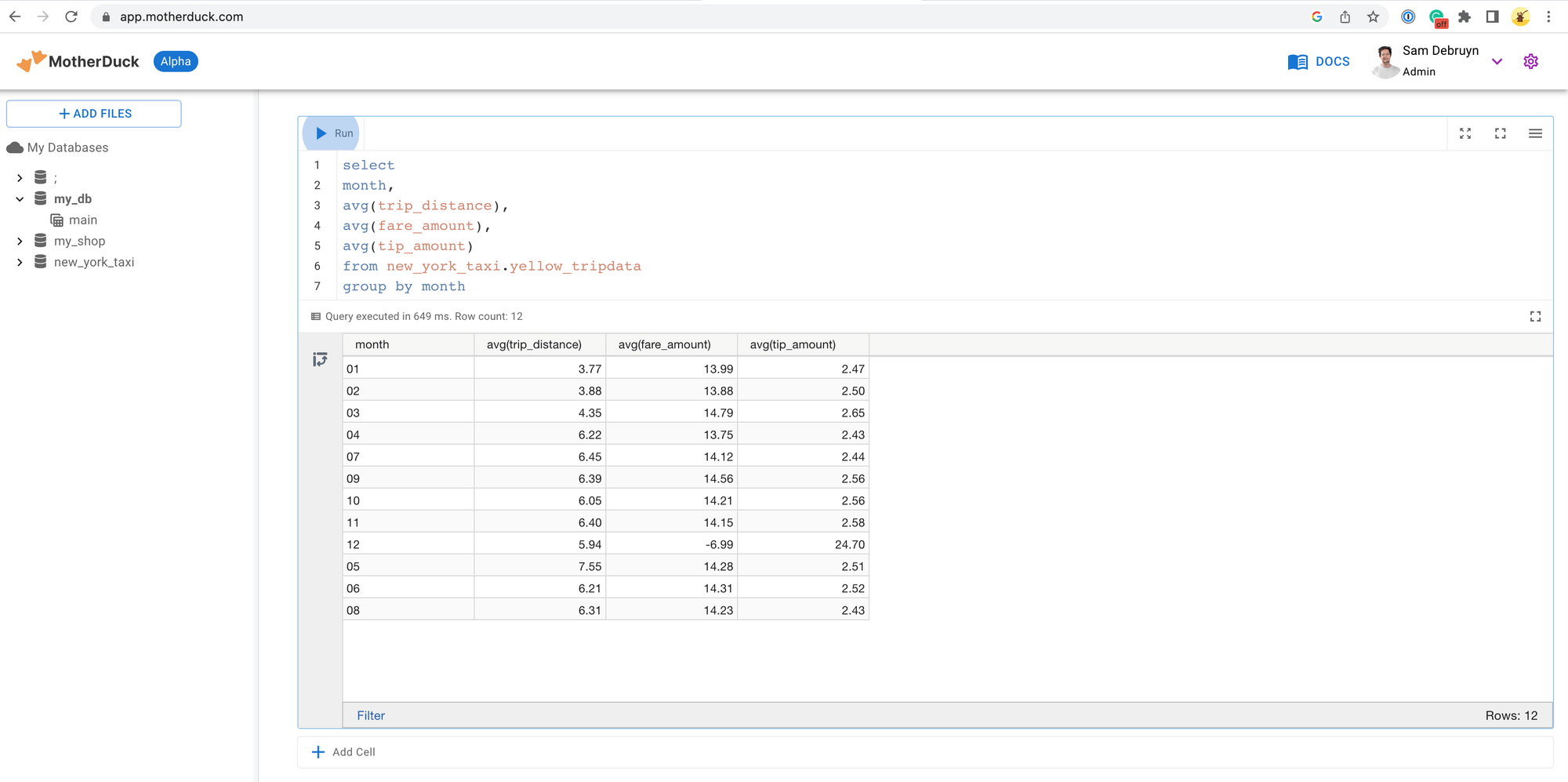
MotherDuck поддерживает популярные операторы CTAS (Create Table As Select), обычно используемые в OLAP для загрузки и преобразования данных. В этом случае данные могут поступать из любого местоположения S3. Цель здесь — добавить поддержку других облачных провайдеров. Я загрузил 1,5 ГБ данных такси Нью-Йорка за 29 секунд с помощью одной строки SQL.
CREATE DATABASE new_york_taxi;
USE new_york_taxi;
CREATE TABLE yellow_tripdata AS
SELECT *
FROM 's3://datarootsio/new_york_taxi/yellow_tripdata/**/*.parquet';Утенок даже сам разобрался со схемой разбиения. Эта простота использования замечательна и довольно редка.
Передача данных с локального компьютера в облако также может быть такой же простой, как запуск CTAS, выбирающего данные из локального источника данных.
CREATE DATABASE my_shop;
USE my_shop;
CREATE TABLE customers AS
SELECT *
FROM read_csv_auto('a/local/folder/on/my/machine/raw_customers.csv', header=true);Объедините это со сканером Postgres DuckDB или с его способностью загружать любой объект Pandas DataFrame, Polars DataFrame или PyArrow, и вы получите мощный инструмент для загрузки данных в облако.
MotherDuck для обмена данными
Окончательный синтаксис SQL еще предстоит разработать, но, запустив хранимую процедуру md_create_database_share, вы уже можете создавать общие базы данных, которые можно отправлять коллегам, клиентам или другим заинтересованным сторонам. Это простой способ обмена данными, не беспокоясь об инфраструктуре.
Предостережения
Это гораздо больше, чем то, что я описал выше, поэтому я бы порекомендовал вам попробовать. MotherDuck все еще находится в стадии бета-тестирования, и некоторые функции отсутствуют. Обязательно прочитайте документацию или свяжитесь с нами, если у вас возникнут вопросы.
Твой партнер
Как ваш партнер в области данных, Dataroots уже будет учитывать такие технологии, как MotherDuck или DuckDB, в наших предложениях и технических проектах.
Мы сотрудничали с MotherDuck при запуске их бета-версии и готовы помочь вам спроектировать и построить платформу данных, точно соответствующую вашим потребностям.
Вам также может понравиться
